题目:
给你一个下标从 0 开始的整数数组 nums ,它包含 n 个 互不相同 的正整数。如果 nums 的一个排列满足以下条件,我们称它是一个特别的排列:
- 对于
0 <= i < n - 1的下标i,要么nums[i] % nums[i+1] == 0,要么nums[i+1] % nums[i] == 0。
请你返回特别排列的总数目,由于答案可能很大,请将它对 109 + 7 取余 后返回。
示例 1:
输入:nums = [2,3,6]
输出:2
解释:[3,6,2] 和 [2,6,3] 是 nums 两个特别的排列。
示例 2:
输入:nums = [1,4,3]
输出:2
解释:[3,1,4] 和 [4,1,3] 是 nums 两个特别的排列。
提示:
2 <= nums.length <= 141 <= nums[i] <= 109
暴力回溯
思路:
如果没有特别的排列限制,那其实这就是一道全排列的题,找出所有的排列组合的可能性,自然是需要回溯的思路,因为第i个位置可以选择任何还没有被选择的数。
回溯的思路:先枚举第i个位置的数,再继续枚举i+1个位置可以选哪个 还没有被选择的数。
但是由于题意中加了限制,第i个数nums[i]加入排列中时,必须满足nums[i-1] % nums[i] == 0 || nums[i] % nums[i-1] == 0条件,所以我们需要在回溯中提前检测,如果不满足这个条件的就不用再往后枚举了。
为了检测是否满足条件,我们需要把第i-1个数传下去进行检测。
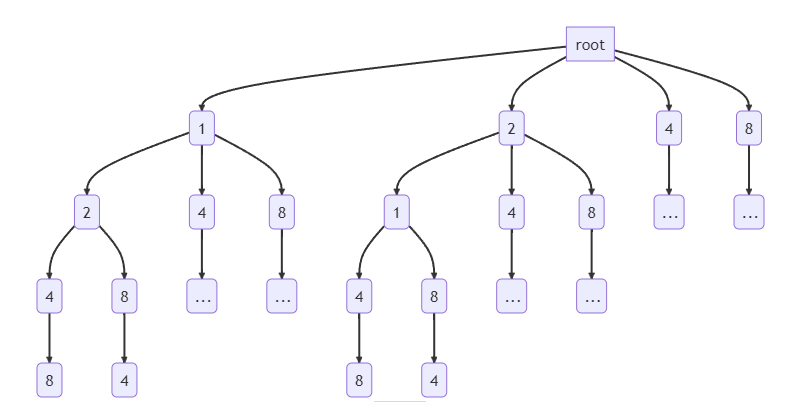
整个思路其实就是下图,搜索/回溯 总是以树分叉的形式表现出来,体现出选与不选、选哪个的思想。假设数组为[1,2,4,8],时间复杂度:第一层有4个元素,第二层可以选4*3个元素,...,第n层 就有n!个元素所以时间复杂度为O(N!)
代码:
class Solution {
public int specialPerm(int[] nums) {
boolean[] visited = new boolean[nums.length];
return dfs(nums, 0, -1, visited);
}
// dfs(depth, prevPos) 定义为: 0到第depth个位置的特殊排列最后一位下标为prevPos 的特殊排列的总数目。
private int dfs(int[] nums, int depth, int prevPos, boolean[] visited) {
// 如果能枚举完整个数组,意味着这个排列是满足条件的特殊排列,那么返回一种方案
if(depth == nums.length) {
return 1;
}
int res = 0;
for(int i = 0; i < nums.length; i++) {
if(!visited[i]) {
// 第0个数不需要考虑是否满足条件
if (prevPos == -1 || nums[prevPos] % nums[i] == 0 || nums[i] % nums[prevPos] == 0) {
visited[i] = true;
res = (res + dfs(nums, depth + 1, i, visited)) % 1000000007;
visited[i] = false;
}
}
}
return res;
}
}
记忆化搜索优化
思路:
暴力回溯虽然是正确的,但是时间复杂度太高了,14! 就等于 1278945280。
仔细观察上图,就会发现有重复子问题的存在,比如从第一层到第三层,有[1, 2, 4]的选择,也有[2, 1, 4]的选择。题目中告诉我们数组中的数是互不相同的,那所以无论这个数组有多大,[1, 2, 4] 和[2, 1, 4] 后面可以选择的数都是相同的,那组合的可能性也是必然相同的。所以 [1, 2, 4, ...] 有x种方案,[2, 1, 4, ... ]肯定也有x种方案。那这样我们就可以进行缓存来做记忆化搜索了,一旦识别到[2,1,4],就可以直接返回缓存的方案了。
缓存什么呢?首先我们要分析[1, 2, 4] 和[2, 1, 4] 共同的特征
特殊排列数组的长度相等,也就是递归的深度需要相同
特殊排列数数组的里面的数 是要相同的,但除了最后一个数以外的顺序可以不一致。
最后一个数必然要相同。因为判断下一个数是否能加入排列种还需要用到这里的最后一个数的。
当然,保存这个特殊排列然后做每次比较也可以,但是每次比较的时间复杂度至少是O(N),而且代码也不好写。
那就是说,我们要把上面总结的特征给抽象出来,如果判断[1, 2, 4] 和[2, 1, 4] 两个数组中的数是相同的呢?我想到了求和、乘积等,但很明显是不行的,都不能唯一表示一个排列。很难想到,但确实是正确且高效的一种方法就是 用二进制的位来存储每个数。
比如[1, 2, 4]的二进制位是0111,[2, 1, 4] 的二进制位也是0111。相当于每个数都是作为下标而存在的,存在这个数,那这个下标对应的值就是1,否则就是0。
但实际上这种想法实操是有问题的,nums的最大值10^9,而int最大32位。所以我们肯定不能在二进制位存储nums[i],那有什么东西可以替代nums[i]来表示吗?不要忘了我们的数组下标是一一映射数组值的。[1,2,4] 可以用下标[0,1,3]表示,[2, 1, 4]可以用下标[1,0,3]表示。
下一个问题来了,如何用代码表示这种替代呢?
对于标记第i位的数为1,我们可以用 1<< i来标记,1<< i就表示将1向左移动i位,就相当于是标记第i位为1了;然后我们可以用或运算 来标记所有的下标,int u = 0, u | (1 << i) 来表示。
代码:
class Solution {
public:
int dfs(vector<int>& nums, int depth, int prevPos,
vector<bool>& visited, int u, unordered_map<string, int> memo) {
if (depth == nums.size()) {
return 1;
}
string key = to_string(prevPos) + "#" + to_string(u);
if (memo.find(key) != memo.end()) {
return memo[key];
}
int res = 0;
for (int i = 0; i < nums.size(); i++) {
if (!visited[i]) {
if (prevPos == -1 || nums[prevPos] % nums[i] == 0 || nums[i] % nums[prevPos] == 0) {
visited[i] = true;
res = (res + dfs(nums, depth + 1, i, visited, u | (1 << i), memo)) % (1000000007);
visited[i] = false;
}
}
}
memo[key] = res;
return res;
}
int specialPerm(vector<int>& nums) {
int n = nums.size();
unordered_map<string, int> memo;
vector<bool> visited(n, false);
return dfs(nums, 0, -1, visited, 0, memo);
}
};