NLP & Big Model Basics(GPU server,Linux,Bash,Conda,…)
什么是自然语言处理
NLP是让计算机能够理解人类语言的技术,或者说是手段。语言是人类智能的重要表现形式,理解人类语言就是计算机涉足人类智能的重要突破。
图灵测试:通过对话的形式判断对方是人类还是机器。这是检测计算机是否具备理解人类语言,生成人类语言的重要手段(形式上就是让机器模仿人类,如果模仿的很像,那就具备人类智能,所以图灵测试最开始也叫Imitation Game,模仿游戏)
一篇关于NLP的综述,发表于science:253 261..266
自然语言处理的任务和应用
基础任务:句子信息的识别
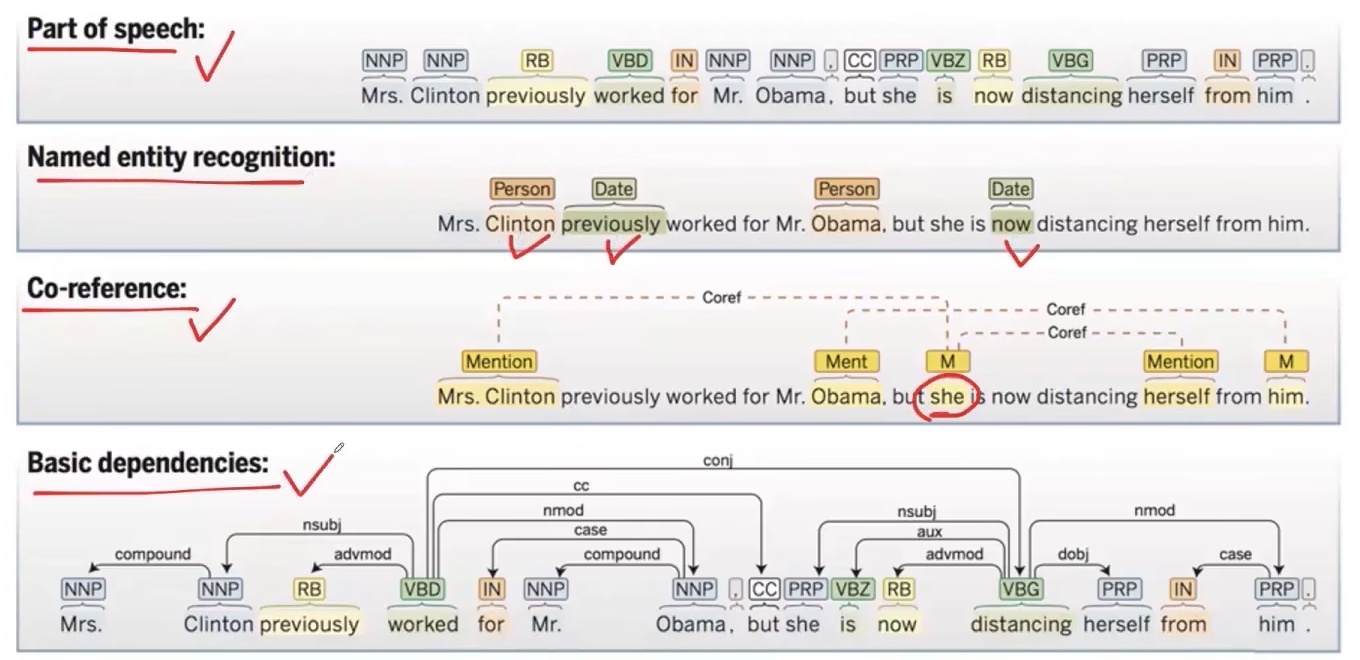
- 词性标注(part of speech):一个句子中每个词的词性(名词,动词…)标注出来
- 命名实体识别(named entity recognition):寻找出句子中哪些词代表现实世界中的实体(人名,地名,日期…)
- 共指消解(co-reference):判别出句子中的代词指代句子中的哪个实体
- 依赖识别(basic dependencies):一个句子的多个词之间在语言学上是有各种依赖关系的,识别出来
- 这些任务都是中英文共有的,但是中文呢还需要一步:中文的自动分词(就是在中文句子的词语之间打空格,变得和英文句子一样)
进阶应用
(1)搜索引擎
原理技术博客:
两个基本技术:
- 匹配用户查询:计算用户输入的查询和所有文档之间的相关度(计算相关度就需要NLP的技术)。 匹配在线广告:理解用户输入的查询,个性化推荐广告(搜索引擎的重要盈利手段)
- 排序匹配到的网页质量:属于数据挖掘和信息检索领域的问题,要分析网络结构,判断哪些节点是重要的
(2)知识图谱
原理技术博客:
技术应用:
- 知识图谱把世界中各个实体和他们之间的关系构建成一个图网络,用户查询时就把匹配到的实体和其结构化信息展示出来(这里就需要NLP的技术进行匹配)
- 知识图谱的构建是离不开搜索引擎的:利用搜索引擎获取信息,构建知识图谱。在利用知识图谱加强搜索引擎(大规模文本挖掘的数据处理也需要NLP技术,有一个技术是Machine Reading:自动阅读文本内容,挖掘出其中的结构化知识,补充进入知识图谱中)
(3)个人助手
- 实例:Siri,小爱同学之类的个人语音助手。
- 总体思路:理解人类语言代表的需求,执行接口实现需求,给与人类反馈
(4)机器翻译
(5)情感分类(sentiment analysis)和意见挖掘(opinion mining)
(6)社会科学交叉
词表示与语言模型
什么是词表示
- 词表示:将自然语言的词表示为计算机可以理解的形式
- 那怎么样成形式就认为计算机真正理解了词的意思呢?需要满足两种能力
- 词相似度计算(能推断出 旅馆和酒店 很相似)
- 推断多个词之间的关系(中国-北京 之间的关系 相当于 美国-华盛顿 之间的关系)
目前如何进行词表示:词嵌入
- 思路:将大规模语料库构建成一个低维稠密的向量空间,从大规模预料库中自动进行学习,然后将每个词构建成一个低维稠密的向量(也就落在向量空间中的某个位置)。
- 那么这个向量空间中向量的位置关系就很可能代表词在自然语言意义上的关系,这样就利用向量这一计算机可以处理的表示形式解决了自然语言中词汇的表示。
- 很有代表性的工作:Word2Vec
什么是语言模型
语言模型的重要能力:能根据前文推断下文,也代表理解了前文。
在计算机表示中需要完成两个工作:
- 计算一个词汇序列表示一个合乎逻辑的句子的概率
- 推断某个词是否可以接在一个词汇序列后方的概率

那如何完成这两个任务呢?我们需要基于一个语言学上的假设:一个词出现的概率只有它前面的词来决定

那这些词汇的概率怎么算呢?有很多的技术实现,目前性能较好的是基于神经网络语言模型。
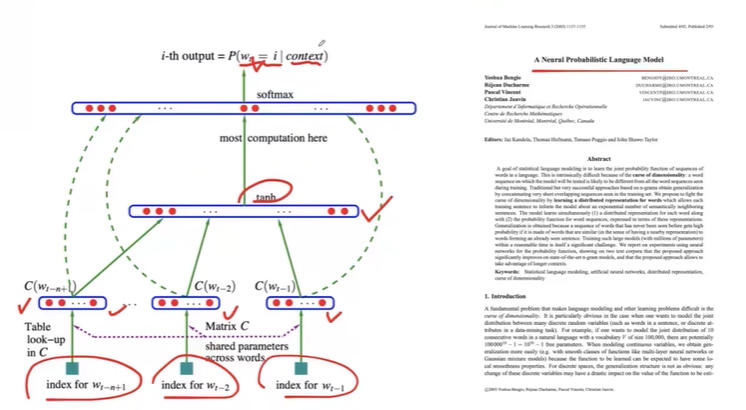
每个词表示都是使用词嵌入的方式,然后通过神经网络预测下一个词的概率。
使用神经网络进行建模就保证了可以通过大量语料库进行自动化的训练,也保证学习到了词汇之间的相似性
大语言模型基础
大语言模型是什么
LLM其实就是指参数量巨大的语言模型,本质上还是做根据上文推断下文词汇的工作。
通过构建大规模的神经网络,也就是参数量巨大之后,这些参数中存储了各类的现实世界的知识。因而在NLP的一些基准、任务中有不错的表现。(大规模参数引发了大规模训练语料库 + 并行计算方式减少训练时间)
大模型与传统的小规模语言模型不同的点还有一个就是zero/ few-shot学习的能力;即即使训练语料中没有某个任务相关的知识,但是给出少量的学习样本,大模型就能举一反三 / 举零反三进行这个任务。 (也就是参数所包含的知识量太大了,能够直接从零学习了)
大模型为什么有效的核心机理
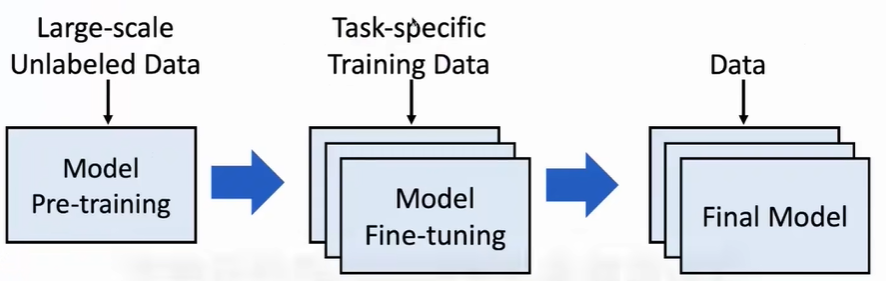
首先通过大规模未标注的预料数据,通过自监督的形式训练一个预训练模型(在通用任务上表现很好)
接着通过特定任务的训练数据微调模型,最终得到一个很好适配下游任务的特定模型
背后的原理就是迁移学习:将之前学习到的知识用到新任务中做适配
Neural Network Basics(PyTorch)
词向量(Word2Vec)
Word2Vec其实是一种方法,将词语转化成向量的方法(向量可以表示词语之间的关系),它是通过神经网络训练的。
Word2Vec的神经网络模型有两种:(左侧的是CBOW,右侧的是skip-gram)
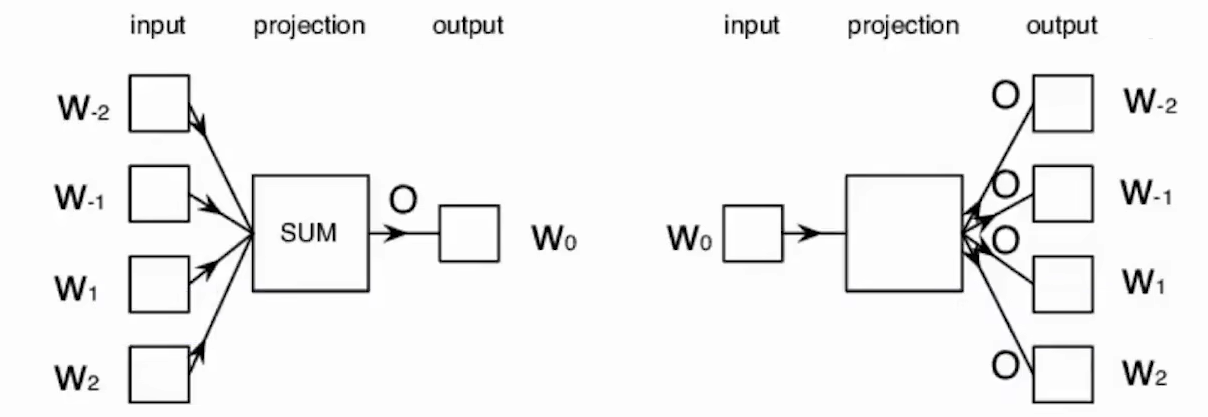
原理如下:
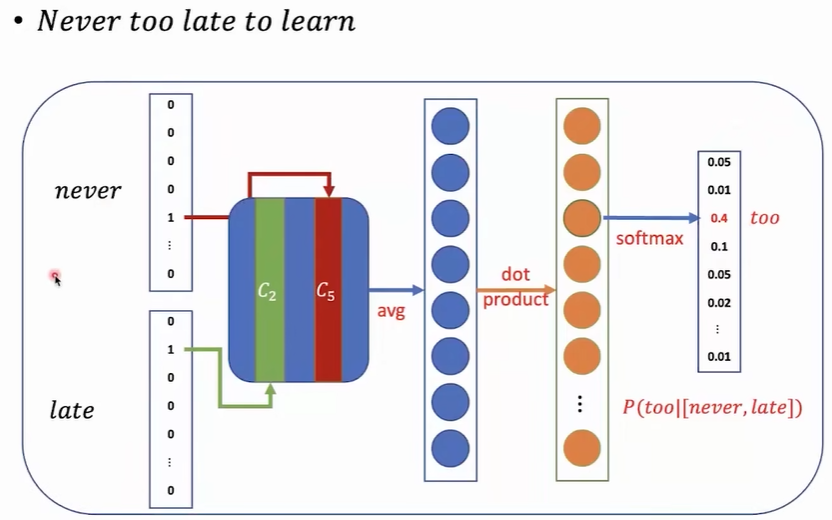
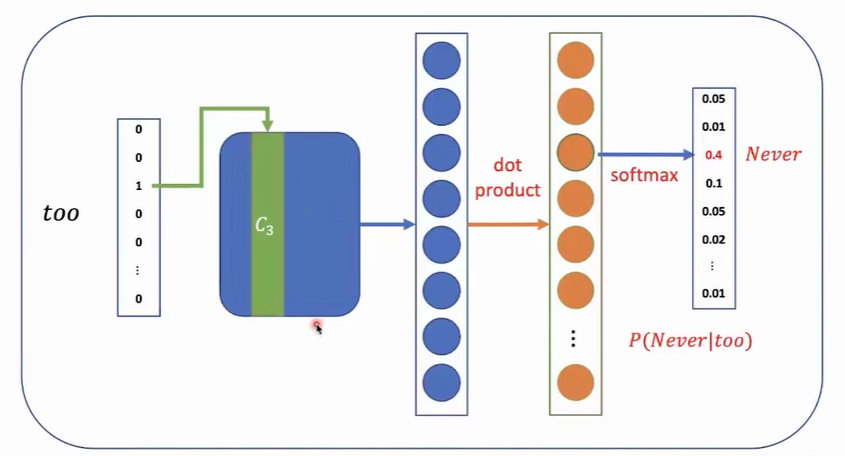
- Word2Vec使用固定大小的滑动窗口扫描句子,在滑动窗口中,中间的词称为target word,其他词称为context word。
- CBOW用于从context word预测target word(不考虑context word的次序,随便换任意两个context word的位置都是可以的)
- skip-gram用于从target word预测context word(神经网络一次预测多个输出不容易,所以简化为一次学习预测一个词)
- 还有一种非固定滑动窗口的word2vec,主要是考虑到离target word越近,有联系的概率越高这么一个原因。在训练过程中随机产生不同大小的滑动窗口进行学习
输入有滑动窗口的大小决定,最终设计为一个n分类问题。中间层就是词向量,最后一层是词表大小的向量
由于词表是非常大的,那么输出层会非常大(上万),这样反向传播和梯度下降会非常慢,所以提高计算效率。主要有两种方法:负采样和分层softmax。其中负采样就是拿一个较小的值,比如说5当成输出层的维度。其中一维是target word,其他维度则随机从词表选择。
循环神经网络(RNN)
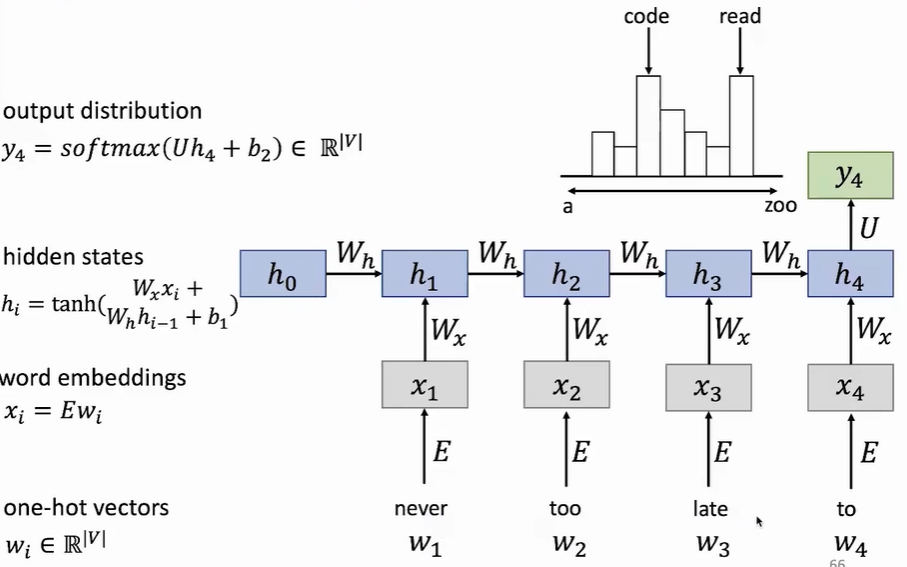
循环神经网络用于记忆序列数据,主要同一个循环网格复制多次组成。每个循环网格用于一个词汇的预测,那么RNN就可以代表一个任意长度的句子了。
由于后一个循环网格需要前一个循环网格的输出作为输入,那么就天然适合处理序列数据。但也面临两个问题:由于需要前一个网格的输出,所以计算只能是线性的,没法加速。如果句子太长,那么网格过多会导致梯度计算过于复杂(要考虑每个网格的输出),导致梯度爆炸或者消失。
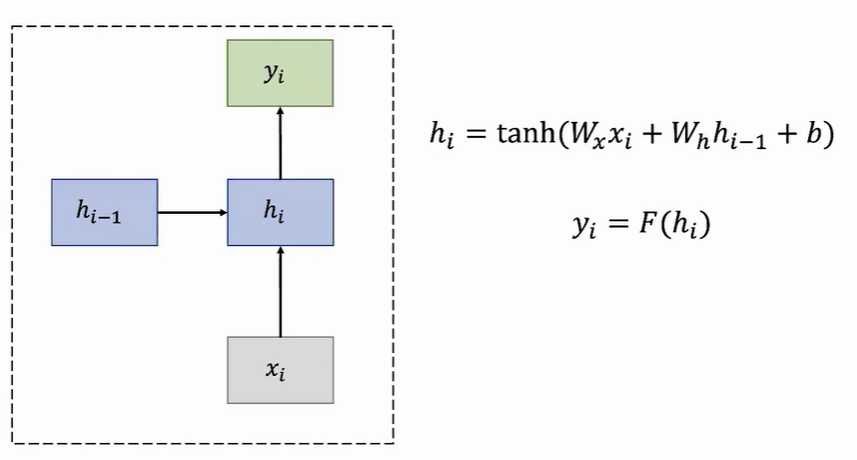
每个RNN单元的参数一致,实现参数贡献,大大减小了参数量
变体1:门控循环单元GRU
GRU的作用是控制前一个RNN单元信息有多少传入下一个RNN单元中。主要有两种门:更新门 + 重置门

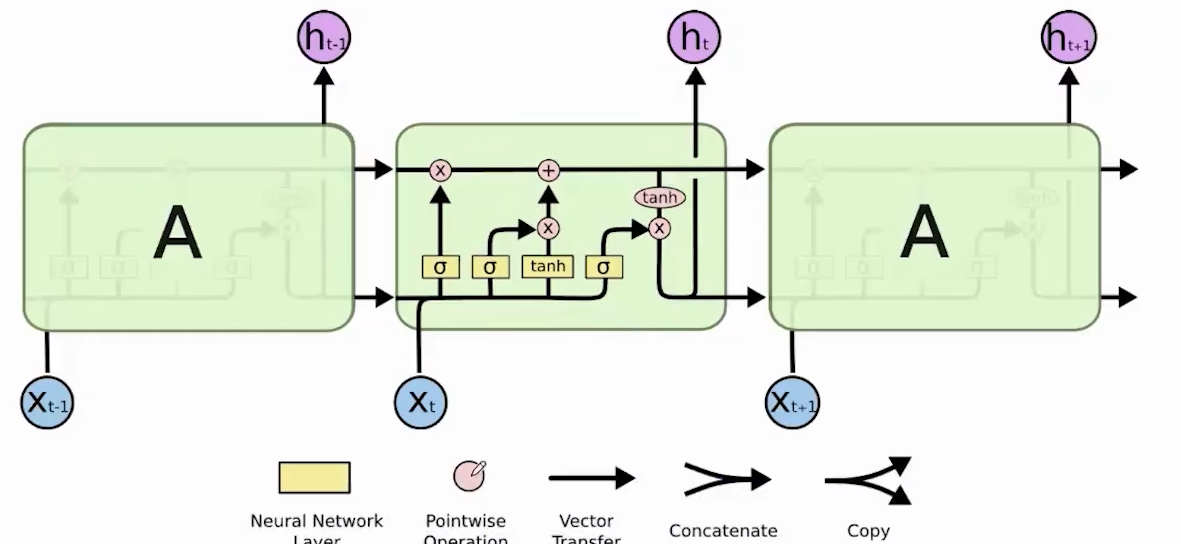
变体2:长短时记忆网络LSTM
长期依赖的学习是靠上面的那条水平线传递的Ct
主要有三个门:遗忘门 + 输入门 + 输出门 (从左到右)
每个隐藏层都有一个神经网络计算,所以即使神经网络巨大,性能依旧不会有很大下降;引入门控机制,可以动态控制输入输出,增强对信息的利用能力;可以有效缓解梯度
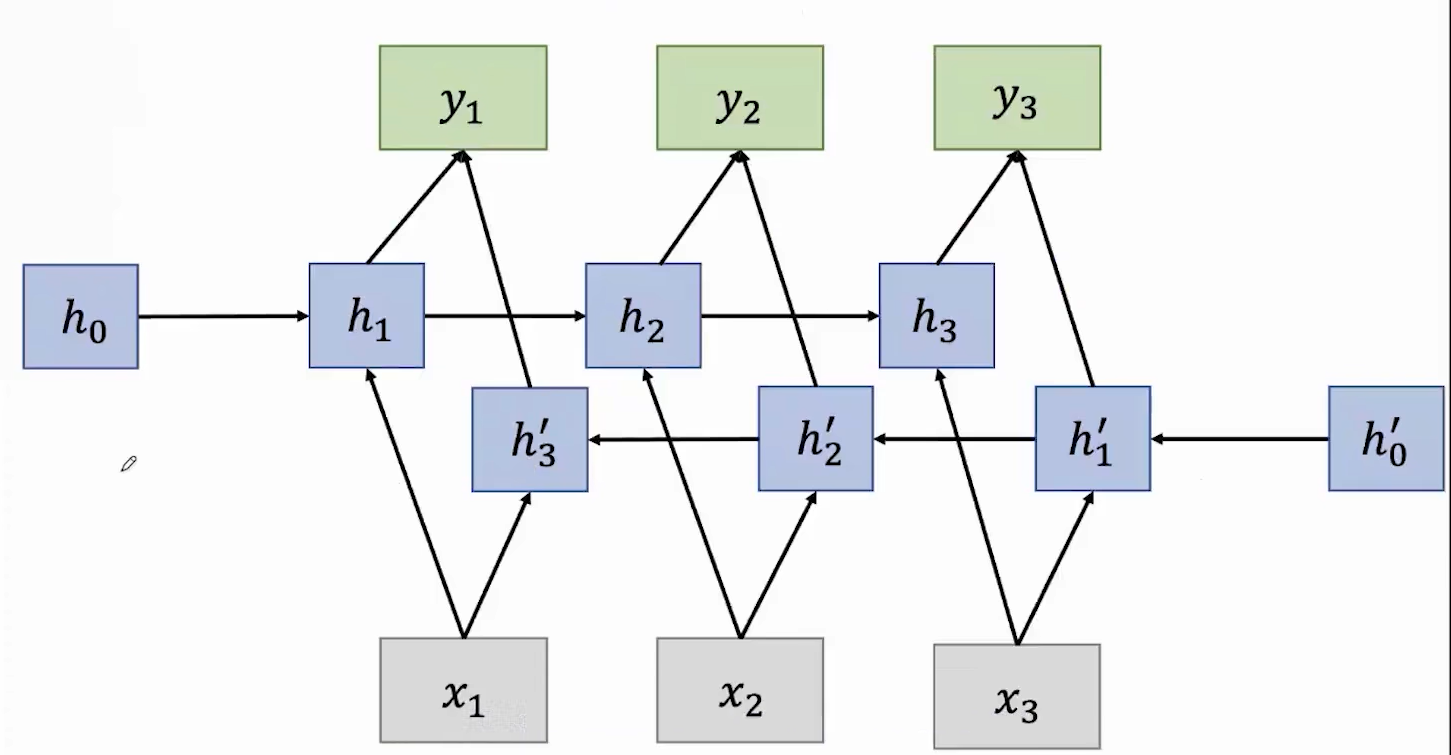
变体3:双向RNN
不仅学习过去数据,还从未来数据学习,进行预测
卷积神经网络(CNN)
擅长提取局部特征,参数量比较小,主要计算量在卷积部分,由于卷积没有依赖关系,可以并行计算。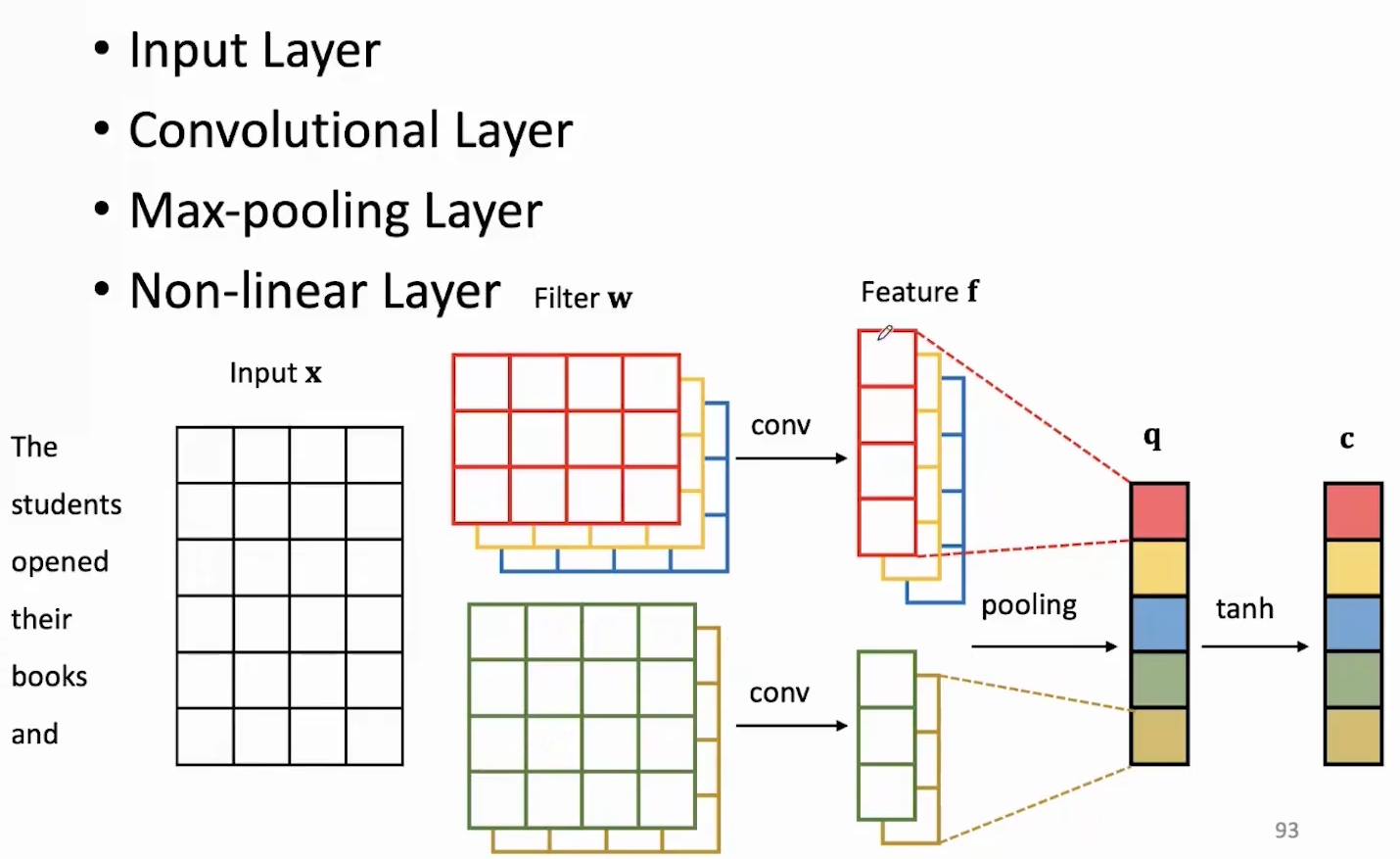
Transformer and PLMs(Huggingface Transformers)
注意力机制
我们拿机器翻译举例:基于RNN的语言模型存在一个问题:信息瓶颈,也就是encoder的最后一个词向量表示整个句子的信息,但是将所有信息都存储在一个词向量中,后续由decoder解析是不合理的(一个词向量不可能包含过多的信息)
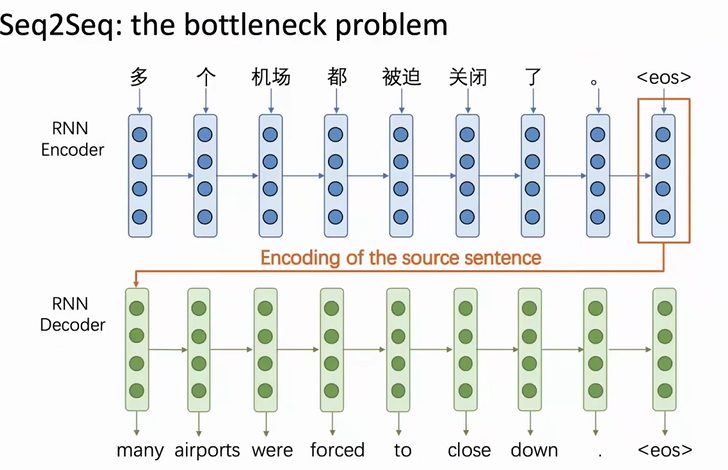
为了encoder中的每个词向量都被利用到(输入序列的信息都可以拿到),就提出了注意力机制。decoder的输入不在只有1个,而是将encoder的每一个词向量都交给decoder,然后计算一个注意力分数来决定decoder中的某一个词向量更关注哪个encoder中的词向量。
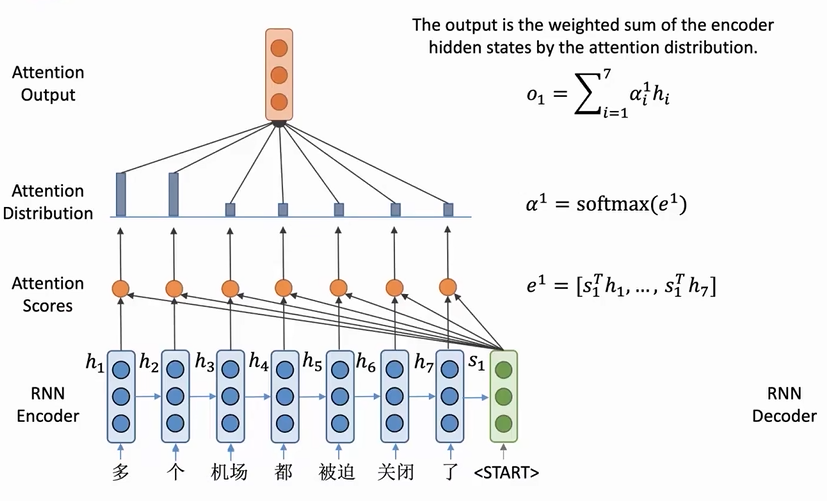
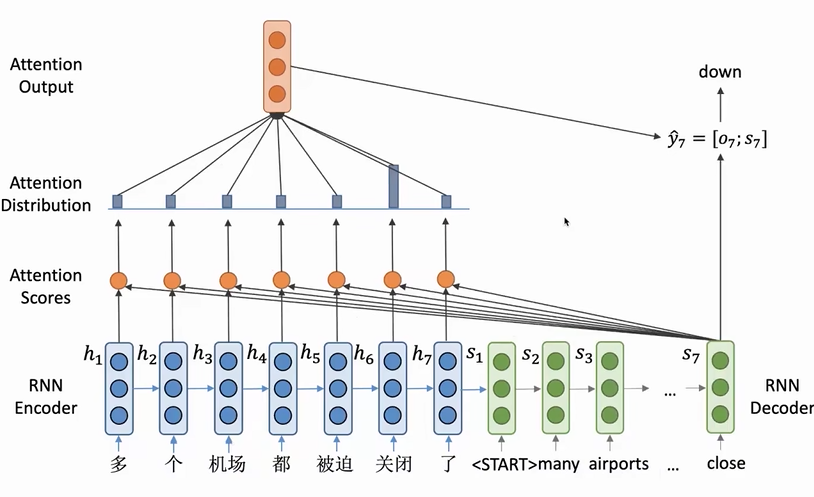
本质上来说,attention的过程其实就是decoder中的每一个向量对encoder中的每一个向量进行加权平均(动态选择的过程)
attention分数的计算有各种模式,通过向量点积是最常用的
注意力机制的特点
- 通过利用encoder中所有的词向量,缓解了信息瓶颈的问题
- 通过encoder和decoder的直接联系,缓解了RNN中梯度传播过长导致的梯度爆炸和梯度消失问题
- 通过可视化decoder中每一步的注意力分布图,为模型提供了可解释性
Transformer
RNN以及所有的RNN变体神经网络都有一个绕不开的问题,就是需要顺序的计算每一个单元。无疑会造成计算上的性能瓶颈。那对于NLP这种处理文本类型任务的方向,能不能不使用RNN模型。
| 作者在[Attention is all you need | Proceedings of the 31st International Conference on Neural Information Processing Systems](https://dl.acm.org/doi/10.5555/3295222.3295349)中提出了transformer架构 |
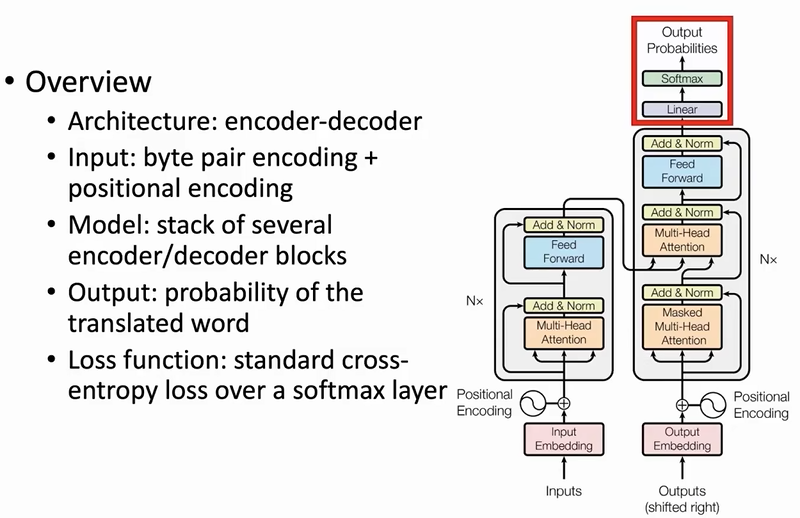
transformer各个部分的介绍
输入向量 = BPE + PE
byte pair encoding(BPE):
- word segmentation algorithm
- Start with a vocabulary of characters
- Turn the most frequent n-gram to a new n-gram
- low: 5 lower: 2 newest: 6 wildest: 3
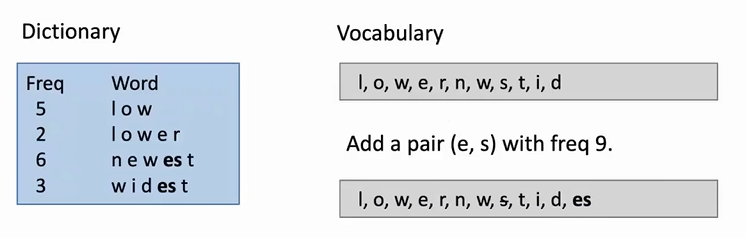
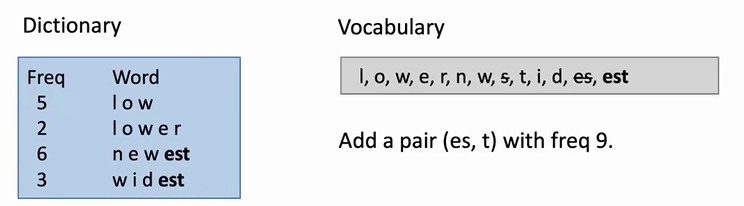
不停重复添加es,删除s的这个过程,直到无法再组合任意两个字母或者单词。
通过将单词划分为字母,在逐步组合的这种词嵌入方式,可以很好的解决词表太大,导致模型无法记录太大单词,以至于出现新单词不认识的情况。比如lowest就会被分为low和est。这两个单词出现在词表中的概率就大很多了。
| 更多的信息参考这篇paper:[[PDF] Neural Machine Translation of Rare Words with Subword Units | Semantic Scholar](https://www.semanticscholar.org/paper/Neural-Machine-Translation-of-Rare-Words-with-Units-Sennrich-Haddow/1518039b5001f1836565215eb047526b3ac7f462) |
positional encoding(PE):
由于transformer不基于RNN,所以需要一个部分来处理文本的位置信息。
- 具体来说,每个在一个文本序列中的每个词汇的位置用pos表示,d是BPE的维度。通过三角函数计算不同pos的PE向量。
- 由于三角函数有界,所以PE向量的大小可控。由于不同位置用不同的方式计算,所以不同文本的PE向量唯一。
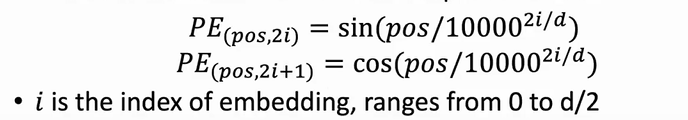
encoder
transformer架构都是面对序列文本的,所以它的Input和Output都是连续进行的,比如输入是 <strart> I am a student <end> 那么最开始那层的input就是<start>,后面的input就是I am a student依次进行BPE和PE的结果词向量。
- MLP:多层感知机,其实就是全连接层
- residual connection:残差连接,输入和输出的直接求和。缓解梯度消失问题
- layer normalization:正则化,针对梯度消失和爆炸问题
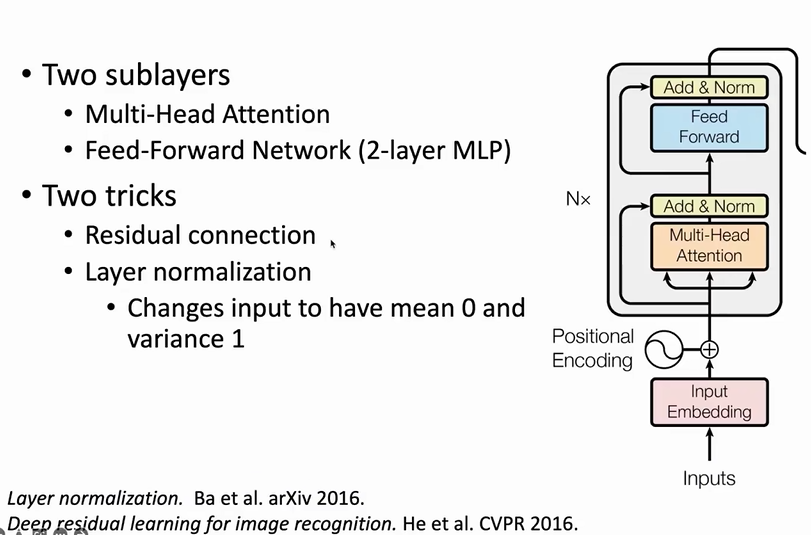
多头注意力机制及encoder的输入输出细节:【【清华NLP】刘知远团队大模型公开课全网首发|带你从入门到实战】 https://www.bilibili.com/video/BV1UG411p7zv/?p=27&share_source=copy_web&vd_source=fa43e9d6cd4073e1172b87c3220f143c
decoder
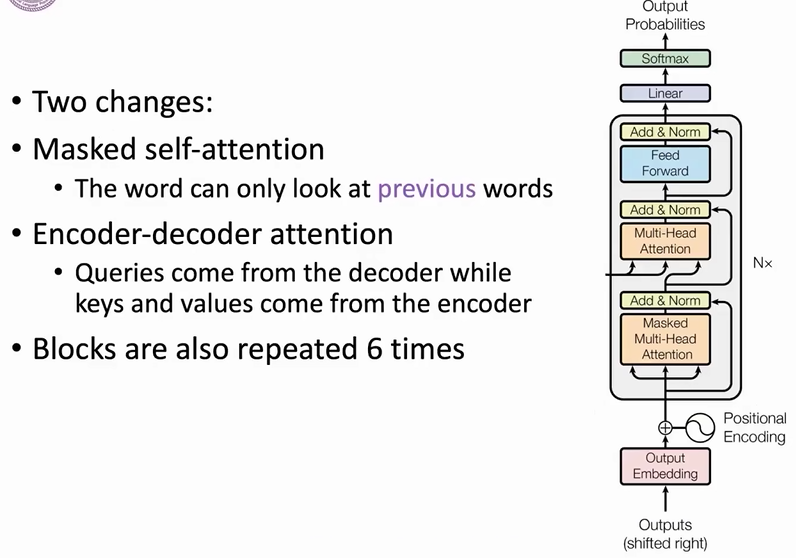
mask多头注意力机制及decoder的输入输出细节:【【清华NLP】刘知远团队大模型公开课全网首发|带你从入门到实战】 https://www.bilibili.com/video/BV1UG411p7zv/?p=28&share_source=copy_web&vd_source=fa43e9d6cd4073e1172b87c3220f143c
训练技巧

transformer的性能
作者通过encoder和decoder层的注意力可视化,展示了输出词关注的输入词的结果。发现transformer是可以不错的进行文本信息的解析,这样在很多NLP任务中就有很好的性能了。
transformer证明了注意力机制的价值,同时其架构很适合并行计算
但是transformer架构是很关注参数的,也就导致了想要训练优化参数,超参数、优化器的选择就很关键。
由于使用了注意力机制,所以每个输出都会关注所有输入,每一层的复杂度都会达到O(n^2),所以无法处理较大规模的文本。大部分基于transformer的模型都会采用一个最大的输入token长度。
Pretrained Language Models
所谓预训练语言模型其实就是对一个语言模型进行训练的结果。语言模型是NLP任务的基础,从Word2Vec到pretrained RNN再到基于transformer的GPT/BERT,都是语言模型。语言模型仅需要文本数据就可以训练,也是其成本低廉的重要原因。
预训练语言模型主要有两种范式:
- 基于特征:PLM训练好之后就不动了,作为一个知识提取器,将其输出作为下游任务模型的输入,效果有限。
- 基于微调:面对不同下游任务,通过不同的训练数据微调PLM的参数

GPT和BERT的发展都表明了一个现象:模型的参数越大,性能越好。并且没有看到一个明显的上限。
BERT不同于GPT,它关注双向的信息。通过前后文一起训练模型,也通过一些手段来平衡了透露答案的这么一个问题。可以理解为模型在训练过程中在做完形填空,空的部分称为Mask。由于这个Mask不参与下游任务的微调,所以微调和预训练之间存在gap;此外由于BERT训练过程中关注Mask部分(占比15%),所以训练效率是比较低的。
常见的PLM如GPT,BERT的介绍:【【清华NLP】刘知远团队大模型公开课全网首发|带你从入门到实战】 https://www.bilibili.com/video/BV1UG411p7zv/?p=33&share_source=copy_web&vd_source=fa43e9d6cd4073e1172b87c3220f143c
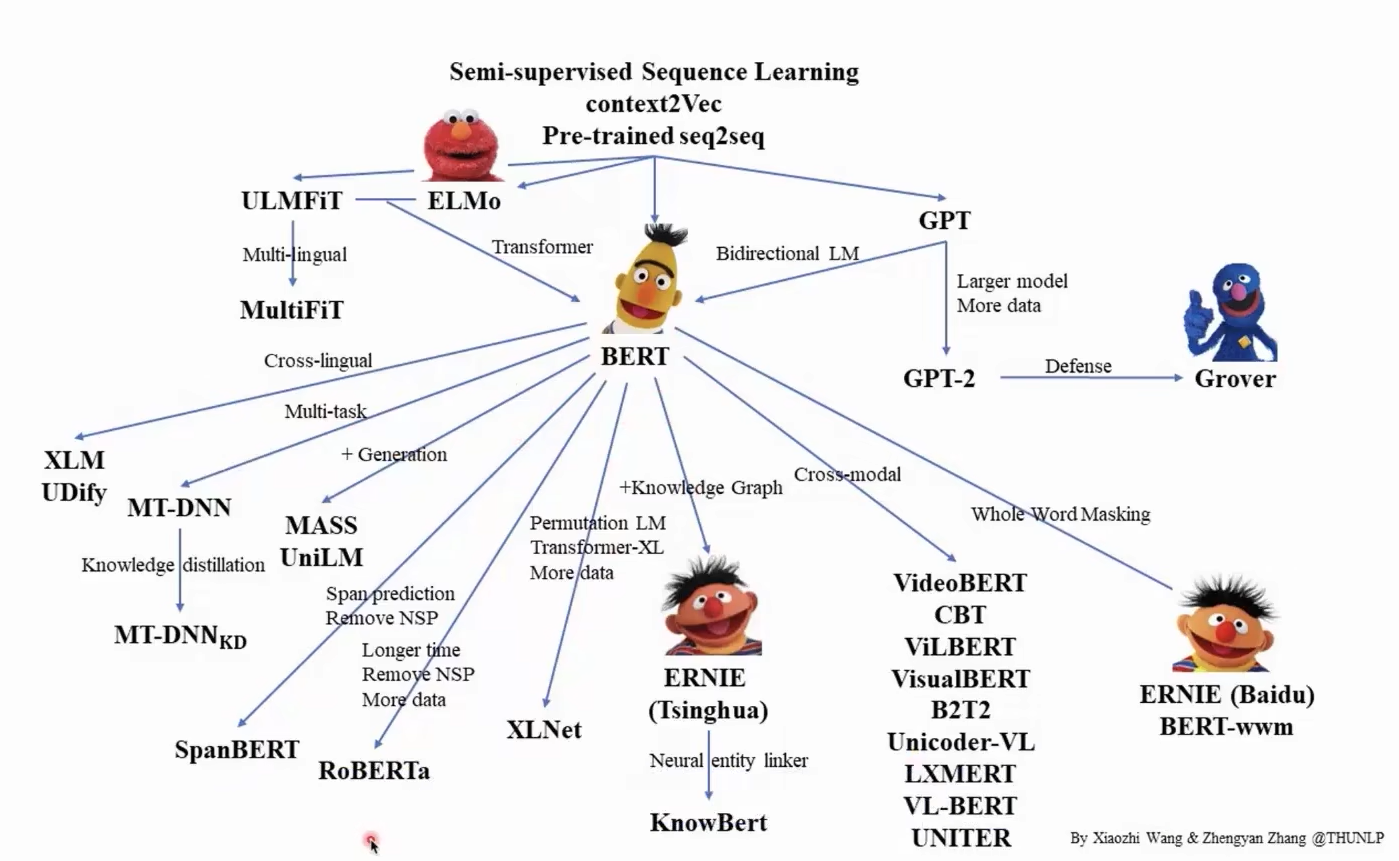
预训练模型的paper:https://github.com/thunlp/PLMpapers
Transformers Tutorial
什么是transformers?
自从GPT和BERT模型提出之后,研究者基于这两个模型进行了各种大大小小的变体与改进,进而产生了许多PLM。对于研究者和工程师来说,读每篇论文,复现每种PLM的架构是不现实的。所以Hugging Face公司就开发了Transformers这一个包。
Transformers支持5万多个PLM,也支持主流的深度学习框架。可以直接使用已有的PLM,也可以基于transformers包去微调现有PLM构建新的模型,并保存。