Prompt Tuning & Delta Tuning
- 为了使PLM能够在下游任务中取得良好的性能,需要进行微调。但是呢?不同类型的下游任务特性不同,导致需要考虑怎么针对PLM进行微调。这里面就包含如何将训练数据转化为适合任务的表示形式传给PLM,怎么选取损失函数等问题。
- 同时由于PLM的性能和参数量有比较大的关系,要微调巨大参数量的PLM是很烧显卡的,有时甚至无法微调大模型。
- 那么就需要有一个相对统一的范式,能够针对所有的下游NLP任务 => T5模型提出
Seq2Seq,将所有的NLP任务统一为使用序列到序列的模式,即encoder输入是一个句子,decoder输出也是一个句子,这就避免了下游任务输入输出种类的多样性。 - 针对参数量过大的问题,GPT3就提出prompt的概念。即不微调模型参数,而是通过zero/few-shot的方式进行模型的引导。
越来越大的模型 和 越来越多,复杂的下游任务,就决定了微调全参PLM这个事情已经不现实了,所以NLP的研究人员又研究出了两种解决问题的方法:Prompt Tuning & Delta Tuning
prompt tuning:使用prompt-learning的方法来增强PLM的few-shot学习能力
delta tuning:微调部分模型参数以达成和微调全参数相同的效果
Prompt Tuning
在传统的微调PLM的观念中,存在一个gap。比如下图左边是BERT模型,它在做的是在理解输入的句子,然后预测MASK部分应该会是什么单词。但是呢下游任务是情感分类,也就是预测正向或者负向。
他们之间工作目标是不同的,那么就需要设计一个分类器添加到PLM上以适配情感分类任务。此外他们的工作原理不同,那么PLM没有经过分类这种训练,表现也难说。
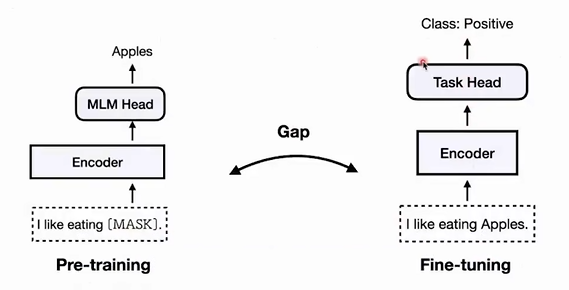
那怎么在不微调BERT模型的情况下,消除这个gap呢?
加入prompt,将情感分类任务转变为和BERT一样的预测单词的任务。然后根据输出的单词,在通过verbalizer转化成情感分类的结果。这样就消除了gap。他们通过语言模型做的事情是一样的
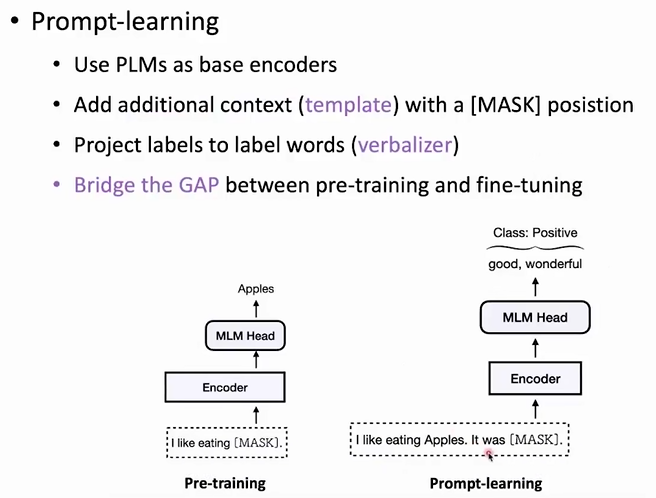
prompt-learning的需要考虑的因素
PLM的选择
针对不同的下游任务,选择合适的PLM才能增强性能
- Auto-regressive(GPT1-3, OPT)适合生成任务,适合训练超大参数量的模型,[MASK]放到句子最后
- Masked LM(BERT, RoBERTa)适合做理解任务,分类任务,[MASK]任意位置都可以
- Encoder-Decoder(T5,BART)
- 各个领域的PLM
Template的设计
- Manually Design,考虑任务特性人工设计,效果较好
- 针对一个下游任务设计多个prompt,然后让PLM针对多个prompt取加权平均,得到最终结果
- 设计结构化的prompt,比如key-value类型的。这样就可以提示PLM应该干什么,唤起预训练时相似的数据
- Auto Generation,让PLM自己生成prompt(基于这样一个思想:适合人的不一定适合机器)
- Textual or Continuous
Verbalizer(把标签映射为标签词的过程)
- Manually Design
- Expanding by External knowledge
Delta Tuning
什么是Delta Tuning
PLM模型的大部分参数不变,只改变其中的某一不分参数。就像下图中的,对于PLM本身固定,对于不同下游任务,训练不同的轻量Delta Objects。这个就是它能适配下游任务的关键。
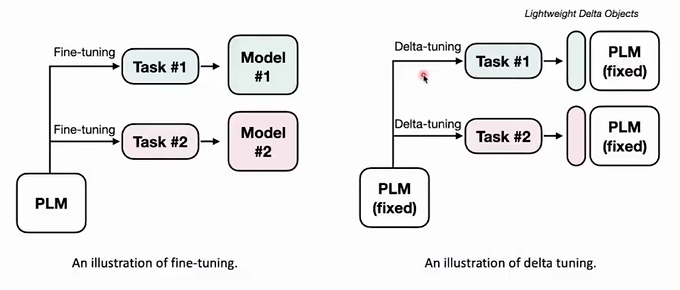
为什么Delta Tuning能够有效
PLM本身是经历过大量语料库训练的,所以具有大量的通用领域的知识。那么通过微调和下游任务相关的参数,实际上是在激发这些通用知识中和下游任务相关的那些知识。
但是呢,微调多少参数,激发出的能力上界和下界是多少,目前还没有研究做出确定的结论。
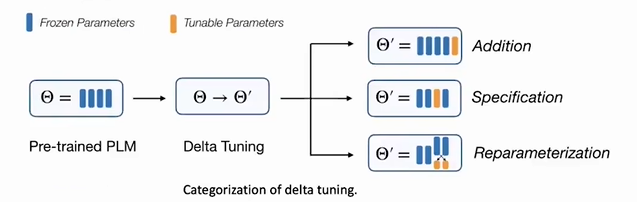
Delta Tuning的三种范式
- Addition-based:添加一个额外的参数模块到PLM中
- Specification-based:修改PLM中的指定参数模块,其他不动
- Reparameterization-based:通过一个低秩矩阵将现有的参数变化为一个参数高效的形式
Addition-based
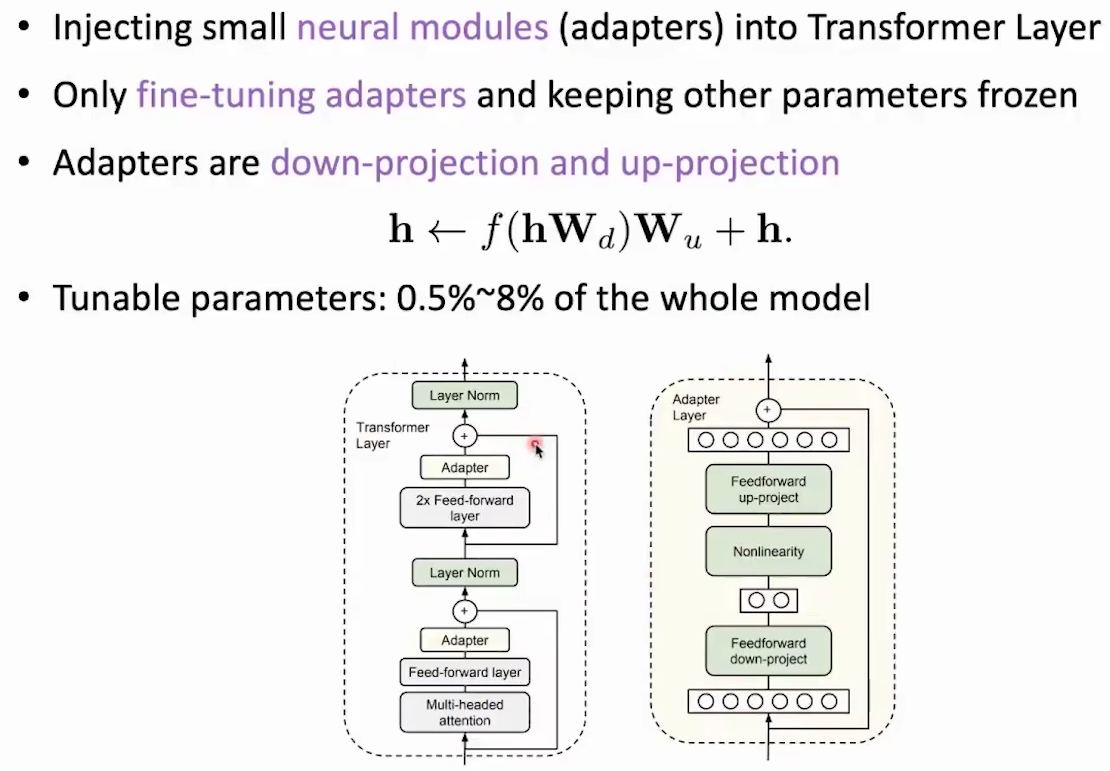
Adapter-tuning
原论文:[1902.00751] Parameter-Efficient Transfer Learning for NLP
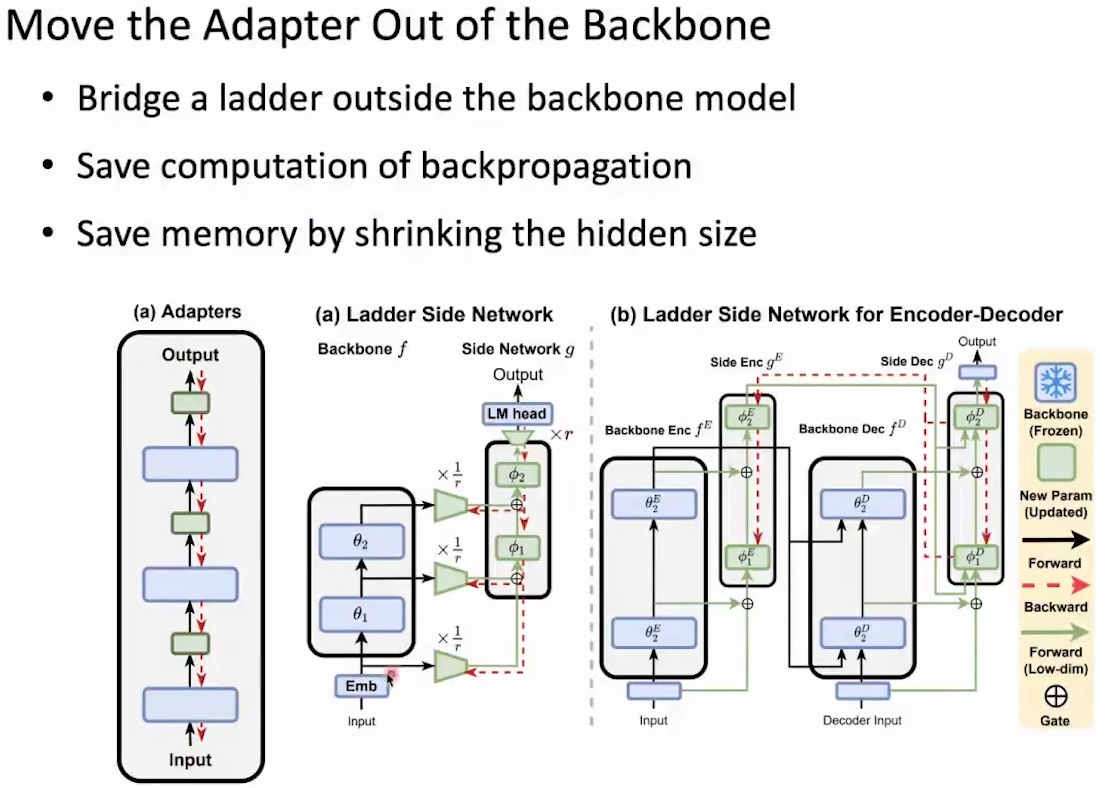
原论文:[2206.06522] LST: Ladder Side-Tuning for Parameter and Memory Efficient Transfer Learning
Prefix-Tuning
原论文:[2101.00190] Prefix-Tuning: Optimizing Continuous Prompts for Generation

Specification-based

Reparameterization-based
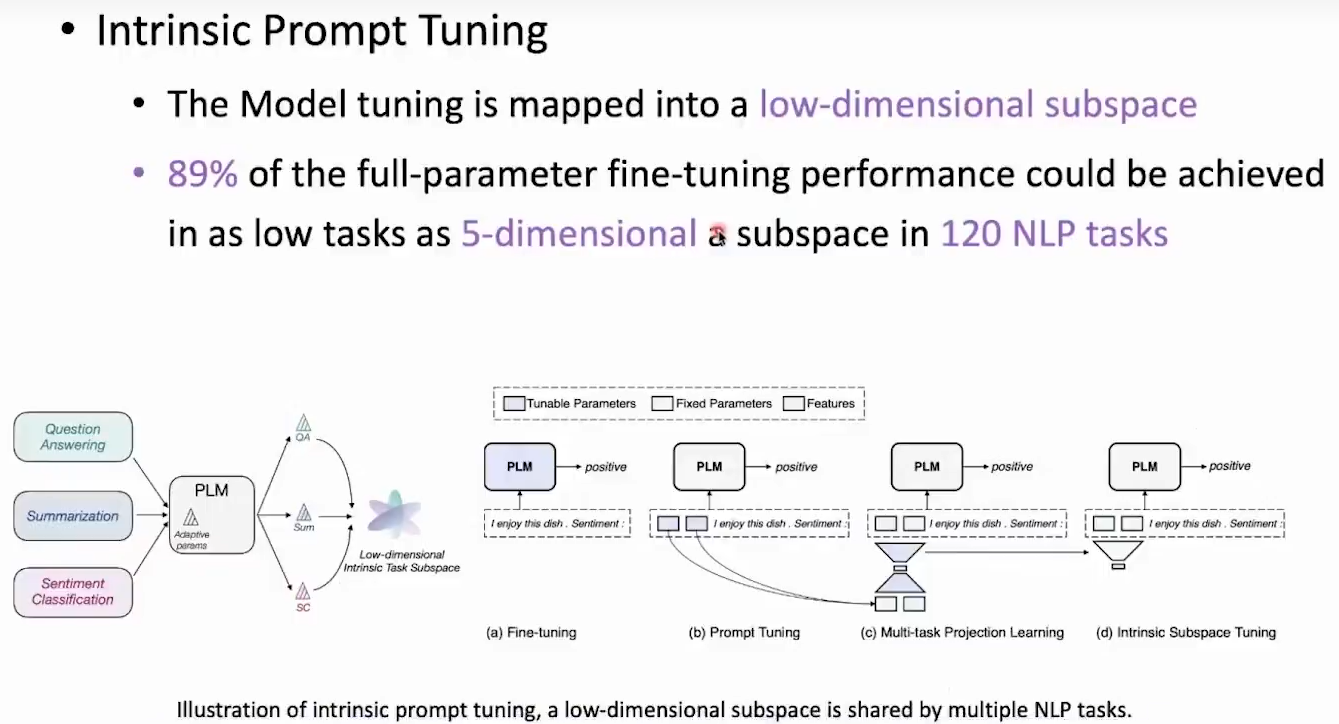
重参数化的方法都基于一个假设:模型的微调都可以通过改变小部分参数实现
原论文:[2110.07867v1] Exploring Low-dimensional Intrinsic Task Subspace via Prompt Tuning
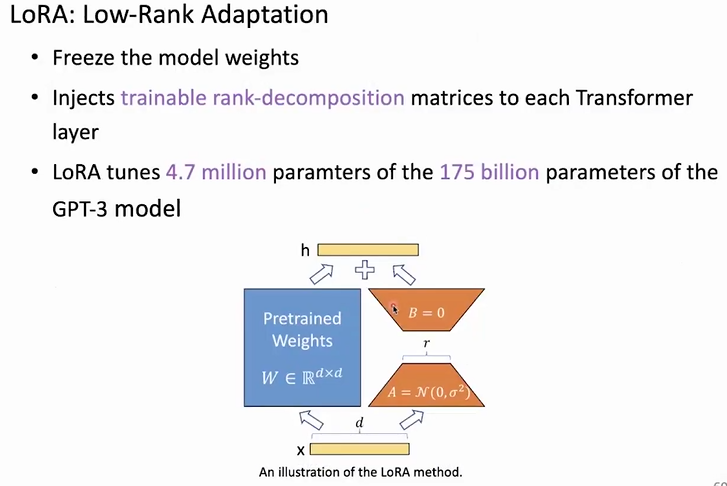
原论文:[2106.09685] LoRA: Low-Rank Adaptation of Large Language Models
Efficient Training
参考综述论文:[2407.20018] Efficient Training of Large Language Models on Distributed Infrastructures: A Survey
PLM越来越大,所带来的不仅是模型性能的提升,也带来的训练成本的提升(训练代码更复杂,训练时长更长,训练需要的显卡更多),我们希望训练模型可以更加简单、快捷、便宜。所以就需要一些方法支持我们的高效计算和模型压缩。
那么怎么达到这样的目标呢?第一步就要分析GPU到底存储了什么内容,第二步是考虑怎么使得多个GPU之间的合作更加高效。
显卡的显存组成
CPU和GPU的合作方式是:CPU告知GPU要做什么,GPU只负责实现计算任务

-
模型参数
-
反向传播过程中的梯度信息
-
为支持正向传播和方向传播所需要存储的中间信息

-
为支持参数优化所需要的优化器带来的额外信息

数据并行(Data Parallel)
核心思想是将训练数据等分到每张可用显卡中进行并行训练,然后取多张训练的平均梯度更新参数
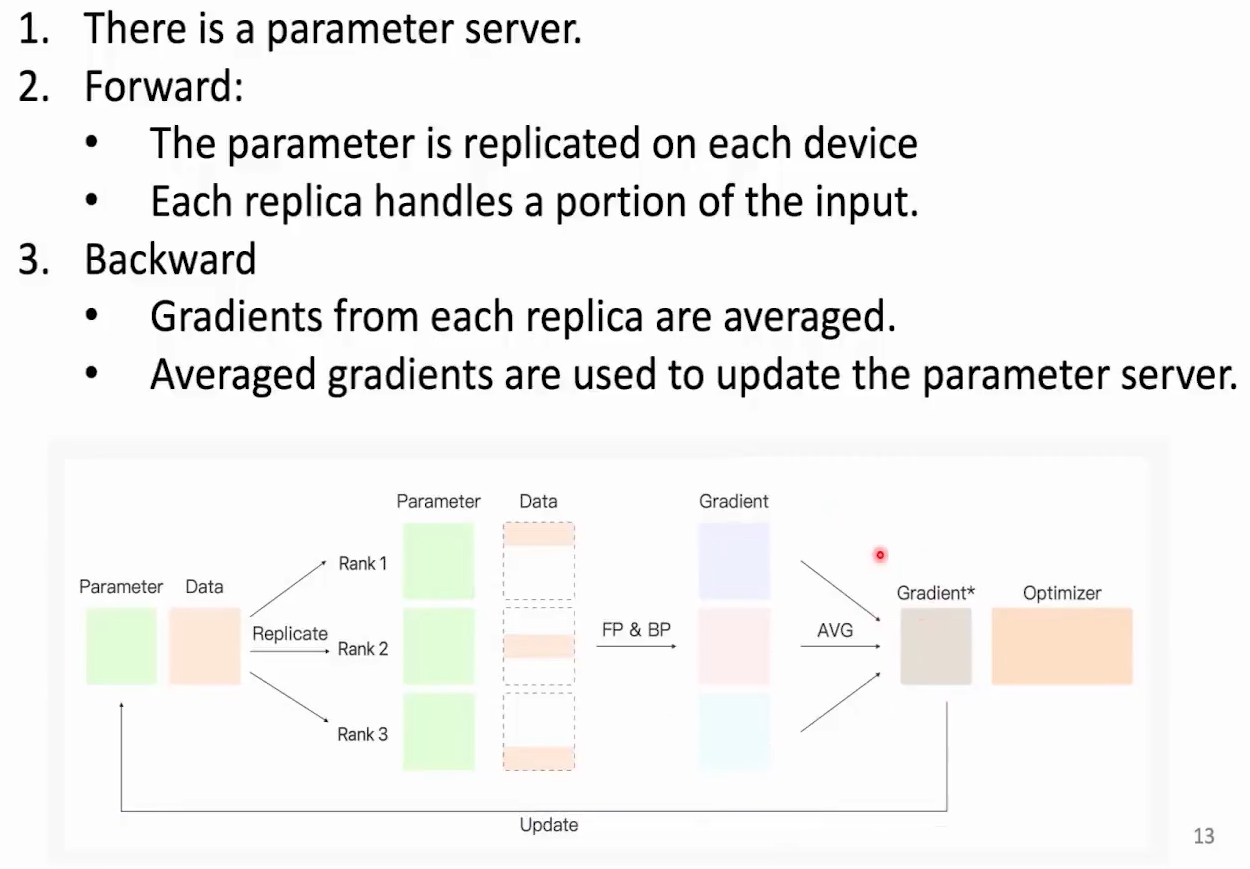
显卡之间的操作算子
-
broadcast:广播算子,将一张显卡的数据,复制到所有显卡上
-
reduce:规约算子,将所有显卡的数据规约(求和,求平均等),然后传输到指定显卡
-
all reduce:全规约算子,将所有显卡的数据规约(求和,求平均等),然后传输到所有显卡上
-
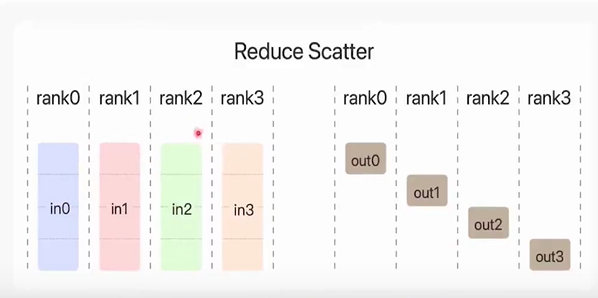
reduce scatter:规约散播算子,将所有显卡的数据规约(求和,求平均等),然后每张显卡只得到规约结果的一部分参数
-
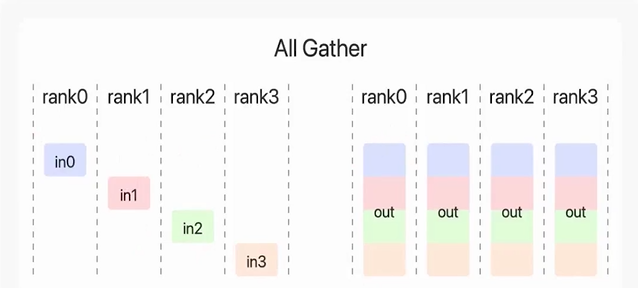
all gather:收集算子,将所有显卡的结果拼接,复制到所有显卡上
通过分布式数据并行优化训练过程
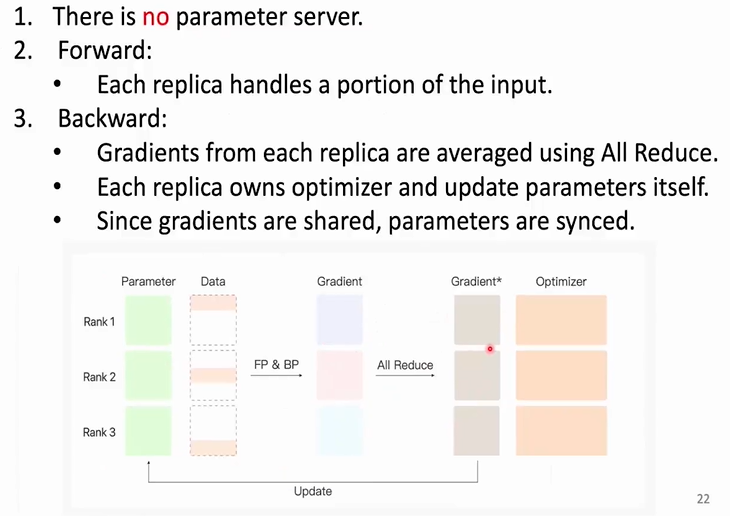
通过分布式数据并行是可以减轻显卡存储压力的。由于将训练数据等分,那么n张显卡中保存的中间计算数据就变成了1/n
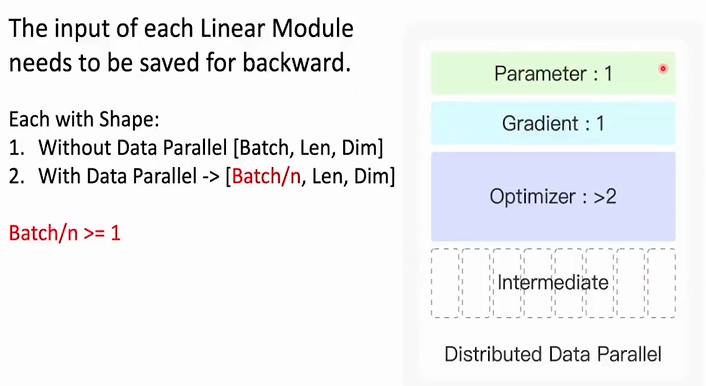
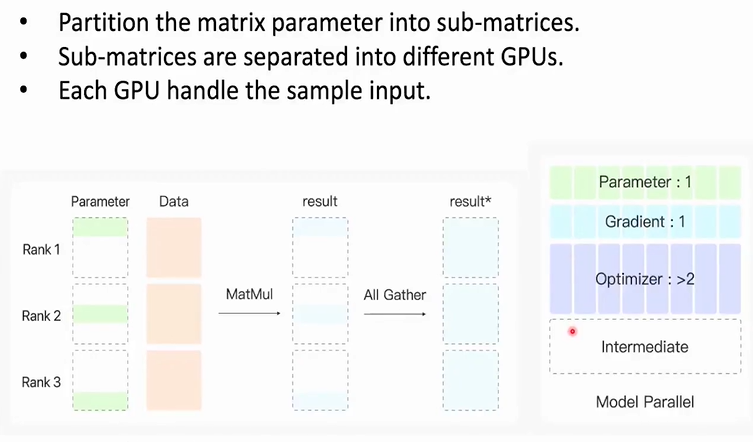
模型并行(Model Parallel)
核心思想是每张显卡中只放置模型的一部分参数,所有数据都只训练这一部分参数,由于矩阵乘法的性质,这种参数更新方式是可行的。对显卡的优化也表现在参数,梯度,优化器部分的数据量都变为原来的1/ n
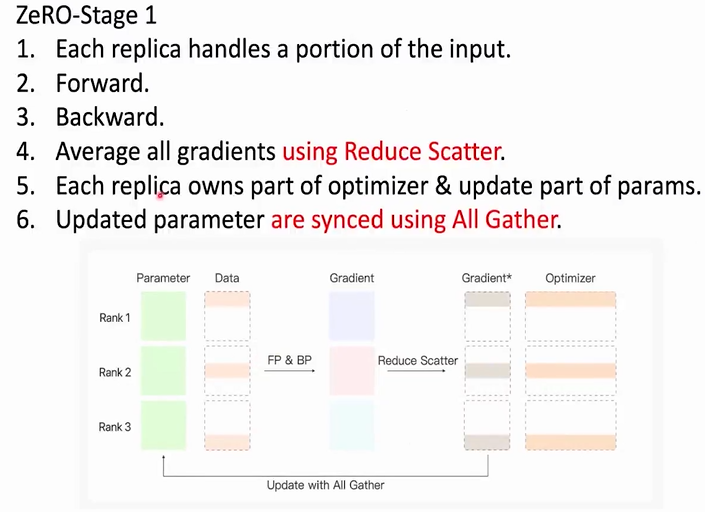
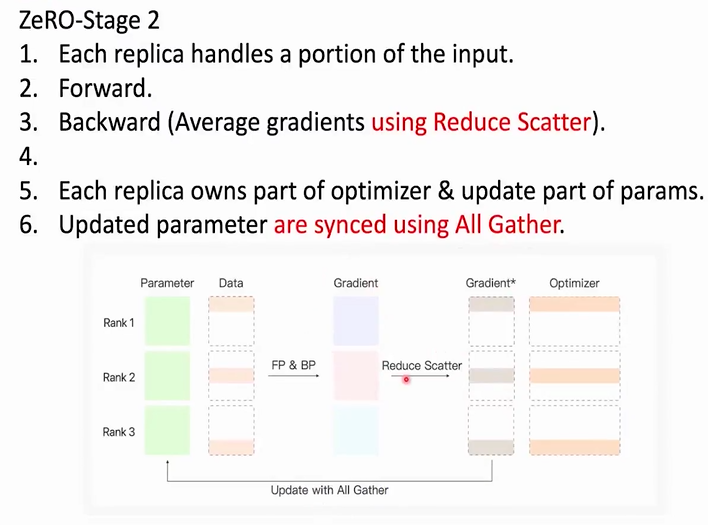
ZeRo(Zero Redundancy Optimizer)


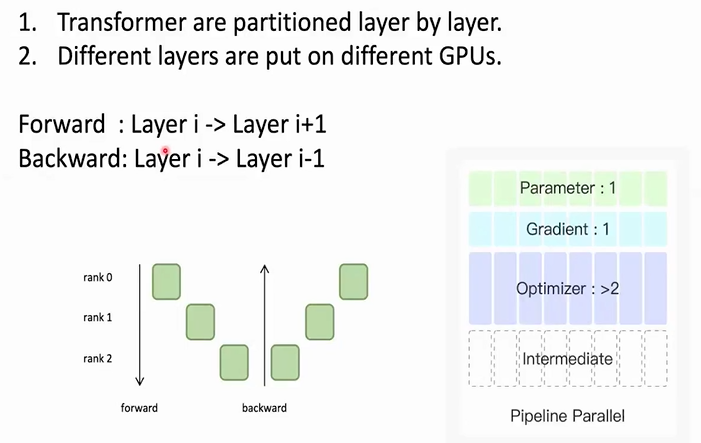
流水线并行(pipeline parallel)
将transformer的每一层放在一张显卡上,没有加速训练,只是减轻了显存压力
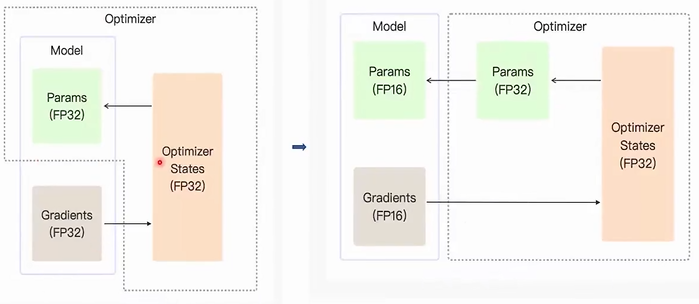
混合精度训练
核心思想是合理(避免数据下溢导致精度丢失)使用FP16精度的数据存储形式来加速训练

由于权重的更新约为梯度*学习率,所以在优化器更新中使用FP32来存储,模型参数和梯度本身使用FP16也不会溢出
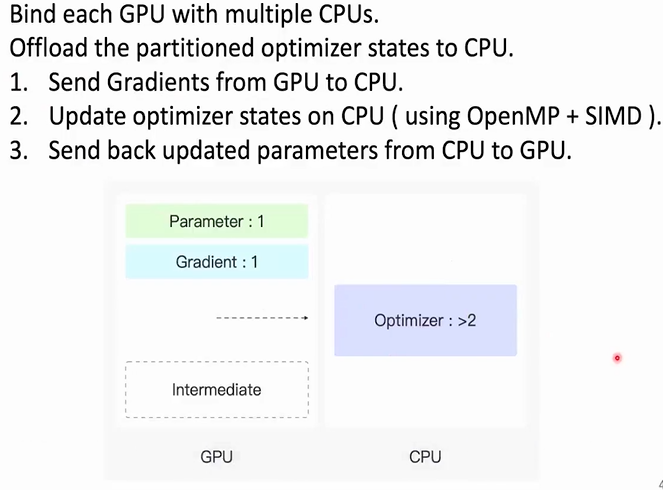
Offloading
为了进一步释放显卡的占用,Offloading选择将优化器的计算存储内容移到CPU上
那么CPU会成为计算速度的瓶颈吗?不会,因为经过了ZeRo3优化后,每张GPU上的数据量已经被缩小了n倍;同时我们再将一张GPU对应多张CPU,就可以保证训练速度了
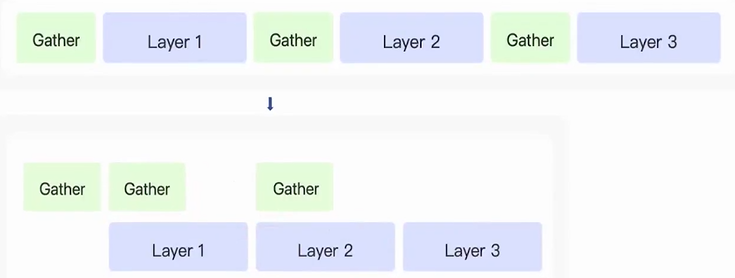
Overlapping
前向传播中,多层之间的参数是没有依赖关系的,在ZeRo3模式下,可以进行异步获取
也就是在Layer1层进行前向传播计算时,Layer2层的参数通过Gather算子计算
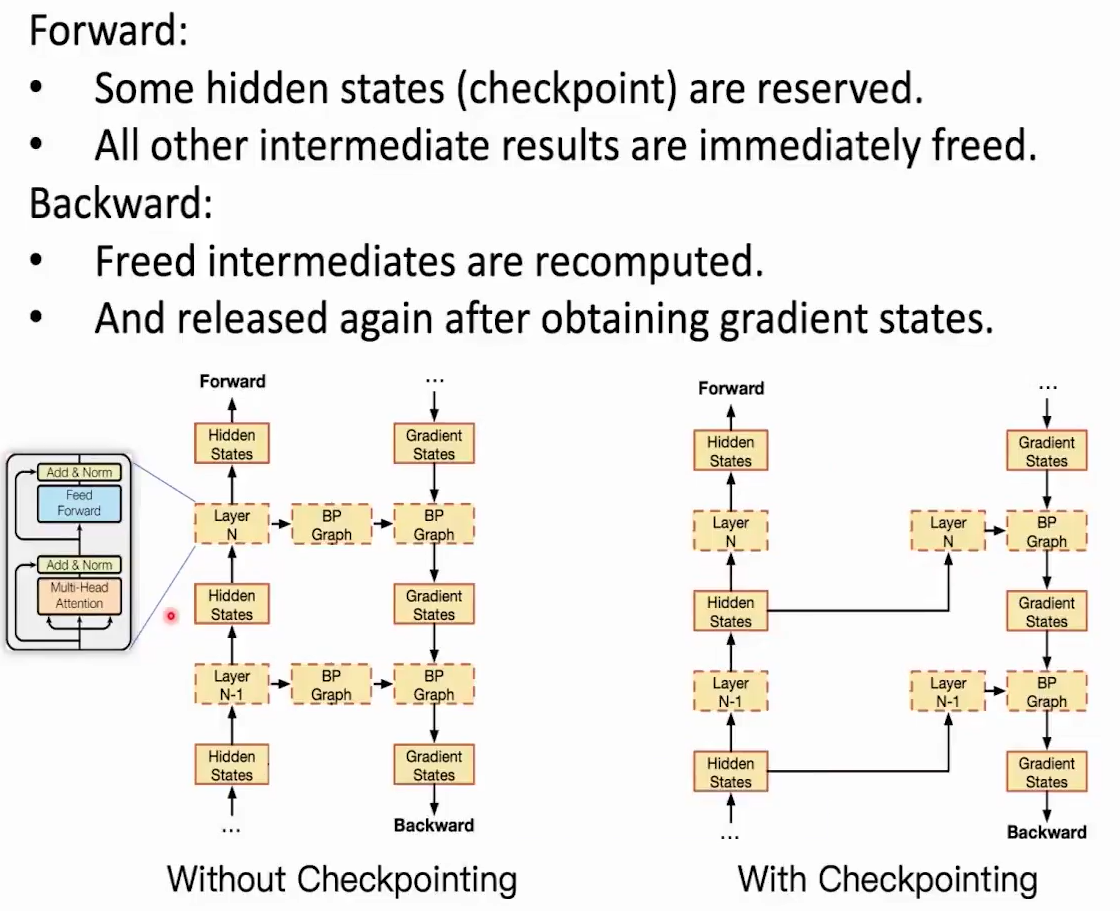
Checkpointing
为了支持模型的反向传播,是需要在GPU中存储前向传播中的所有隐藏层状态信息的。
在transformer架构中,我们可以不保存所有的前向传播信息,只保留输入信息。当反向传播需要隐藏层状态时,我们假装进行一个前向传播,通过输入信息获得隐藏层状态,从而进行反向传播。这样GPU中就只需要保存每一层的输入信息了。
Model Compression
基于 PyTorch 的模型瘦身三部曲:量化、剪枝和蒸馏,让模型更短小精悍!_pytorch 模型蒸馏-CSDN博客
知识蒸馏
模型剪枝
模型量化
其他压缩方法
深度学习模型压缩与加速技术(四):参数共享_模型压缩 参数共享-CSDN博客
Big-Model-based Text understanding and generation
自然语言在下游有两种类型的任务:自然语言理解 与 自然语言生成
具体来说:信息检索需要自然语言理解;文本生成需要自然语言生成;机器问答则需要综合两种。
信息检索
定义:信息检索要求在给定的用户query下,查询出与query相关性程度高的几篇文档
所以信息检索任务的评价指标都是基于如何描述相关性
信息检索的实现方式可以是基于词频统计、神经网络、PLM等