题目:
你有一个保存员工信息的数据结构,它包含了员工唯一的 id ,重要度和直系下属的 id 。
给定一个员工数组 employees,其中:
employees[i].id是第i个员工的 ID。employees[i].importance是第i个员工的重要度。employees[i].subordinates是第i名员工的直接下属的 ID 列表。
给定一个整数 id 表示一个员工的 ID,返回这个员工和他所有下属的重要度的 总和。
示例 1:
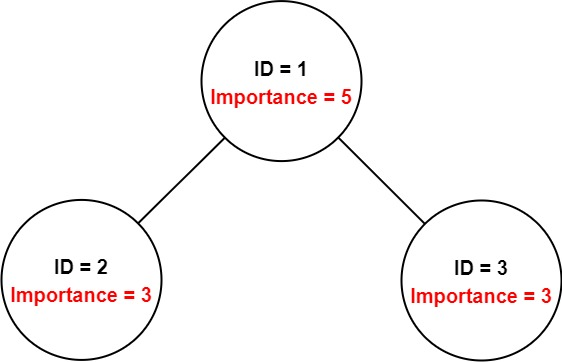
输入:employees = [[1,5,[2,3]],[2,3,[]],[3,3,[]]], id = 1
输出:11
解释:
员工 1 自身的重要度是 5 ,他有两个直系下属 2 和 3 ,而且 2 和 3 的重要度均为 3 。因此员工 1 的总重要度是 5 + 3 + 3 = 11 。
示例 2:
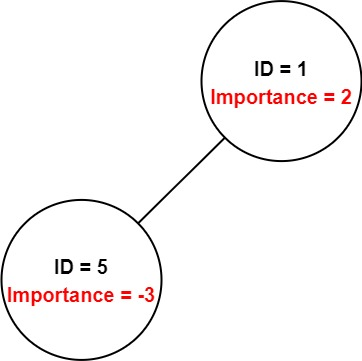
输入:employees = [[1,2,[5]],[5,-3,[]]], id = 5
输出:-3
解释:员工 5 的重要度为 -3 并且没有直接下属。
因此,员工 5 的总重要度为 -3。
提示:
1 <= employees.length <= 20001 <= employees[i].id <= 2000- 所有的
employees[i].id互不相同。 -100 <= employees[i].importance <= 100- 一名员工最多有一名直接领导,并可能有多名下属。
employees[i].subordinates中的 ID 都有效。
思路:
先将 员工ID 和 employees 索引做好映射
然后直接用广度优先搜索直接得结果
代码:
/*
// Definition for Employee.
class Employee {
public:
int id;
int importance;
vector<int> subordinates;
};
*/
class Solution {
public:
int getImportance(vector<Employee*> employees, int id) {
// ID 映射 emplyees 索引
unordered_map<int, int> hash;
for (int i = 0; i < employees.size(); i++) {
hash[employees[i]->id] = i;
}
// 广度优先搜索
int ans = 0;
queue<int> que;
que.push(id);
while (!que.empty()) {
int topId = que.front();
que.pop();
int idx = hash[topId];
ans += employees[idx]->importance;
for (int i = 0; i < employees[idx]->subordinates.size(); i++) {
que.push(employees[idx]->subordinates[i]);
}
}
return ans;
}
};