题目:
给定一个列表 accounts,每个元素 accounts[i] 是一个字符串列表,其中第一个元素 accounts[i][0] 是 名称 (name),其余元素是 emails 表示该账户的邮箱地址。
现在,我们想合并这些账户。如果两个账户都有一些共同的邮箱地址,则两个账户必定属于同一个人。请注意,即使两个账户具有相同的名称,它们也可能属于不同的人,因为人们可能具有相同的名称。一个人最初可以拥有任意数量的账户,但其所有账户都具有相同的名称。
合并账户后,按以下格式返回账户:每个账户的第一个元素是名称,其余元素是 按字符 ASCII 顺序排列 的邮箱地址。账户本身可以以 任意顺序 返回。
示例 1:
输入:accounts = [["John", "johnsmith@mail.com", "john00@mail.com"], ["John", "johnnybravo@mail.com"], ["John", "johnsmith@mail.com", "john_newyork@mail.com"], ["Mary", "mary@mail.com"]]
输出:[["John", 'john00@mail.com', 'john_newyork@mail.com', 'johnsmith@mail.com'], ["John", "johnnybravo@mail.com"], ["Mary", "mary@mail.com"]]
解释:
第一个和第三个 John 是同一个人,因为他们有共同的邮箱地址 "johnsmith@mail.com"。
第二个 John 和 Mary 是不同的人,因为他们的邮箱地址没有被其他帐户使用。
可以以任何顺序返回这些列表,例如答案 [['Mary','mary@mail.com'],['John','johnnybravo@mail.com'],
['John','john00@mail.com','john_newyork@mail.com','johnsmith@mail.com']] 也是正确的。
示例 2:
输入:accounts = [["Gabe","Gabe0@m.co","Gabe3@m.co","Gabe1@m.co"],["Kevin","Kevin3@m.co","Kevin5@m.co","Kevin0@m.co"],["Ethan","Ethan5@m.co","Ethan4@m.co","Ethan0@m.co"],["Hanzo","Hanzo3@m.co","Hanzo1@m.co","Hanzo0@m.co"],["Fern","Fern5@m.co","Fern1@m.co","Fern0@m.co"]]
输出:[["Ethan","Ethan0@m.co","Ethan4@m.co","Ethan5@m.co"],["Gabe","Gabe0@m.co","Gabe1@m.co","Gabe3@m.co"],["Hanzo","Hanzo0@m.co","Hanzo1@m.co","Hanzo3@m.co"],["Kevin","Kevin0@m.co","Kevin3@m.co","Kevin5@m.co"],["Fern","Fern0@m.co","Fern1@m.co","Fern5@m.co"]]
提示:
1 <= accounts.length <= 10002 <= accounts[i].length <= 101 <= accounts[i][j].length <= 30accounts[i][0]由英文字母组成accounts[i][j] (for j > 0)是有效的邮箱地址
思路:
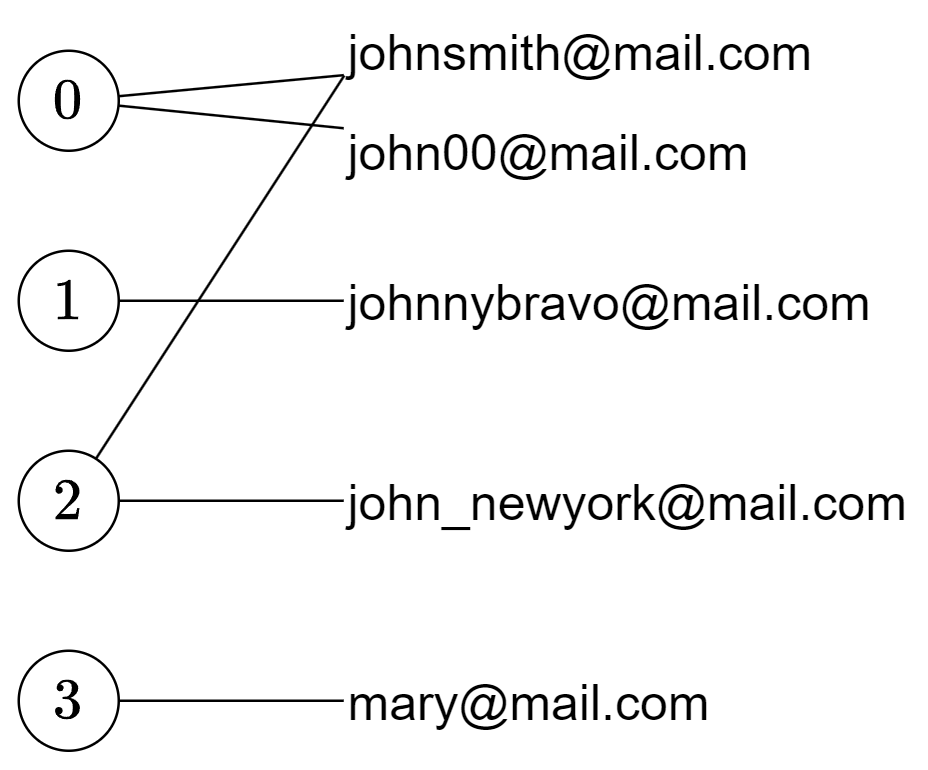
看示例 1,把每个账户用其在 accounts 中的下标表示,即节点 0 到 3。同时,把每个账户的邮箱地址,也视作节点。我们在账户下标与其邮箱地址之间连边,得到一个无向图(二分图)。
题目相当于求出这个图的每个连通块,这可以用 DFS 解决。
算法
把 accounts 中的信息提取到哈希表 emailToIdx 中,key 为邮箱地址,value 为这个邮箱对应的账户下标列表。
初始化一个长为 n 的全为 false 的布尔数组 vis,用来标记访问过的账户下标。
遍历 vis,如果 i 没有访问过,即 vis[i]=false,则从 i 开始 DFS。
DFS 之前,创建一个哈希集合 emails,用来保存 DFS 中访问到的邮箱地址。
开始 DFS。首先标记 vis[i]=true。
遍历 accounts[i] 的邮箱地址 email。
如果 email 在哈希集合 emails 中,则跳过;否则把 email 加入哈希集合 emails。
遍历 emailToIdx[email],也就是所有包含该邮箱地址的账户下标 j,如果 j 没有访问过,即 vis[j]=false,则继续 DFS j。
DFS 结束后,把 emails 中的元素按照字典序从小到大排序,然后和 accounts[i][0] 一起加入答案。
代码:
class Solution {
public:
vector<vector<string>> accountsMerge(vector<vector<string>>& accounts) {
unordered_map<string, vector<int>> email_to_idx;
for (int i = 0; i < accounts.size(); i++) {
for (int k = 1; k < accounts[i].size(); k++) {
email_to_idx[accounts[i][k]].push_back(i);
}
}
unordered_set<string> email_set; // 用于收集 DFS 中访问到的邮箱地址
vector<int> vis(accounts.size());
auto dfs = [&](auto&& dfs, int i) -> void {
vis[i] = true;
for (int k = 1; k < accounts[i].size(); k++) {
string& email = accounts[i][k];
if (email_set.contains(email)) {
continue;
}
email_set.insert(email);
for (int j : email_to_idx[email]) { // 遍历所有包含该邮箱地址的账户下标 j
if (!vis[j]) { // j 没有访问过
dfs(dfs, j);
}
}
}
};
vector<vector<string>> ans;
for (int i = 0; i < vis.size(); i++) {
if (vis[i]) {
continue;
}
email_set.clear();
dfs(dfs, i);
vector<string> res = {accounts[i][0]};
res.insert(res.end(), email_set.begin(), email_set.end());
sort(res.begin() + 1, res.end());
ans.push_back(res);
}
return ans;
}
};