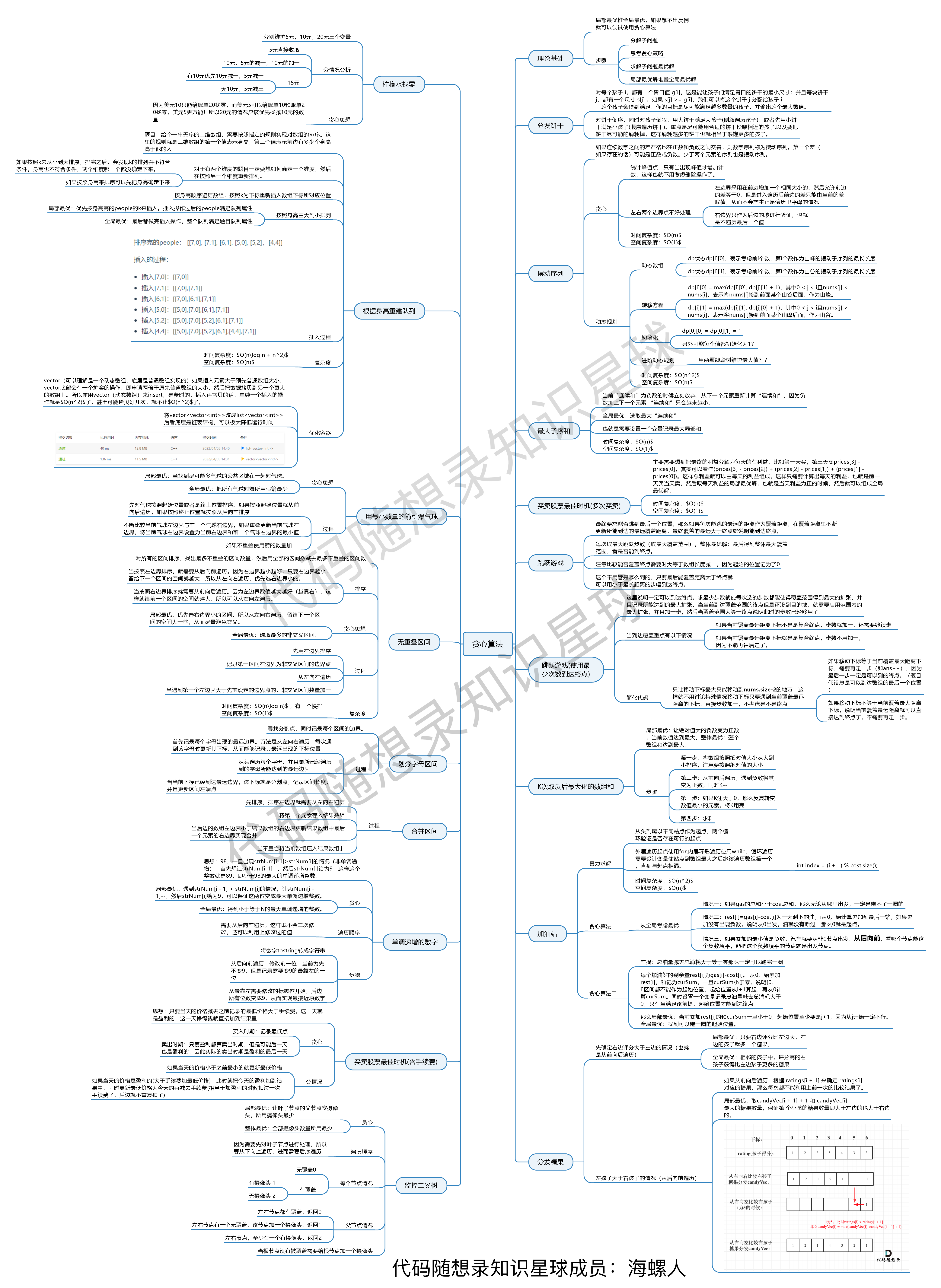
贪心算法理论基础
贪心的本质是选择每一阶段的局部最优,从而达到全局最优。
所以贪心算法的使用时机就是:看一下能不能分解子问题,子问题都是最优的,原问题能不能最优。一般来说,自己模拟一下一个题目例子,就知道能不能用贪心了。验证贪心算法就靠举反例;有反例就不能用,不然就尝试用一下咯
贪心算法的解题步骤
- 将问题分解为若干个子问题
- 找出适合的贪心策略
- 求解每一个子问题的最优解
- 将局部最优解堆叠成全局最优解
贪心算法是人生来就会的算法,一般靠自己的常识性理解就能想出解法,不然就不要想了
455.分发饼干
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。
对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
示例 1:
输入: g = [1,2,3], s = [1,1]
输出: 1 解释:你有三个孩子和两块小饼干,3 个孩子的胃口值分别是:1,2,3。虽然你有两块小饼干,由于他们的尺寸都是 1,你只能让胃口值是 1 的孩子满足。所以你应该输出 1。
1 <= g.length <= 3 * 10^4
0 <= s.length <= 3 * 10^4
1 <= g[i], s[j] <= 2^31 - 1
为了满足更多的小孩,就不要造成饼干尺寸的浪费。
大尺寸的饼干既可以满足胃口大的孩子也可以满足胃口小的孩子,那么就应该优先满足胃口大的。
这里的局部最优就是大饼干喂给胃口大的,充分利用饼干尺寸喂饱一个,全局最优就是喂饱尽可能多的小孩。
可以尝试使用贪心策略,先将饼干数组和小孩数组排序。
然后从后向前遍历小孩数组,用大饼干优先满足胃口大的,并统计满足小孩数量。
class Solution {
public:
int findContentChildren(vector<int>& g, vector<int>& s) {
sort(g.begin(), g.end());
sort(s.begin(), s.end());
int index = s.size() - 1; // 饼干数组的下标
int result = 0;
for (int i = g.size() - 1; i >= 0; i--) { // 遍历胃口
if (index >= 0 && s[index] >= g[i]) { // 遍历饼干
result++;
index--;
}
}
return result;
}
};
时间复杂度:O(nlogn)
空间复杂度:O(1)
376.摆动序列
如果连续数字之间的差严格地在正数和负数之间交替,则数字序列称为摆动序列。第一个差(如果存在的话)可能是正数或负数。少于两个元素的序列也是摆动序列。
例如, [1,7,4,9,2,5] 是一个摆动序列,因为差值 (6,-3,5,-7,3) 是正负交替出现的。相反, [1,4,7,2,5] 和 [1,7,4,5,5] 不是摆动序列,第一个序列是因为它的前两个差值都是正数,第二个序列是因为它的最后一个差值为零。
给定一个整数序列,返回作为摆动序列的最长子序列的长度。 通过从原始序列中删除一些(也可以不删除)元素来获得子序列,剩下的元素保持其原始顺序。
示例 1:
输入: [1,7,4,9,2,5]
输出: 6
解释: 整个序列均为摆动序列。
示例 2:
输入: [1,17,5,10,13,15,10,5,16,8]
输出: 7
解释: 这个序列包含几个长度为 7 摆动序列,其中一个可为[1,17,10,13,10,16,8]。
要求删除元素使其达到最大摆动序列,应该删除什么元素呢?用示例二来举例,如图所示:
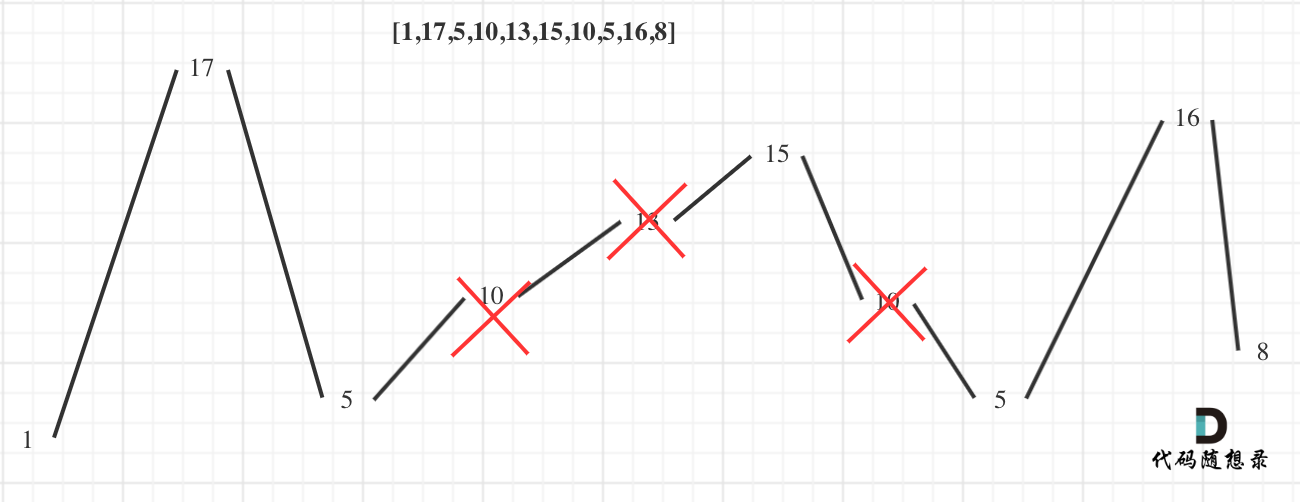
局部最优:删除单调坡度上的节点(不包括单调坡度两端的节点),那么这个坡度就可以有两个局部峰值。(因为题目要的是摆动序列,有单调出现对摆动长度增长是无效的)
整体最优:整个序列有最多的局部峰值,从而达到最长摆动序列。
局部最优推出全局最优,并举不出反例,那么试试贪心!
实际操作上,其实连删除的操作都不用做,因为题目要求的是最长摆动子序列的长度,所以只需要统计数组的峰值数量就可以了(相当于是删除单一坡度上的节点,然后统计长度)
这就是贪心所贪的地方,让峰值尽可能的保持峰值,然后删除单一坡度上的节点
在计算是否有峰值的时候,大家知道遍历的下标 i ,计算 prediff =(nums[i] - nums[i-1]) 和 curdiff =(nums[i+1] - nums[i]),如果prediff < 0 && curdiff > 0 或者 prediff > 0 && curdiff < 0 此时就有波动就需要统计。但有三种特殊情况:
情况一:上下坡中有平坡
例如 [1,2,2,2,1]这样的数组,如图:
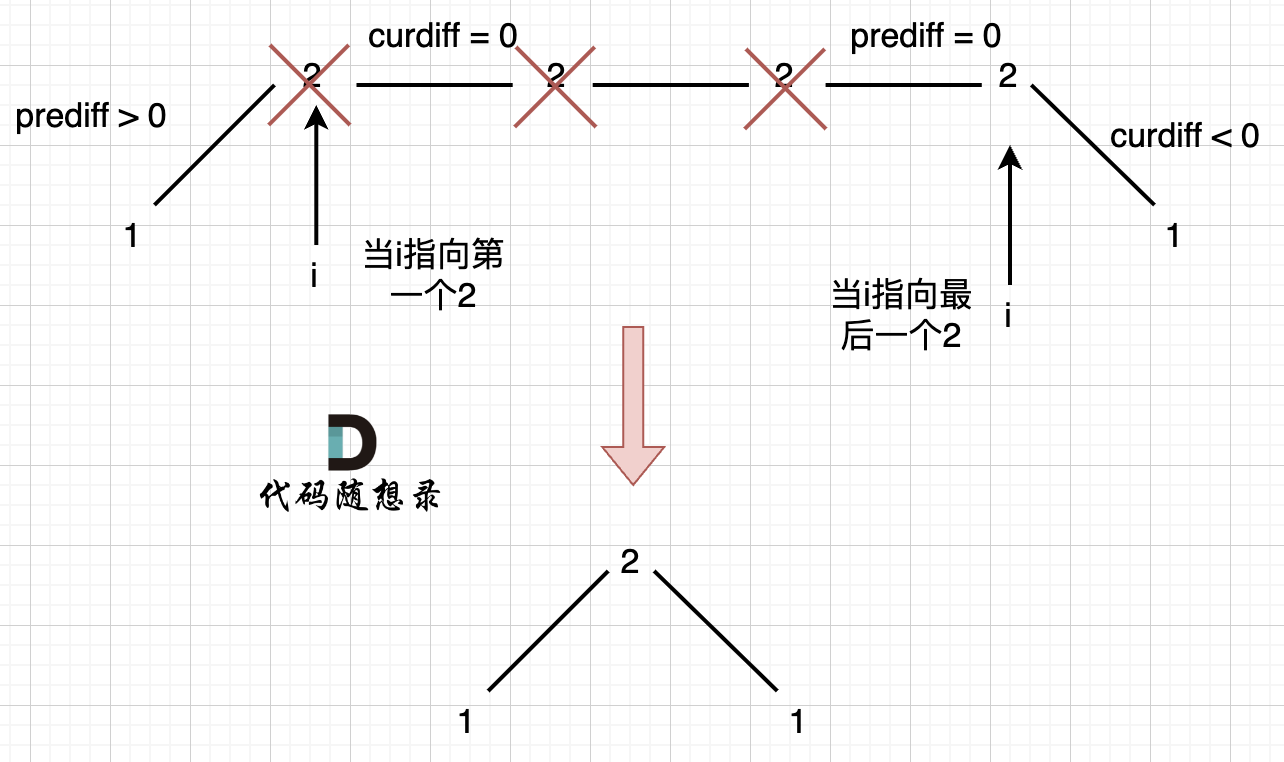
在图中,当 i 指向第一个 2 的时候,prediff > 0 && curdiff = 0 ,当 i 指向最后一个 2 的时候 prediff = 0 && curdiff < 0。
如果我们采用,删左面三个 2 的规则,那么 当 prediff = 0 && curdiff < 0 也要记录一个峰值,因为他是把之前相同的元素都删掉留下的峰值。
所以我们记录峰值的条件应该是: (preDiff <= 0 && curDiff > 0) || (preDiff >= 0 && curDiff < 0),为什么这里允许 prediff == 0 ,就是为了 上面我说的这种情况。
情况二:数组首尾两端
所以本题统计峰值的时候,数组最左面和最右面如何统计呢?题目中说了,如果只有两个不同的元素,那摆动序列也是 2。
可以假设,数组最前面还有一个数字,那这个数字应该是什么呢?
之前我们在 讨论 情况一:相同数字连续 的时候, prediff = 0 ,curdiff < 0 或者 >0 也记为波谷。
那么为了规则统一,针对序列[2,5],可以假设为[2,2,5],这样它就有坡度了即 preDiff = 0,如图:
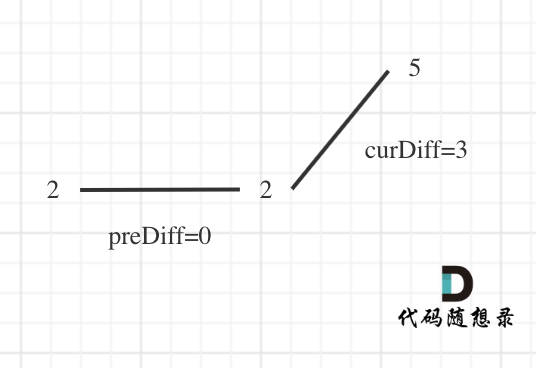
针对以上情形,result 初始为 1(默认最右面有一个峰值),此时 curDiff > 0 && preDiff <= 0,那么 result++(计算了左面的峰值),最后得到的 result 就是 2(峰值个数为 2 即摆动序列长度为 2)
情况三:单调坡度有平坡
如果在一个单调坡度上有平坡,例如[1,2,2,2,3,4],如图:
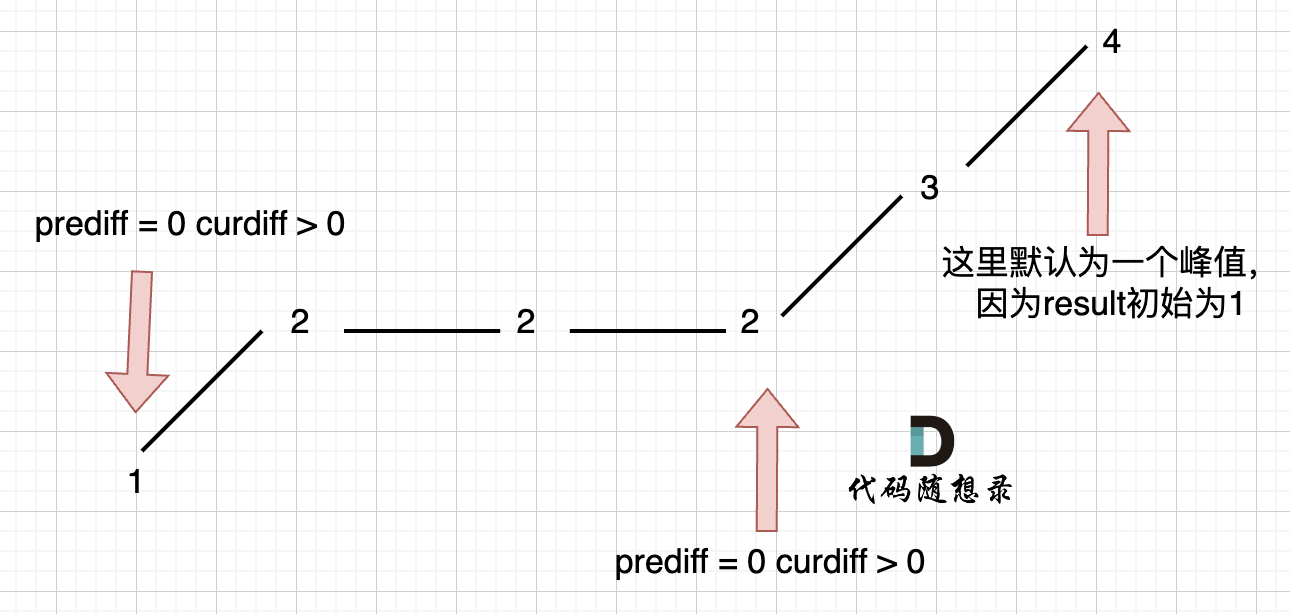
我们只需要在 这个坡度 摆动变化的时候,更新 prediff 就行,这样 prediff 在 单调区间有平坡的时候 就不会发生变化,造成我们的误判。
class Solution {
public:
int wiggleMaxLength(vector<int>& nums) {
if (nums.size() <= 1) return nums.size();
int curDiff = 0; // 当前一对差值
int preDiff = 0; // 前一对差值
int result = 1; // 记录峰值个数,序列默认序列最右边有一个峰值
for (int i = 0; i < nums.size() - 1; i++) {
curDiff = nums[i + 1] - nums[i];
// 出现峰值
if ((preDiff <= 0 && curDiff > 0) || (preDiff >= 0 && curDiff < 0)) {
result++;
preDiff = curDiff; // 注意这里,只在摆动变化的时候更新prediff
}
}
return result;
}
};
时间复杂度:O(n)
空间复杂度:O(1)
53. 最大子序和
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
示例:
输入: [-2,1,-3,4,-1,2,1,-5,4]
输出: 6
解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。
贪心贪的是哪里呢?
如果 -2 1 在一起,计算起点的时候,一定是从 1 开始计算,因为负数只会拉低总和,这就是贪心贪的地方!
局部最优:当前“连续和”为负数的时候立刻放弃,从下一个元素重新计算“连续和”,因为负数加上下一个元素 “连续和”只会越来越小。
全局最优:选取最大“连续和”
局部最优的情况下,并记录最大的“连续和”,可以推出全局最优。
从代码角度上来讲:遍历 nums,从头开始用 count 累积,如果 count 一旦加上 nums[i]变为负数,那么就应该从 nums[i+1]开始从 0 累积 count 了,因为已经变为负数的 count,只会拖累总和。这相当于是暴力解法中的不断调整最大子序和区间的起始位置。使用一个 result 去记录结果,当 count 更大时就记录下来这样相当于是用 result 记录最大子序和区间和(变相的算是调整了终止位置)。
class Solution {
public:
int maxSubArray(vector<int>& nums) {
int result = INT32_MIN;
int count = 0;
for (int i = 0; i < nums.size(); i++) {
count += nums[i];
if (count > result) { // 取区间累计的最大值(相当于不断确定最大子序终止位置)
result = count;
}
if (count <= 0) count = 0; // 相当于重置最大子序起始位置,因为遇到负数一定是拉低总和
}
return result;
}
};
时间复杂度:O(n)
空间复杂度:O(1)
122.买卖股票的最佳时机 II
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入: [7,1,5,3,6,4]
输出: 7
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4。随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。
示例 2:
输入: [7,6,4,3,1]
输出: 0
解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。
提示:
1 <= prices.length <= 3 * 10 ^ 4
0 <= prices[i] <= 10 ^ 4
这道题目可能我们只会想,选一个低的买入,再选个高的卖,再选一个低的买入…..循环反复。
如果想到其实最终利润是可以分解的,那么本题就很容易了!
假如第 0 天买入,第 3 天卖出,那么利润为:prices[3] - prices[0]。
相当于(prices[3] - prices[2]) + (prices[2] - prices[1]) + (prices[1] - prices[0])。
此时就是把利润分解为每天为单位的维度,而不是从 0 天到第 3 天整体去考虑!
那么根据 prices 可以得到每天的利润序列:(prices[i] - prices[i - 1])…..(prices[1] - prices[0])。
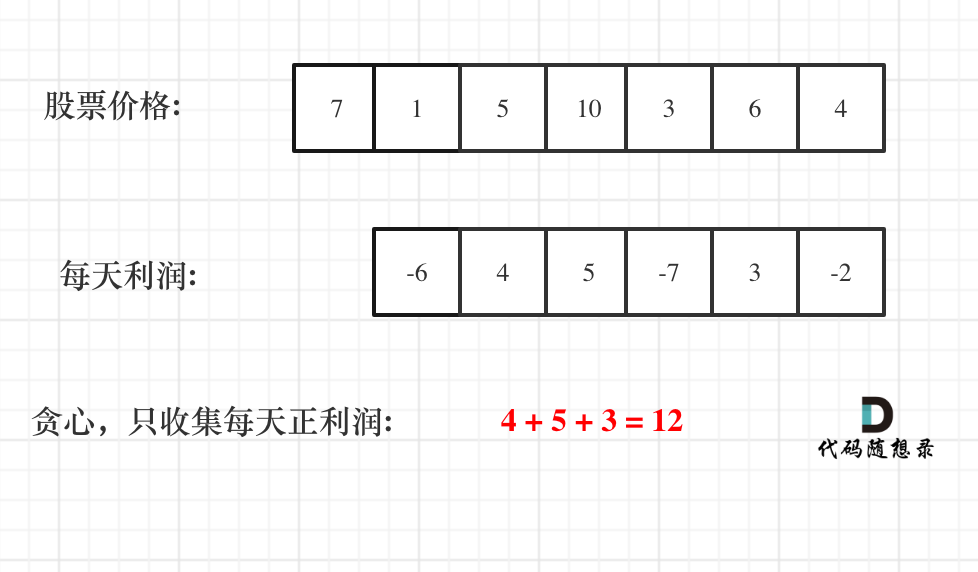
从图中可以发现,其实我们需要收集每天的正利润就可以,收集正利润的区间,就是股票买卖的区间,而我们只需要关注最终利润,不需要记录区间。
那么只收集正利润就是贪心所贪的地方!
局部最优:收集每天的正利润,全局最优:求得最大利润。
class Solution {
public:
int maxProfit(vector<int>& prices) {
int result = 0;
for (int i = 1; i < prices.size(); i++) {
result += max(prices[i] - prices[i - 1], 0);
}
return result;
}
};
时间复杂度:O(n)
空间复杂度:O(1)
55. 跳跃游戏
给定一个非负整数数组,你最初位于数组的第一个位置。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个位置。
示例 1:
输入: [2,3,1,1,4]
输出: true
解释: 我们可以先跳 1 步,从位置 0 到达 位置 1, 然后再从位置 1 跳 3 步到达最后一个位置。
示例 2:
输入: [3,2,1,0,4]
输出: false
解释: 无论怎样,你总会到达索引为 3 的位置。但该位置的最大跳跃长度是 0 , 所以你永远不可能到达最后一个位置。
刚看到本题一开始可能想:当前位置元素如果是 3,我究竟是跳一步呢,还是两步呢,还是三步呢,究竟跳几步才是最优呢?
其实跳几步无所谓,关键在于可跳的覆盖范围!
不一定非要明确一次究竟跳几步,每次取最大的跳跃步数,这个就是可以跳跃的覆盖范围。
这个范围内,别管是怎么跳的,反正一定可以跳过来。
那么这个问题就转化为跳跃覆盖范围究竟可不可以覆盖到终点!
每次移动取最大跳跃步数(得到最大的覆盖范围),每移动一个单位,就更新最大覆盖范围。
贪心算法局部最优解:每次取最大跳跃步数(取最大覆盖范围),整体最优解:最后得到整体最大覆盖范围,看是否能到终点。
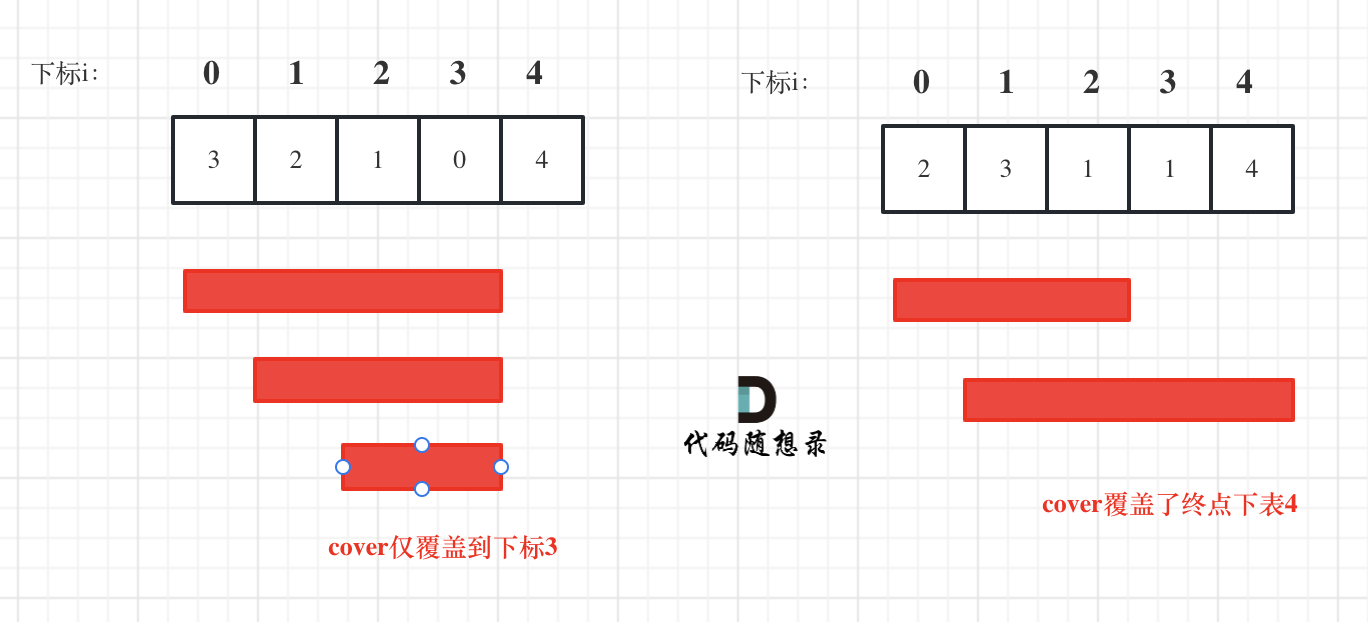
i 每次移动只能在 cover 的范围内移动,每移动一个元素,cover 得到该元素数值(新的覆盖范围)的补充,让 i 继续移动下去。
而 cover 每次只取 max(该元素数值补充后的范围, cover 本身范围)。如果 cover 大于等于了终点下标,直接 return true 就可以了。
class Solution {
public:
bool canJump(vector<int>& nums) {
int cover = 0;
if (nums.size() == 1) return true; // 只有一个元素,就是能达到
for (int i = 0; i <= cover; i++) { // 注意这里是小于等于cover
cover = max(i + nums[i], cover);
if (cover >= nums.size() - 1) return true; // 说明可以覆盖到终点了
}
return false;
}
};
时间复杂度: O(n)
空间复杂度: O(1)
45.跳跃游戏 II
给定一个非负整数数组,你最初位于数组的第一个位置。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
你的目标是使用最少的跳跃次数到达数组的最后一个位置。
示例:
输入: [2,3,1,1,4]
输出: 2
解释: 跳到最后一个位置的最小跳跃数是 2。从下标为 0 跳到下标为 1 的位置,跳 1 步,然后跳 3 步到达数组的最后一个位置。
说明: 假设你总是可以到达数组的最后一个位置。
本题要计算最少步数,那么就要想清楚什么时候步数才一定要加一呢?
贪心的思路,局部最优:当前可移动距离尽可能多走,如果还没到终点,步数再加一。
整体最优:一步尽可能多走,从而达到最少步数。
解题的时候,要从覆盖范围出发,不管怎么跳,覆盖范围内一定是可以跳到的,以最小的步数增加覆盖范围,覆盖范围一旦覆盖了终点,得到的就是最少步数!
这里需要统计两个覆盖范围,当前这一步的最大覆盖和下一步最大覆盖。
如果移动下标达到了当前这一步的最大覆盖最远距离了,还没有到终点的话,那么就必须再走一步来增加覆盖范围,直到覆盖范围覆盖了终点。
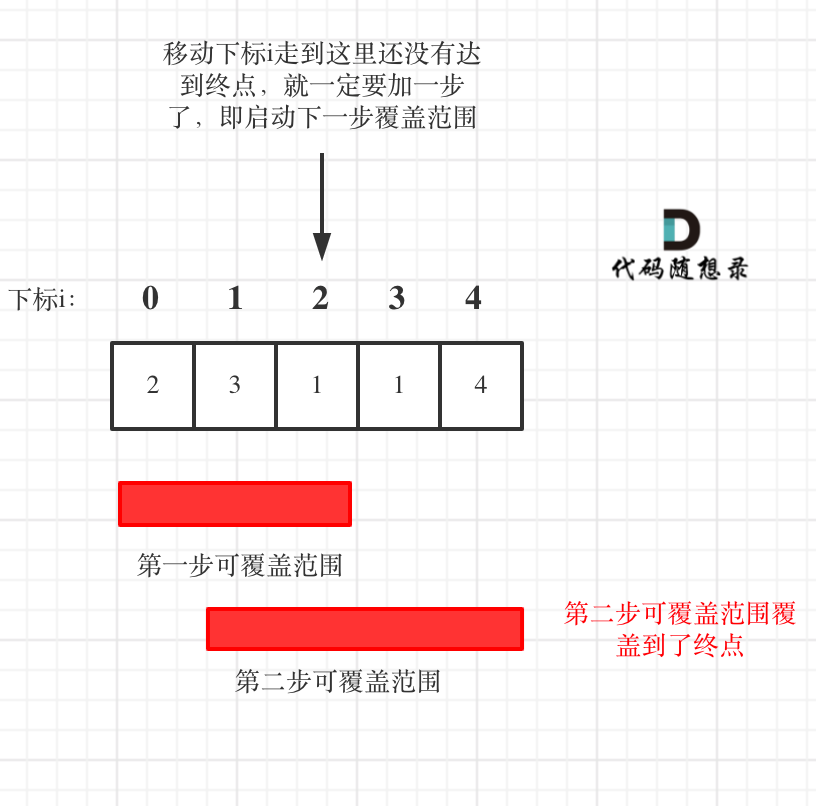
class Solution {
public:
int jump(vector<int>& nums) {
if (nums.size() == 1) return 0;
int curDistance = 0; // 当前覆盖最远距离下标
int ans = 0; // 记录走的最大步数
int nextDistance = 0; // 下一步覆盖最远距离下标
for (int i = 0; i < nums.size(); i++) {
nextDistance = max(nums[i] + i, nextDistance); // 更新下一步覆盖最远距离下标
if (i == curDistance) { // 遇到当前覆盖最远距离下标
ans++; // 需要走下一步
curDistance = nextDistance; // 更新当前覆盖最远距离下标(相当于加油了)
if (nextDistance >= nums.size() - 1) break; // 当前覆盖最远距到达集合终点,不用做ans++操作了,直接结束
}
}
return ans;
}
};
时间复杂度: O(n)
空间复杂度: O(1)
1005.K 次取反后最大化的数组和
给定一个整数数组 A,我们只能用以下方法修改该数组:我们选择某个索引 i 并将 A[i] 替换为 -A[i],然后总共重复这个过程 K 次。(我们可以多次选择同一个索引 i。)
以这种方式修改数组后,返回数组可能的最大和。
示例 1:
输入:A = [4,2,3], K = 1
输出:5
解释:选择索引 (1) ,然后 A 变为 [4,-2,3]。
示例 2:
输入:A = [3,-1,0,2], K = 3
输出:6
解释:选择索引 (1, 2, 2) ,然后 A 变为 [3,1,0,2]。
提示:
1 <= A.length <= 10000
1 <= K <= 10000
-100 <= A[i] <= 100
本题思路其实比较好想了,如何可以让数组和最大呢?
贪心的思路,局部最优:让绝对值大的负数变为正数,当前数值达到最大,整体最优:整个数组和达到最大。
局部最优可以推出全局最优。
那么如果将负数都转变为正数了,K依然大于0,此时的问题是一个有序正整数序列,如何转变K次正负,让 数组和 达到最大。
那么又是一个贪心:局部最优:只找数值最小的正整数进行反转,当前数值和可以达到最大(例如正整数数组{5, 3, 1},反转1 得到-1 比 反转5得到的-5 大多了),全局最优:整个 数组和 达到最大。
我这里其实是为了给大家展现出来 经常被大家忽略的贪心思路,这么一道简单题,就用了两次贪心!
那么本题的解题步骤为:
第一步:将数组按照绝对值大小从大到小排序,注意要按照绝对值的大小
第二步:从前向后遍历,遇到负数将其变为正数,同时K--
第三步:如果K还大于0,那么反复转变数值最小的元素,将K用完
第四步:求和
class Solution {
static bool cmp(int a, int b) {
return abs(a) > abs(b);
}
public:
int largestSumAfterKNegations(vector<int>& A, int K) {
sort(A.begin(), A.end(), cmp); // 第一步
for (int i = 0; i < A.size(); i++) { // 第二步
if (A[i] < 0 && K > 0) {
A[i] *= -1;
K--;
}
}
if (K % 2 == 1) A[A.size() - 1] *= -1; // 第三步
int result = 0;
for (int a : A) result += a; // 第四步
return result;
}
};
时间复杂度: O(nlogn)
空间复杂度: O(1)
134. 加油站
在一条环路上有 N 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
如果你可以绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1。
说明:
如果题目有解,该答案即为唯一答案。
输入数组均为非空数组,且长度相同。
输入数组中的元素均为非负数。
示例 1: 输入:
gas = [1,2,3,4,5]
cost = [3,4,5,1,2]
输出: 3 解释:
从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油
开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油
开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油
开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油
开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油
开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。
因此,3 可为起始索引。
暴力解法:
暴力的方法很明显就是O(n^2)的,遍历每一个加油站为起点的情况,模拟一圈。
如果跑了一圈,中途没有断油,而且最后油量大于等于0,说明这个起点是ok的。
暴力的方法思路比较简单,但代码写起来也不是很容易,关键是要模拟跑一圈的过程。
for循环适合模拟从头到尾的遍历,而while循环适合模拟环形遍历,要善于使用while!
class Solution {
public:
int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {
for (int i = 0; i < cost.size(); i++) {
int rest = gas[i] - cost[i]; // 记录剩余油量
int index = (i + 1) % cost.size();
while (rest > 0 && index != i) { // 模拟以i为起点行驶一圈(如果有rest==0,那么答案就不唯一了)
rest += gas[index] - cost[index];
index = (index + 1) % cost.size();
}
// 如果以i为起点跑一圈,剩余油量>=0,返回该起始位置
if (rest >= 0 && index == i) return i;
}
return -1;
}
};
时间复杂度:O(n^2)
空间复杂度:O(1)
贪心算法:
首先如果总油量减去总消耗大于等于零那么一定可以跑完一圈,说明 各个站点的加油站 剩油量rest[i]相加一定是大于等于零的。
每个加油站的剩余量rest[i]为gas[i] - cost[i]。
i从0开始累加rest[i],和记为curSum,一旦curSum小于零,说明[0, i]区间都不能作为起始位置,因为这个区间选择任何一个位置作为起点,到i这里都会断油,那么起始位置从i+1算起,再从0计算curSum。
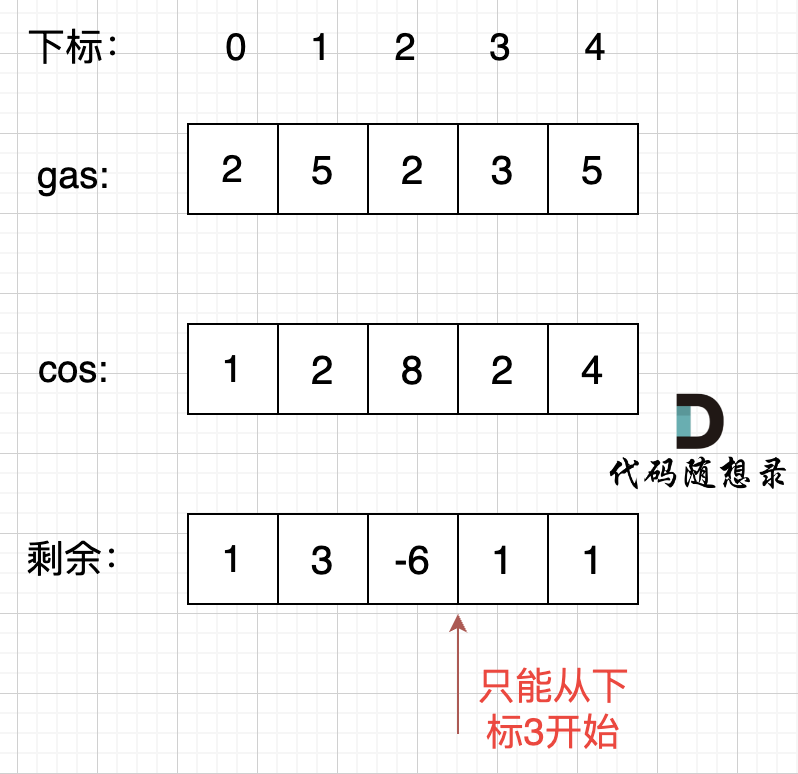
那么为什么一旦[0,i] 区间和为负数,起始位置就可以是 i+1 呢,i+1 后面就不会出现更大的负数?
如果出现更大的负数,就是更新 i,那么起始位置又变成新的 i+1 了。
那有没有可能 [0,i] 区间 选某一个作为起点,累加到 i 这里 curSum 是不会小于零呢? 如图:
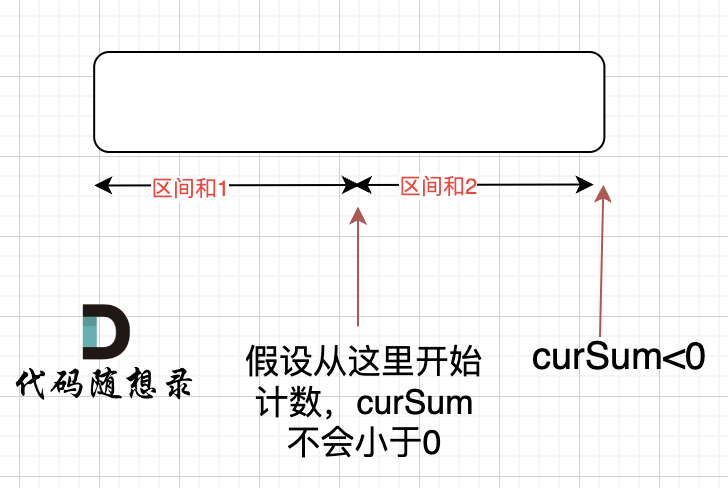
如果 curSum<0 说明 区间和 1 + 区间和 2 < 0, 那么 假设从上图中的位置开始计数 curSum 不会小于 0 的话,就是 区间和 2>0。
区间和 1 + 区间和 2 < 0 同时 区间和 2>0,只能说明区间和 1 < 0, 那么就会从假设的箭头初就开始从新选择其实位置了。
那么局部最优:当前累加 rest[i]的和 curSum 一旦小于 0,起始位置至少要是 i+1,因为从 i 之前开始一定不行。全局最优:找到可以跑一圈的起始位置。
class Solution {
public:
int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {
int curSum = 0;
int totalSum = 0;
int start = 0;
for (int i = 0; i < gas.size(); i++) {
curSum += gas[i] - cost[i];
totalSum += gas[i] - cost[i];
if (curSum < 0) { // 当前累加rest[i]和 curSum一旦小于0
start = i + 1; // 起始位置更新为i+1
curSum = 0; // curSum从0开始
}
}
if (totalSum < 0) return -1; // 说明怎么走都不可能跑一圈了
return start;
}
};
时间复杂度:O(n)
空间复杂度:O(1)
135. 分发糖果
老师想给孩子们分发糖果,有 N 个孩子站成了一条直线,老师会根据每个孩子的表现,预先给他们评分。
你需要按照以下要求,帮助老师给这些孩子分发糖果:
每个孩子至少分配到 1 个糖果。
相邻的孩子中,评分高的孩子必须获得更多的糖果。
那么这样下来,老师至少需要准备多少颗糖果呢?
示例 1:
输入: [1,0,2]
输出: 5
解释: 你可以分别给这三个孩子分发 2、1、2 颗糖果。
示例 2:
输入: [1,2,2]
输出: 4
解释: 你可以分别给这三个孩子分发 1、2、1 颗糖果。第三个孩子只得到 1 颗糖果,这已满足上述两个条件。
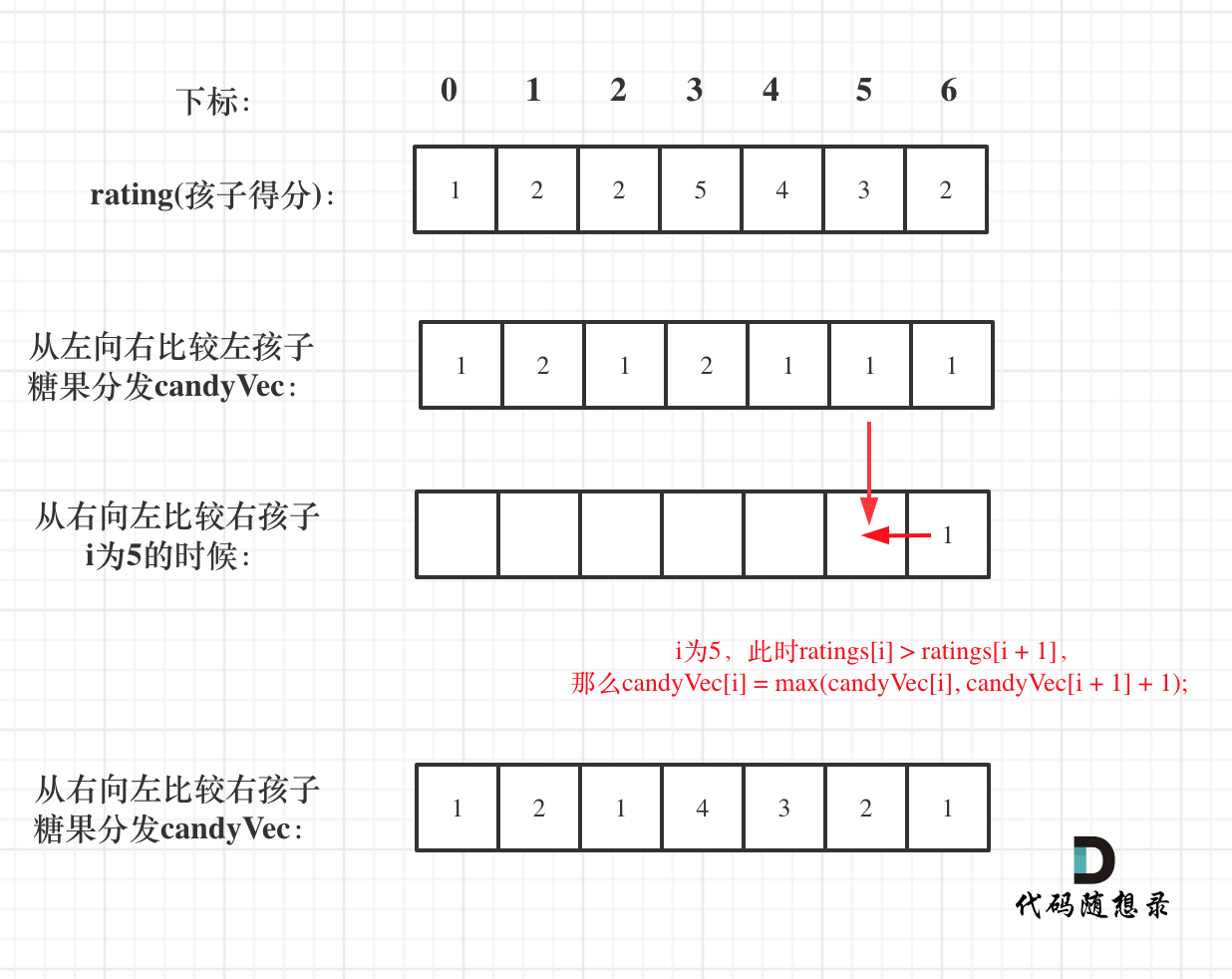
这道题目一定是要确定一边之后,再确定另一边,例如比较每一个孩子的左边,然后再比较右边,如果两边一起考虑一定会顾此失彼。
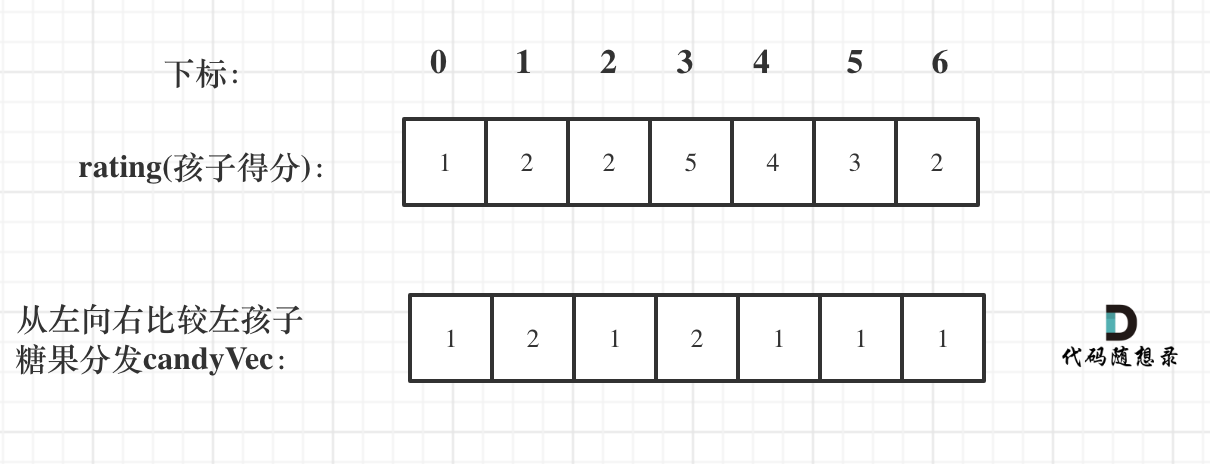
先确定右边评分大于左边的情况(也就是从前向后遍历)
此时局部最优:只要右边评分比左边大,右边的孩子就多一个糖果,全局最优:相邻的孩子中,评分高的右孩子获得比左边孩子更多的糖果
局部最优可以推出全局最优。
如果 ratings[i] > ratings[i - 1] 那么[i]的糖 一定要比[i - 1]的糖多一个,所以贪心:candyVec[i] = candyVec[i - 1] + 1。否则 candyVec[i] = 1(贪心,只分配满足的最小条件的最小 糖果)
再确定左孩子大于右孩子的情况(从后向前遍历)
遍历顺序这里有同学可能会有疑问,为什么不能从前向后遍历呢?
因为 rating[5]与 rating[4]的比较 要利用上 rating[5]与 rating[6]的比较结果,所以 要从后向前遍历。
如果从前向后遍历,rating[5]与 rating[4]的比较 就不能用上 rating[5]与 rating[6]的比较结果了 。如图:
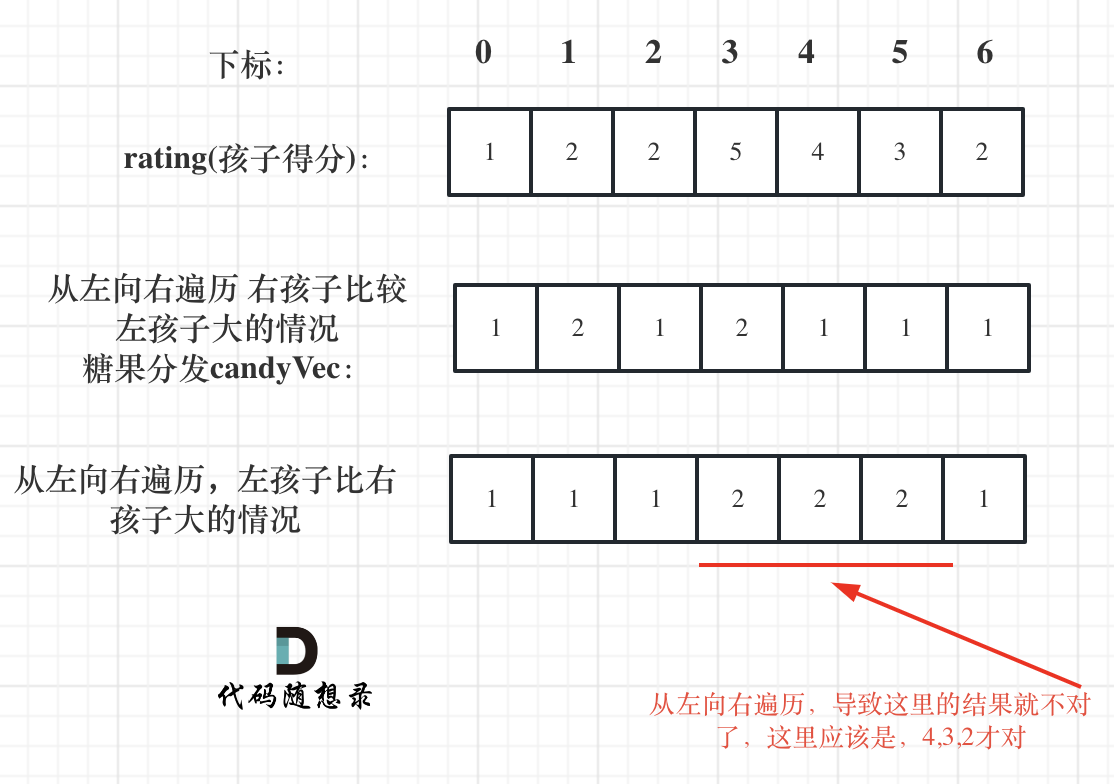
所以确定左孩子大于右孩子的情况一定要从后向前遍历!
如果 ratings[i] > ratings[i + 1],此时 candyVec[i](第 i 个小孩的糖果数量)就有两个选择了,一个是 candyVec[i + 1] + 1(从右边这个加 1 得到的糖果数量),一个是 candyVec[i](之前比较右孩子大于左孩子得到的糖果数量)。
那么又要贪心了,局部最优:取 candyVec[i + 1] + 1 和 candyVec[i] 最大的糖果数量,保证第 i 个小孩的糖果数量既大于左边的也大于右边的。全局最优:相邻的孩子中,评分高的孩子获得更多的糖果。
局部最优可以推出全局最优。
所以就取 candyVec[i + 1] + 1 和 candyVec[i] 最大的糖果数量,candyVec[i]只有取最大的才能既保持对左边 candyVec[i - 1]的糖果多,也比右边 candyVec[i + 1]的糖果多。
class Solution {
public:
int candy(vector<int>& ratings) {
vector<int> candyVec(ratings.size(), 1);
// 从前向后
for (int i = 1; i < ratings.size(); i++) {
if (ratings[i] > ratings[i - 1]) candyVec[i] = candyVec[i - 1] + 1;
}
// 从后向前
for (int i = ratings.size() - 2; i >= 0; i--) {
if (ratings[i] > ratings[i + 1] ) {
candyVec[i] = max(candyVec[i], candyVec[i + 1] + 1);
}
}
// 统计结果
int result = 0;
for (int i = 0; i < candyVec.size(); i++) result += candyVec[i];
return result;
}
};
时间复杂度: O(n)
空间复杂度: O(n)
860.柠檬水找零
在柠檬水摊上,每一杯柠檬水的售价为 5 美元。
顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。
每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零,也就是说净交易是每位顾客向你支付 5 美元。
注意,一开始你手头没有任何零钱。
如果你能给每位顾客正确找零,返回 true ,否则返回 false 。
示例 1:
输入:[5,5,5,10,20]
输出:true
解释:
前 3 位顾客那里,我们按顺序收取 3 张 5 美元的钞票。
第 4 位顾客那里,我们收取一张 10 美元的钞票,并返还 5 美元。
第 5 位顾客那里,我们找还一张 10 美元的钞票和一张 5 美元的钞票。
由于所有客户都得到了正确的找零,所以我们输出 true。
示例 4:
输入:[5,5,10,10,20]
输出:false
解释:
前 2 位顾客那里,我们按顺序收取 2 张 5 美元的钞票。
对于接下来的 2 位顾客,我们收取一张 10 美元的钞票,然后返还 5 美元。
对于最后一位顾客,我们无法退回 15 美元,因为我们现在只有两张 10 美元的钞票。
由于不是每位顾客都得到了正确的找零,所以答案是 false。
提示:
0 <= bills.length <= 10000
bills[i] 不是 5 就是 10 或是 20
只需要维护三种金额的数量,5,10 和 20。
有如下三种情况:
- 情况一:账单是 5,直接收下。
- 情况二:账单是 10,消耗一个 5,增加一个 10
- 情况三:账单是 20,优先消耗一个 10 和一个 5,如果不够,再消耗三个 5
此时大家就发现 情况一,情况二,都是固定策略,都不用我们来做分析了,而唯一不确定的其实在情况三。
而情况三逻辑也不复杂甚至感觉纯模拟就可以了,其实情况三这里是有贪心的。
账单是 20 的情况,为什么要优先消耗一个 10 和一个 5 呢?
因为美元 10 只能给账单 20 找零,而美元 5 可以给账单 10 和账单 20 找零,美元 5 更万能!
所以局部最优:遇到账单 20,优先消耗美元 10,完成本次找零。全局最优:完成全部账单的找零。
局部最优可以推出全局最优,并找不出反例,那么就试试贪心算法!
class Solution {
public:
bool lemonadeChange(vector<int>& bills) {
int five = 0, ten = 0, twenty = 0;
for (int bill : bills) {
// 情况一
if (bill == 5) five++;
// 情况二
if (bill == 10) {
if (five <= 0) return false;
ten++;
five--;
}
// 情况三
if (bill == 20) {
// 优先消耗10美元,因为5美元的找零用处更大,能多留着就多留着
if (five > 0 && ten > 0) {
five--;
ten--;
twenty++; // 其实这行代码可以删了,因为记录20已经没有意义了,不会用20来找零
} else if (five >= 3) {
five -= 3;
twenty++; // 同理,这行代码也可以删了
} else return false;
}
}
return true;
}
};
时间复杂度: O(n)
空间复杂度: O(1)
406.根据身高重建队列
假设有打乱顺序的一群人站成一个队列,数组 people 表示队列中一些人的属性(不一定按顺序)。每个 people[i] = [hi, ki] 表示第 i 个人的身高为 hi ,前面 正好 有 ki 个身高大于或等于 hi 的人。
请你重新构造并返回输入数组 people 所表示的队列。返回的队列应该格式化为数组 queue ,其中 queue[j] = [hj, kj] 是队列中第 j 个人的属性(queue[0] 是排在队列前面的人)。
示例 1:
输入:people = [[7,0],[4,4],[7,1],[5,0],[6,1],[5,2]]
输出:[[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]]
解释:
编号为 0 的人身高为 5 ,没有身高更高或者相同的人排在他前面。
编号为 1 的人身高为 7 ,没有身高更高或者相同的人排在他前面。
编号为 2 的人身高为 5 ,有 2 个身高更高或者相同的人排在他前面,即编号为 0 和 1 的人。
编号为 3 的人身高为 6 ,有 1 个身高更高或者相同的人排在他前面,即编号为 1 的人。
编号为 4 的人身高为 4 ,有 4 个身高更高或者相同的人排在他前面,即编号为 0、1、2、3 的人。
编号为 5 的人身高为 7 ,有 1 个身高更高或者相同的人排在他前面,即编号为 1 的人。
因此 [[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]] 是重新构造后的队列。
提示:
1 <= people.length <= 2000
0 <= hi <= 10^6
0 <= ki < people.length
题目数据确保队列可以被重建
本题有两个维度,h 和 k,看到这种题目一定要想如何确定一个维度,然后再按照另一个维度重新排列。
如果两个维度一起考虑一定会顾此失彼。
对于本题相信大家困惑的点是先确定 k 还是先确定 h 呢,也就是究竟先按 h 排序呢,还是先按照 k 排序呢?
如果按照 k 来从小到大排序,排完之后,会发现 k 的排列并不符合条件,身高也不符合条件,两个维度哪一个都没确定下来。
那么按照身高 h 来排序呢,身高一定是从大到小排(身高相同的话则 k 小的站前面),让高个子在前面。
此时我们可以确定一个维度了,就是身高,前面的节点一定都比本节点高!
那么只需要按照 k 为下标重新插入队列就可以了,为什么呢?
以图中{5,2} 为例:

按照身高排序之后,优先按身高高的 people 的 k 来插入,后序插入节点也不会影响前面已经插入的节点,最终按照 k 的规则完成了队列。
所以在按照身高从大到小排序后:
局部最优:优先按身高高的 people 的 k 来插入。插入操作过后的 people 满足队列属性
全局最优:最后都做完插入操作,整个队列满足题目队列属性
局部最优可推出全局最优,找不出反例,那就试试贪心。
回归本题,整个插入过程如下:
排序完的 people: [[7,0], [7,1], [6,1], [5,0], [5,2],[4,4]]
插入的过程:
- 插入[7,0]:[[7,0]]
- 插入[7,1]:[[7,0],[7,1]]
- 插入[6,1]:[[7,0],[6,1],[7,1]]
- 插入[5,0]:[[5,0],[7,0],[6,1],[7,1]]
- 插入[5,2]:[[5,0],[7,0],[5,2],[6,1],[7,1]]
- 插入[4,4]:[[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]]
此时就按照题目的要求完成了重新排列。
// 版本一
class Solution {
public:
static bool cmp(const vector<int>& a, const vector<int>& b) {
if (a[0] == b[0]) return a[1] < b[1];
return a[0] > b[0];
}
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
sort (people.begin(), people.end(), cmp);
vector<vector<int>> que;
for (int i = 0; i < people.size(); i++) {
int position = people[i][1];
que.insert(que.begin() + position, people[i]);
}
return que;
}
};
时间复杂度:O(nlog n + n^2)
空间复杂度:O(n)
C++的vector在底层扩容操作是会构建一个新的长度为原来2倍的数组,然后全体拷贝过去,所以时间复杂度是n^2
class Solution {
public:
// 身高从大到小排(身高相同k小的站前面)
static bool cmp(const vector<int> a, const vector<int> b) {
if (a[0] == b[0]) return a[1] < b[1];
return a[0] > b[0];
}
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
sort (people.begin(), people.end(), cmp);
list<vector<int>> que; // list底层是链表实现,插入效率比vector高的多
for (int i = 0; i < people.size(); i++) {
int position = people[i][1]; // 插入到下标为position的位置
std::list<vector<int>>::iterator it = que.begin();
while (position--) { // 寻找在插入位置
it++;
}
que.insert(it, people[i]);
}
return vector<vector<int>>(que.begin(), que.end());
}
};
用链表实现,insert的时间复杂度就是O(1)了,但是找到插入位置还是有O(n)
452. 用最少数量的箭引爆气球
在二维空间中有许多球形的气球。对于每个气球,提供的输入是水平方向上,气球直径的开始和结束坐标。由于它是水平的,所以纵坐标并不重要,因此只要知道开始和结束的横坐标就足够了。开始坐标总是小于结束坐标。
一支弓箭可以沿着 x 轴从不同点完全垂直地射出。在坐标 x 处射出一支箭,若有一个气球的直径的开始和结束坐标为 xstart,xend, 且满足 xstart ≤ x ≤ xend,则该气球会被引爆。可以射出的弓箭的数量没有限制。 弓箭一旦被射出之后,可以无限地前进。我们想找到使得所有气球全部被引爆,所需的弓箭的最小数量。
给你一个数组 points ,其中 points [i] = [xstart,xend] ,返回引爆所有气球所必须射出的最小弓箭数。
示例 1:
输入:points = [[10,16],[2,8],[1,6],[7,12]]
输出:2
解释:对于该样例,x = 6 可以射爆 [2,8],[1,6] 两个气球,以及 x = 11 射爆另外两个气球
提示:
0 <= points.length <= 10^4
points[i].length == 2
-2^31 <= xstart < xend <= 2^31 - 1
如果把气球排序之后,从前到后遍历气球,被射过的气球仅仅跳过就行了,没有必要让气球数组 remove 气球,只要记录一下箭的数量就可以了。
以上为思考过程,已经确定下来使用贪心了,那么开始解题。
为了让气球尽可能的重叠,需要对数组进行排序。
那么按照气球起始位置排序,还是按照气球终止位置排序呢?
其实都可以!只不过对应的遍历顺序不同,我就按照气球的起始位置排序了。
既然按照起始位置排序,那么就从前向后遍历气球数组,靠左尽可能让气球重复。
从前向后遍历遇到重叠的气球了怎么办?
如果气球重叠了,重叠气球中右边边界的最小值 之前的区间一定需要一个弓箭。
以题目示例: [[10,16],[2,8],[1,6],[7,12]]为例,如图:(方便起见,已经排序)
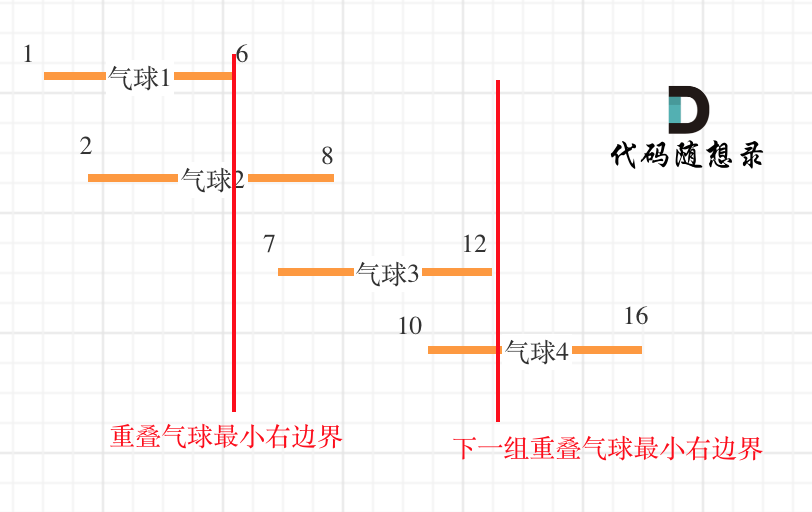
可以看出首先第一组重叠气球,一定是需要一个箭,气球 3,的左边界大于了 第一组重叠气球的最小右边界,所以再需要一支箭来射气球 3 了。
class Solution {
private:
static bool cmp(const vector<int>& a, const vector<int>& b) {
return a[0] < b[0];
}
public:
int findMinArrowShots(vector<vector<int>>& points) {
if (points.size() == 0) return 0;
sort(points.begin(), points.end(), cmp);
int result = 1; // points 不为空至少需要一支箭
for (int i = 1; i < points.size(); i++) {
if (points[i][0] > points[i - 1][1]) { // 气球i和气球i-1不挨着,注意这里不是>=
result++; // 需要一支箭
}
else { // 气球i和气球i-1挨着
points[i][1] = min(points[i - 1][1], points[i][1]); // 更新重叠气球最小右边界
}
}
return result;
}
};
时间复杂度:O(nlog n),因为有一个快排
空间复杂度:O(1),有一个快排,最差情况(倒序)时,需要n次递归调用。因此确实需要O(n)的栈空间
435. 无重叠区间
给定一个区间的集合,找到需要移除区间的最小数量,使剩余区间互不重叠。
注意: 可以认为区间的终点总是大于它的起点。 区间 [1,2] 和 [2,3] 的边界相互“接触”,但没有相互重叠。
示例 1:
输入: [ [1,2], [2,3], [3,4], [1,3] ]
输出: 1
解释: 移除 [1,3] 后,剩下的区间没有重叠。
相信很多同学看到这道题目都冥冥之中感觉要排序,但是究竟是按照右边界排序,还是按照左边界排序呢?
其实都可以。主要就是为了让区间尽可能的重叠。
我来按照右边界排序,从左向右记录非交叉区间的个数。最后用区间总数减去非交叉区间的个数就是需要移除的区间个数了。
此时问题就是要求非交叉区间的最大个数。
这里记录非交叉区间的个数还是有技巧的,如图:

区间,1,2,3,4,5,6 都按照右边界排好序。
当确定区间 1 和 区间 2 重叠后,如何确定是否与 区间 3 也重贴呢?
就是取 区间 1 和 区间 2 右边界的最小值,因为这个最小值之前的部分一定是 区间 1 和区间 2 的重合部分,如果这个最小值也触达到区间 3,那么说明 区间 1,2,3 都是重合的。
接下来就是找大于区间 1 结束位置的区间,是从区间 4 开始。那有同学问了为什么不从区间 5 开始?别忘了已经是按照右边界排序的了。
区间 4 结束之后,再找到区间 6,所以一共记录非交叉区间的个数是三个。
总共区间个数为 6,减去非交叉区间的个数 3。移除区间的最小数量就是 3。
class Solution {
public:
// 按照区间右边界排序
static bool cmp (const vector<int>& a, const vector<int>& b) {
return a[1] < b[1];
}
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
if (intervals.size() == 0) return 0;
sort(intervals.begin(), intervals.end(), cmp);
int count = 1; // 记录非交叉区间的个数
int end = intervals[0][1]; // 记录区间分割点
for (int i = 1; i < intervals.size(); i++) {
if (end <= intervals[i][0]) {
end = intervals[i][1];
count++;
}
}
return intervals.size() - count;
}
};
时间复杂度:O(nlog n) ,有一个快排
空间复杂度:O(n),有一个快排,最差情况(倒序)时,需要n次递归调用。因此确实需要O(n)的栈空间
763.划分字母区间
字符串 S 由小写字母组成。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。返回一个表示每个字符串片段的长度的列表。
示例:
输入:S = "ababcbacadefegdehijhklij"
输出:[9,7,8]
解释: 划分结果为 "ababcbaca", "defegde", "hijhklij"。 每个字母最多出现在一个片段中。 像 "ababcbacadefegde", "hijhklij" 的划分是错误的,因为划分的片段数较少。
提示:
S的长度在[1, 500]之间。
S只包含小写字母 'a' 到 'z' 。
题目要求同一字母最多出现在一个片段中,那么如何把同一个字母的都圈在同一个区间里呢?
如果没有接触过这种题目的话,还挺有难度的。
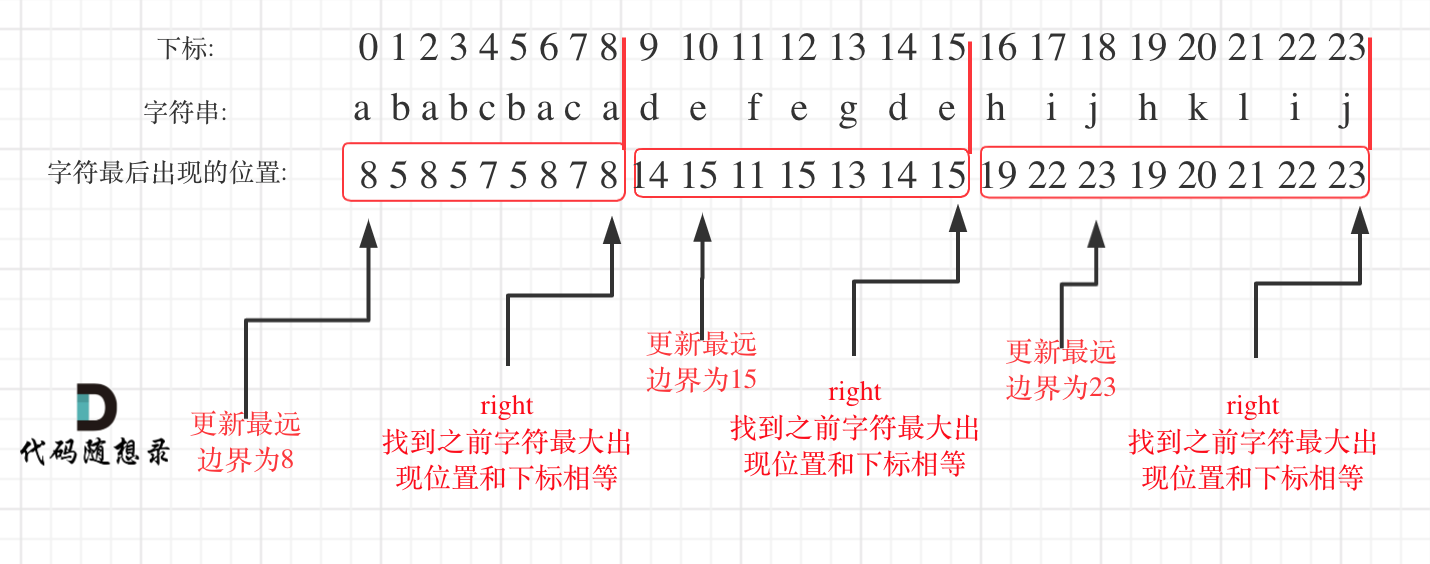
在遍历的过程中相当于是要找每一个字母的边界,如果找到之前遍历过的所有字母的最远边界,说明这个边界就是分割点了。此时前面出现过所有字母,最远也就到这个边界了。
可以分为如下两步:
- 统计每一个字符最后出现的位置
- 从头遍历字符,并更新字符的最远出现下标,如果找到字符最远出现位置下标和当前下标相等了,则找到了分割点
class Solution {
public:
vector<int> partitionLabels(string S) {
int hash[27] = {0}; // i为字符,hash[i]为字符出现的最后位置
for (int i = 0; i < S.size(); i++) { // 统计每一个字符最后出现的位置
hash[S[i] - 'a'] = i;
}
vector<int> result;
int left = 0;
int right = 0;
for (int i = 0; i < S.size(); i++) {
right = max(right, hash[S[i] - 'a']); // 找到字符出现的最远边界
if (i == right) {
result.push_back(right - left + 1);
left = i + 1;
}
}
return result;
}
};
时间复杂度:O(n)
空间复杂度:O(1),使用的hash数组是固定大小
56. 合并区间
给出一个区间的集合,请合并所有重叠的区间。
示例 1:
输入: intervals = [[1,3],[2,6],[8,10],[15,18]]
输出: [[1,6],[8,10],[15,18]]
解释: 区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
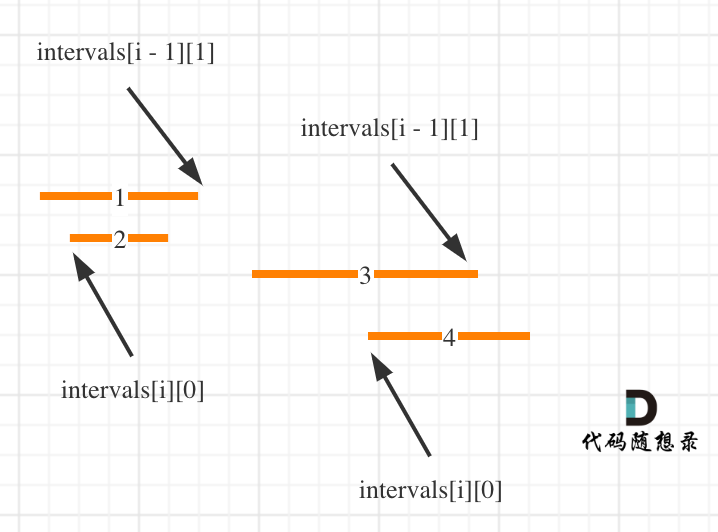
先排序,让所有的相邻区间尽可能的重叠在一起,按左边界,或者右边界排序都可以,处理逻辑稍有不同。
按照左边界从小到大排序之后,如果 intervals[i][0] <= intervals[i - 1][1] 即 intervals[i]的左边界 <= intervals[i - 1]的右边界,则一定有重叠。(本题相邻区间也算重贴,所以是<=)
class Solution {
public:
vector<vector<int>> merge(vector<vector<int>>& intervals) {
vector<vector<int>> result;
if (intervals.size() == 0) return result; // 区间集合为空直接返回
// 排序的参数使用了lambda表达式
sort(intervals.begin(), intervals.end(), [](const vector<int>& a, const vector<int>& b){return a[0] < b[0];});
// 第一个区间就可以放进结果集里,后面如果重叠,在result上直接合并
result.push_back(intervals[0]);
for (int i = 1; i < intervals.size(); i++) {
if (result.back()[1] >= intervals[i][0]) { // 发现重叠区间
// 合并区间,只更新右边界就好,因为result.back()的左边界一定是最小值,因为我们按照左边界排序的
result.back()[1] = max(result.back()[1], intervals[i][1]);
} else {
result.push_back(intervals[i]); // 区间不重叠
}
}
return result;
}
};
时间复杂度: O(nlogn)
空间复杂度: O(logn),排序需要的空间开销
738.单调递增的数字
给定一个非负整数 N,找出小于或等于 N 的最大的整数,同时这个整数需要满足其各个位数上的数字是单调递增。
(当且仅当每个相邻位数上的数字 x 和 y 满足 x <= y 时,我们称这个整数是单调递增的。)
示例 1:
输入: N = 10
输出: 9
示例 2:
输入: N = 1234
输出: 1234
说明: N 是在 [0, 10^9] 范围内的一个整数。
题目要求小于等于 N 的最大单调递增的整数,那么拿一个两位的数字来举例。
例如:98,一旦出现 strNum[i - 1] > strNum[i]的情况(非单调递增),首先想让 strNum[i - 1]–,然后 strNum[i]给为 9,这样这个整数就是 89,即小于 98 的最大的单调递增整数。
这一点如果想清楚了,这道题就好办了。
此时是从前向后遍历还是从后向前遍历呢?
从前向后遍历的话,遇到 strNum[i - 1] > strNum[i]的情况,让 strNum[i - 1]减一,但此时如果 strNum[i - 1]减一了,可能又小于 strNum[i - 2]。
这么说有点抽象,举个例子,数字:332,从前向后遍历的话,那么就把变成了 329,此时 2 又小于了第一位的 3 了,真正的结果应该是 299。
那么从后向前遍历,就可以重复利用上次比较得出的结果了,从后向前遍历 332 的数值变化为:332 -> 329 -> 299
确定了遍历顺序之后,那么此时局部最优就可以推出全局,找不出反例,试试贪心。
class Solution {
public:
int monotoneIncreasingDigits(int N) {
string strNum = to_string(N);
// flag用来标记赋值9从哪里开始
// 设置为这个默认值,为了防止第二个for循环在flag没有被赋值的情况下执行
int flag = strNum.size();
for (int i = strNum.size() - 1; i > 0; i--) {
if (strNum[i - 1] > strNum[i] ) {
flag = i;
strNum[i - 1]--;
}
}
for (int i = flag; i < strNum.size(); i++) {
strNum[i] = '9';
}
return stoi(strNum);
}
};
时间复杂度:O(n),n 为数字长度
空间复杂度:O(n),需要一个字符串,转化为字符串操作更方便
968.监控二叉树
给定一个二叉树,我们在树的节点上安装摄像头。
节点上的每个摄影头都可以监视其父对象、自身及其直接子对象。
计算监控树的所有节点所需的最小摄像头数量。
提示:
给定树的节点数的范围是 [1, 1000]。
每个节点的值都是 0。
示例 1:

- 输入:[0,0,null,0,0]
- 输出:1
- 解释:如图所示,一台摄像头足以监控所有节点。
这道题目首先要想,如何放置,才能让摄像头最小的呢?
从题目中示例,其实可以得到启发,我们发现题目示例中的摄像头都没有放在叶子节点上!
这是很重要的一个线索,摄像头可以覆盖上中下三层,如果把摄像头放在叶子节点上,就浪费的一层的覆盖。
所以把摄像头放在叶子节点的父节点位置,才能充分利用摄像头的覆盖面积。
那么有同学可能问了,为什么不从头结点开始看起呢,为啥要从叶子节点看呢?
因为头结点放不放摄像头也就省下一个摄像头, 叶子节点放不放摄像头省下了的摄像头数量是指数阶别的。
所以我们要从下往上看,局部最优:让叶子节点的父节点安摄像头,所用摄像头最少,整体最优:全部摄像头数量所用最少!
局部最优推出全局最优,找不出反例,那么就按照贪心来!
此时,大体思路就是从低到上,先给叶子节点父节点放个摄像头,然后隔两个节点放一个摄像头,直至到二叉树头结点。
此时这道题目还有两个难点:
- 二叉树的遍历
- 如何隔两个节点放一个摄像头
对于遍历顺序来说,可以使用后序遍历也就是左右中的顺序,这样就可以在回溯的过程中从下到上进行推导了。
int traversal(TreeNode* cur) {
// 空节点,该节点有覆盖
if (终止条件) return ;
int left = traversal(cur->left); // 左
int right = traversal(cur->right); // 右
逻辑处理 // 中
return ;
}
注意在以上代码中我们取了左孩子的返回值,右孩子的返回值,即 left 和 right, 以后推导中间节点的状态
对于如何隔两个节点防止一个摄像头来说,此时需要状态转移的公式,大家不要和动态的状态转移公式混到一起,本题状态转移没有择优的过程,就是单纯的状态转移!
来看看这个状态应该如何转移,先来看看每个节点可能有几种状态:
有如下三种:
- 该节点无覆盖
- 本节点有摄像头
- 本节点有覆盖
我们分别有三个数字来表示:
- 0:该节点无覆盖
- 1:本节点有摄像头
- 2:本节点有覆盖
因为在遍历树的过程中,就会遇到空节点,那么问题来了,空节点究竟是哪一种状态呢? 空节点表示无覆盖? 表示有摄像头?还是有覆盖呢?
回归本质,为了让摄像头数量最少,我们要尽量让叶子节点的父节点安装摄像头,这样才能摄像头的数量最少。
那么空节点不能是无覆盖的状态,这样叶子节点就要放摄像头了,空节点也不能是有摄像头的状态,这样叶子节点的父节点就没有必要放摄像头了,而是可以把摄像头放在叶子节点的爷爷节点上。
所以空节点的状态只能是有覆盖,这样就可以在叶子节点的父节点放摄像头了,所以终止条件就是节点 == NULL 返回 2
单层处理逻辑:
- 情况 1:左右节点都有覆盖
左孩子有覆盖,右孩子有覆盖,那么此时中间节点应该就是无覆盖的状态了。
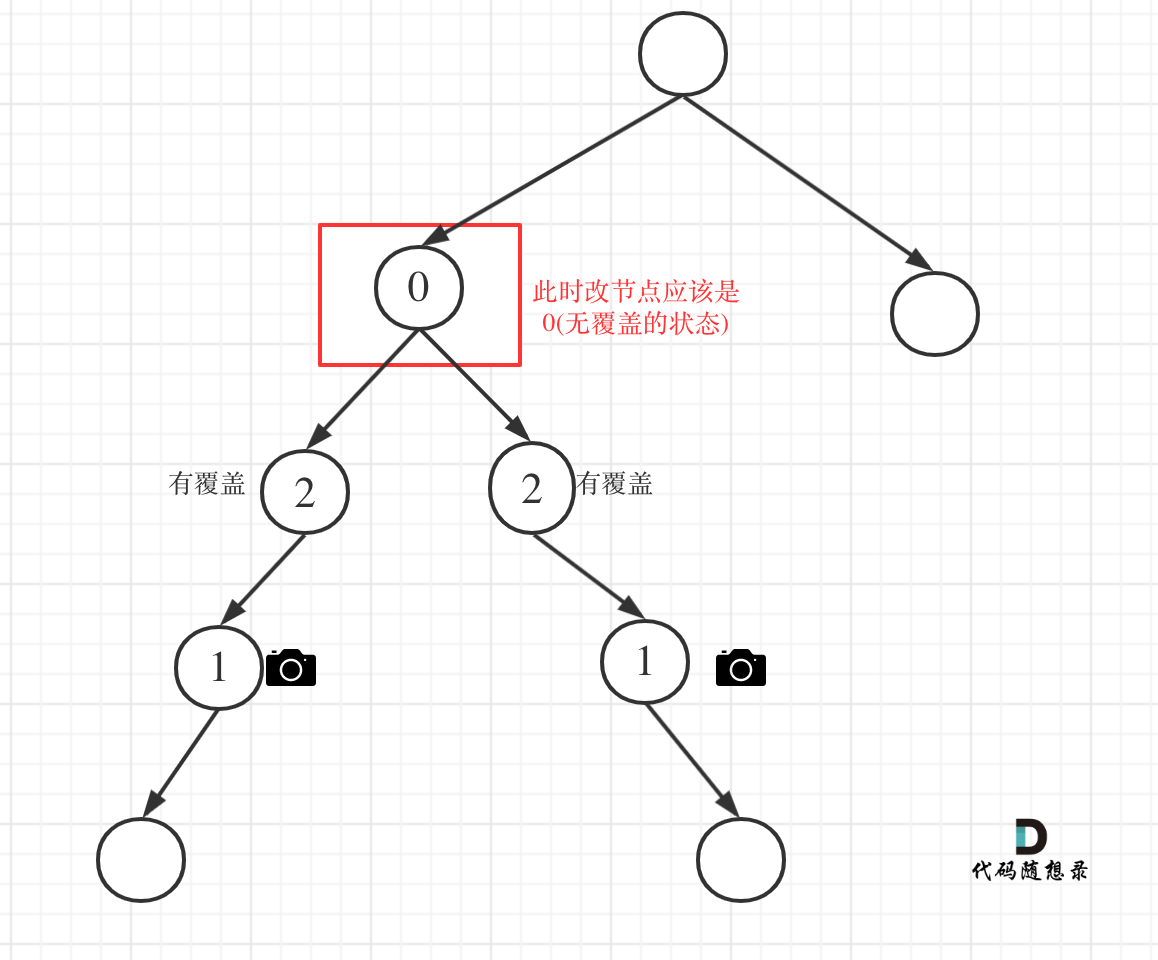
if (left == 2 && right == 2) return 0;
- 情况 2:左右节点至少有一个无覆盖的情况
如果是以下情况,则中间节点(父节点)应该放摄像头:
- left == 0 && right == 0 左右节点无覆盖
- left == 1 && right == 0 左节点有摄像头,右节点无覆盖
- left == 0 && right == 1 左节点有无覆盖,右节点摄像头
- left == 0 && right == 2 左节点无覆盖,右节点覆盖
- left == 2 && right == 0 左节点覆盖,右节点无覆盖
这个不难理解,毕竟有一个孩子没有覆盖,父节点就应该放摄像头。
此时摄像头的数量要加一,并且 return 1,代表中间节点放摄像头。
代码如下:
if (left == 0 || right == 0) {
result++;
return 1;
}
- 情况 3:左右节点至少有一个有摄像头
如果是以下情况,其实就是 左右孩子节点有一个有摄像头了,那么其父节点就应该是 2(覆盖的状态)
- left == 1 && right == 2 左节点有摄像头,右节点有覆盖
- left == 2 && right == 1 左节点有覆盖,右节点有摄像头
- left == 1 && right == 1 左右节点都有摄像头
代码如下:
if (left == 1 || right == 1) return 2;
- 情况 4:头结点没有覆盖
以上都处理完了,递归结束之后,可能头结点 还有一个无覆盖的情况,如图:
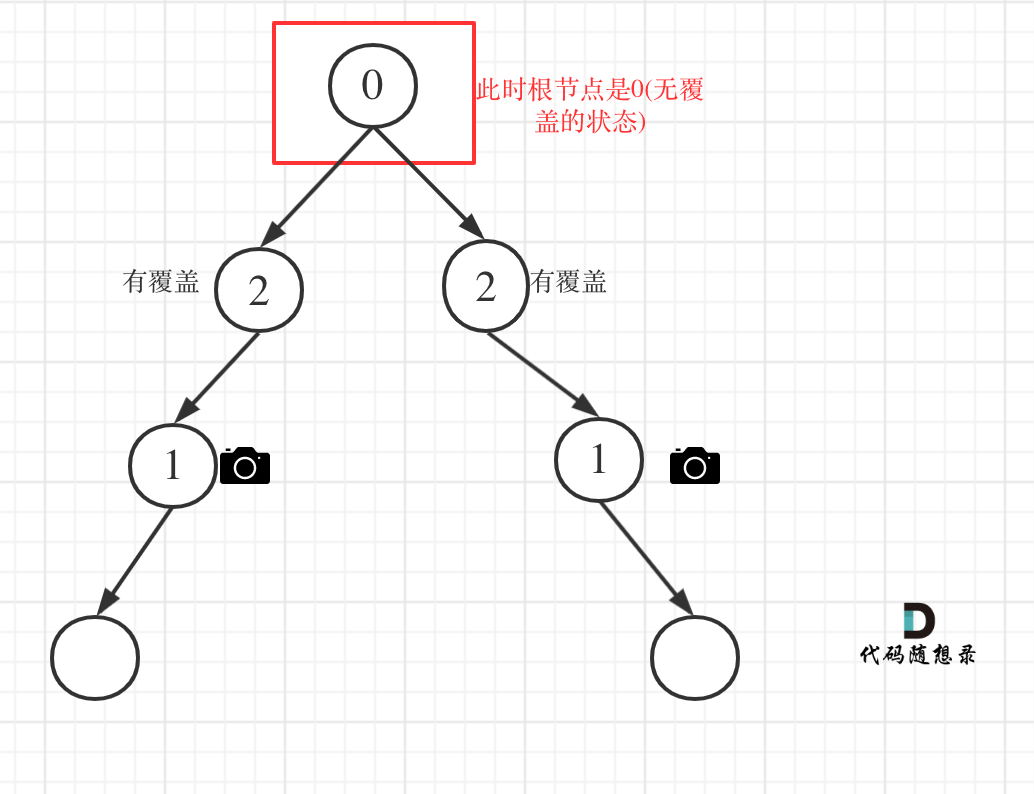
所以递归结束之后,还要判断根节点,如果没有覆盖,result++,代码如下:
int minCameraCover(TreeNode* root) {
result = 0;
if (traversal(root) == 0) { // root 无覆盖
result++;
}
return result;
}
class Solution {
private:
int result;
int traversal(TreeNode* cur) {
// 空节点,该节点有覆盖
if (cur == NULL) return 2;
int left = traversal(cur->left); // 左
int right = traversal(cur->right); // 右
// 情况1
// 左右节点都有覆盖
if (left == 2 && right == 2) return 0;
// 情况2
// left == 0 && right == 0 左右节点无覆盖
// left == 1 && right == 0 左节点有摄像头,右节点无覆盖
// left == 0 && right == 1 左节点有无覆盖,右节点摄像头
// left == 0 && right == 2 左节点无覆盖,右节点覆盖
// left == 2 && right == 0 左节点覆盖,右节点无覆盖
if (left == 0 || right == 0) {
result++;
return 1;
}
// 情况3
// left == 1 && right == 2 左节点有摄像头,右节点有覆盖
// left == 2 && right == 1 左节点有覆盖,右节点有摄像头
// left == 1 && right == 1 左右节点都有摄像头
// 其他情况前段代码均已覆盖
if (left == 1 || right == 1) return 2;
// 以上代码我没有使用else,主要是为了把各个分支条件展现出来,这样代码有助于读者理解
// 这个 return -1 逻辑不会走到这里。
return -1;
}
public:
int minCameraCover(TreeNode* root) {
result = 0;
// 情况4
if (traversal(root) == 0) { // root 无覆盖
result++;
}
return result;
}
};
时间复杂度: O(n),需要遍历二叉树上的每个节点
空间复杂度: O(n)