Word Embeddings 词嵌入
参考资料:Word Embeddings
图解Word2vec,读这一篇就够了:全程用例子讲解Word2Vec的动机和训练过程思路,没有复杂的数学公式
词嵌入的提出来源于 我们需要有一种能够让机器学习模型轻易理解的 文本表示方法。对于人来说,“I saw a cat”很容易理解,但是机器学习模型却做不到。
机器学习模型本质是计算机的产物,能理解的形式就是数字,换种说法就是特征向量。那么如何将 人类文本 表示为 合理且有效的 特征向量 就是NLP任务的第一步。
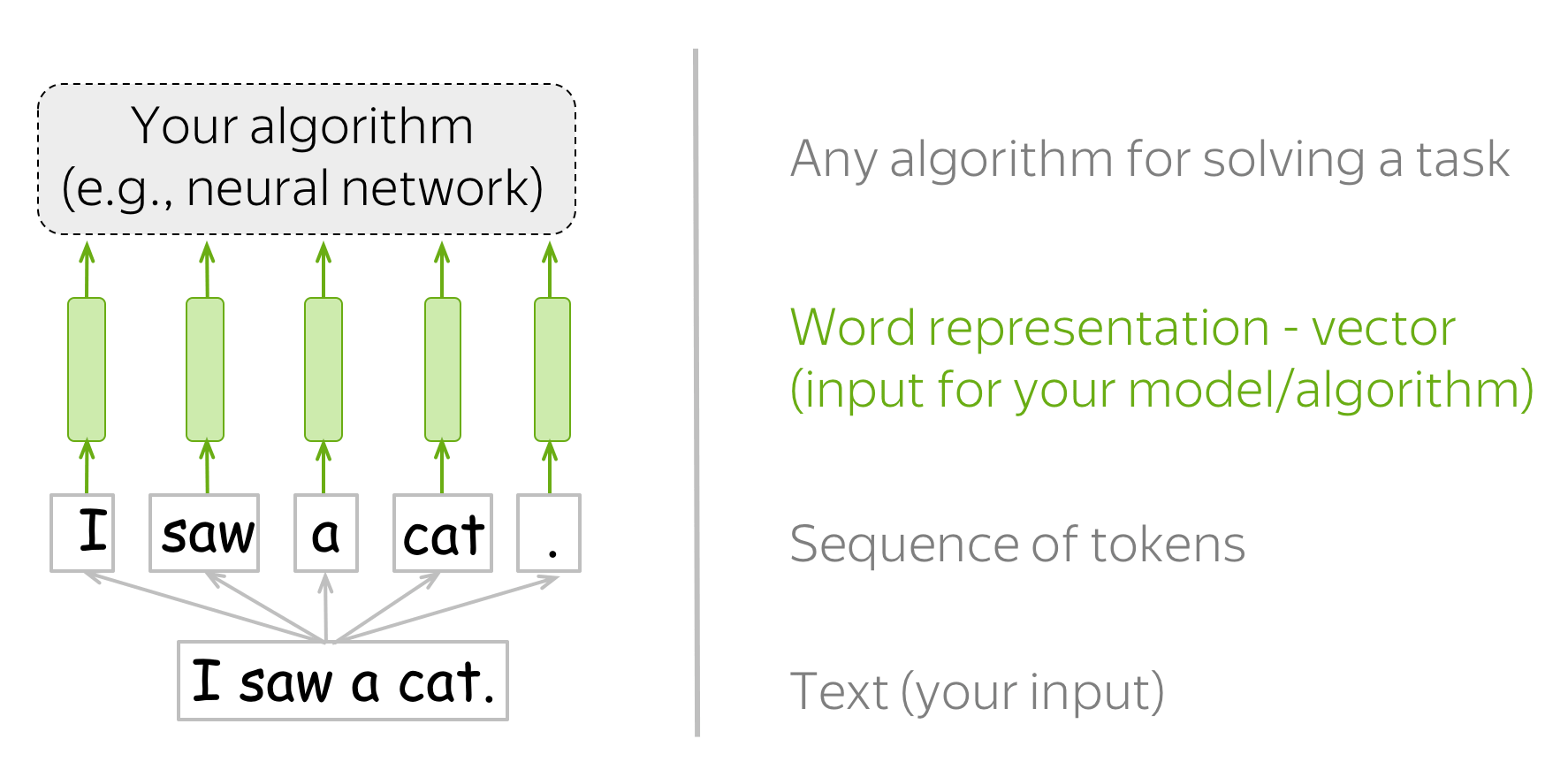
词嵌入的几种方法
我们需要事先定义一个词汇表,然后对于每个人类文本中的单词, 在词汇表中找到它对应的索引,以获取这个索引对应的特征向量。
如果词汇表中没有查找到这个单词,那么就分配词汇表中一个特殊的标记 UNK。 或者直接忽略或者分配零向量作为特征向量。
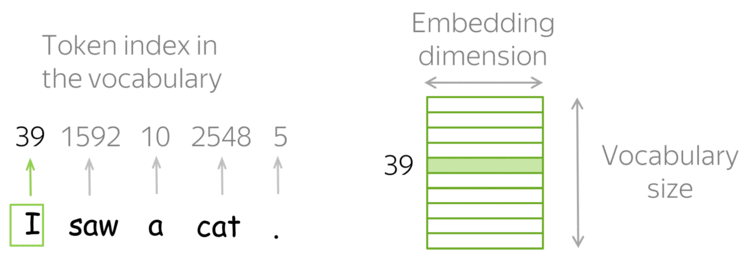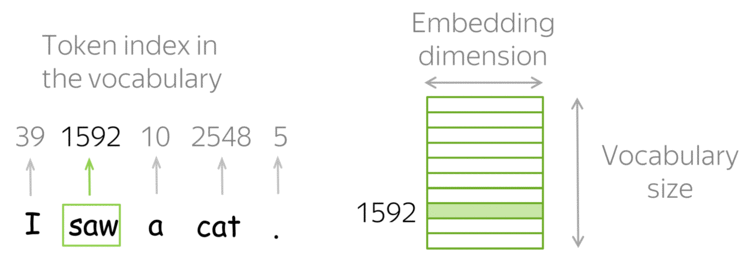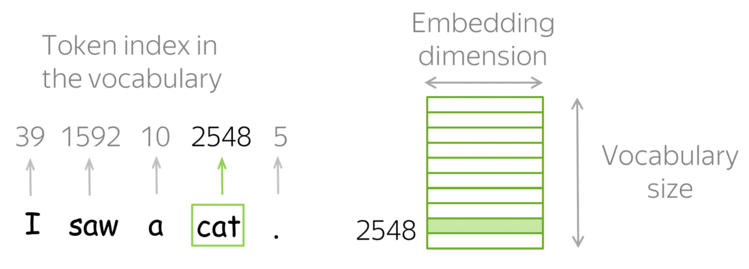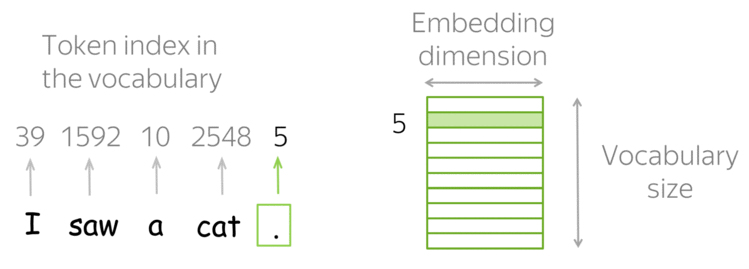
那么问题就是如何构造这个词汇表
one-hot向量
最简单的方法是将词表示为 one-hot 向量:对于词汇表中的第 i 个词,该向量在第 i 个维度上为 1,其余维度为 0。在机器学习中,这是表示分类特征的最简单方法。
one-hot 向量不是表示词的最佳方法。其中一个问题是,对于大型词汇表,这些向量会非常长:向量的维度等于词汇表的大小。这在实践中是不理想的,但这个问题不是最关键的。
真正重要的是,这些向量对它们所代表的词语一无所知。例如,one-hot 向量会认为”猫”和”狗”的距离与”猫”和”桌子”的距离一样!我们可以说 one-hot 向量无法捕捉语义。
那就有一个问题:什么是人类认知的语义
Distributional Semantics
为了在向量中捕捉词语的语义,我们首先需要定义一个可以在实践中使用的语义概念。为此,让我们尝试理解人类是如何知道哪些词语具有相似语义的。
人类在理解一个陌生词汇A时,会看A用在什么上下文(语境)中,如果有一个别的词B也可以用在这些语境下,那么我们就认为A和B是语义相似的。这也就是分布假说:Words which frequently appear in similar contexts have similar meaning.
这是一个非常有价值的思想:它可以在实践中用于使词向量捕捉其含义。根据分布假说,“捕捉含义”和“捕捉上下文”本质上是一回事。因此,我们唯一需要做的就是将关于词上下文的信息放入词表示中。有几种方法可以实现这一点。
Count-Based Methods
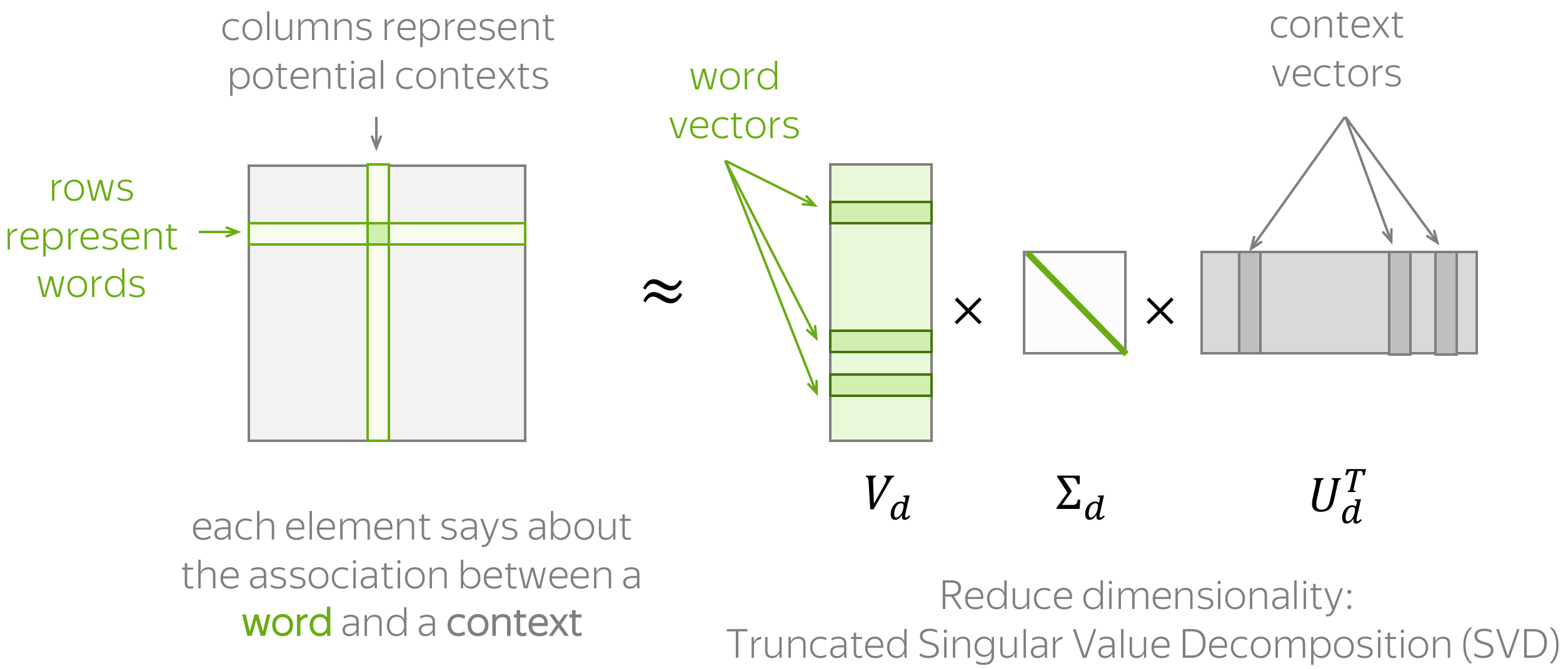
基于计数的方法:根据全局语料库统计手动添加上下文信息。
上述图示了通用流程,包括两个步骤:(1) 构建词-上下文矩阵,(2) 降低其维度。降低维度的原因有两个。首先,原始矩阵非常大。其次,由于很多词只在少数可能的上下文中出现,这个矩阵可能包含大量无信息元素(例如,零)。
为了估计词语/上下文之间的相似度,通常需要评估归一化词语/上下文向量的点积(即余弦相似度)。
为了定义一种基于计数的算法,我们需要定义两件事:
- 上下文是什么(包括一个词出现在上下文中的含义),
- 词和上下文如何关联,即计算矩阵元素的公式。
Co-Occurence Counts
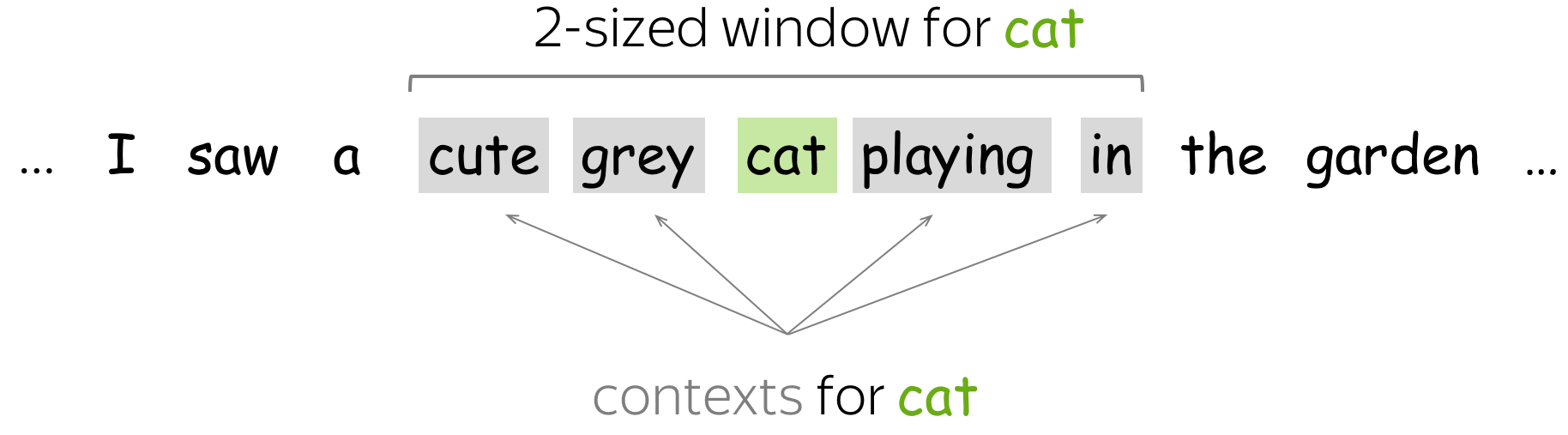
最简单的方法是将上下文定义为 L 大小的窗口中的每个词。词-上下文对(w, c)的矩阵元素是 w 在上下文 c 中出现的次数。这是获得嵌入的最基本(而且非常非常古老)的方法。

Positive Pointwise Mutual Information (PPMI)
这里的上下文定义与之前相同,但衡量词语与上下文之间关联的度量更加巧妙:正 PMI(或简称为 PPMI)。PPMI 度量被广泛认为是预神经网络分布相似性模型的最新技术。

Latent Semantic Analysis (LSA): Understanding Documents
潜在语义分析(LSA)分析一组文档。在之前的那些方法中,上下文仅用于获取词向量,之后就被丢弃了,而在这里,我们同样对上下文感兴趣,或者说,在这个情况下是文档向量。LSA 是最简单的主题模型之一:文档向量之间的余弦相似度可以用来衡量文档之间的相似度。
术语”LSA”有时指的是一种更通用的方法,即对词-文矩阵应用 SVD,其中词-文元素可以以不同的方式计算(例如,简单的共现、tf-idf 或其他加权方式)。
Word2Vec: a Prediction-Based Method
核心思想:Learn word vectors by teaching them to predict contexts.
Word2Vec 是一个参数为词向量的模型。这些参数通过迭代优化以实现某个目标。该目标迫使词向量“了解”一个词可能出现的上下文:向量被训练以预测相应词的可能上下文。正如你从分布式假说中记住的,如果向量“了解”上下文,它们就“了解”词义。
Word2Vec 是一种迭代方法。它的主要思想如下:
- 获取一个巨大的文本语料库;
- 用滑动窗口逐个词地遍历文本。每一步都有一个中心词和上下文词(这个窗口中的其他词);
- 对于中心词,计算上下文词的概率;
- 调整向量以增加这些概率。

Objective Function: Negative Log-Likelihood
对于文本语料库中的每个位置 t=1,…,T ,Word2Vec 根据中心词 wt 预测 m 大小的窗口内的上下文词: \(\color{#88bd33}{\mbox{Likelihood}} \color{black}= L(\theta)= \prod\limits_{t=1}^T\prod\limits_{-m\le j \le m, j\neq 0}P(\color{#888}{w_{t+j}}|\color{#88bd33}{w_t}\color{black}, \theta),\) 其中 θ 是所有需要优化的变量。目标函数(也称为损失函数或成本函数) J(θ) 是平均负对数似然:
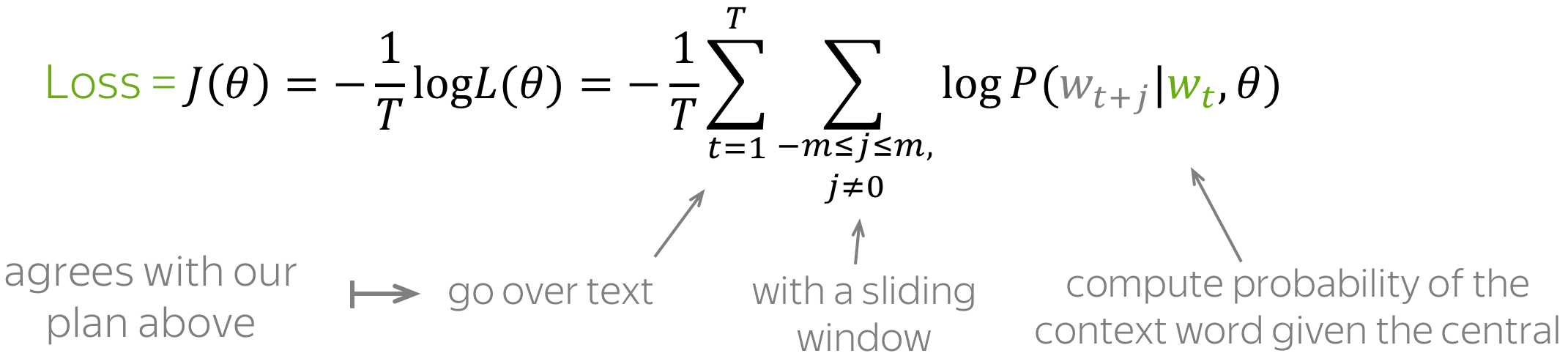
注意损失如何与我们的计划相符:用滑动窗口遍历文本并计算概率。现在让我们来找出如何计算这些概率。
How to calculate P(wt+j | wt,θ)?
对于每个词 w ,我们将有两个向量:
- Vw 当它是中心词时
- Uw当它是上下文词时
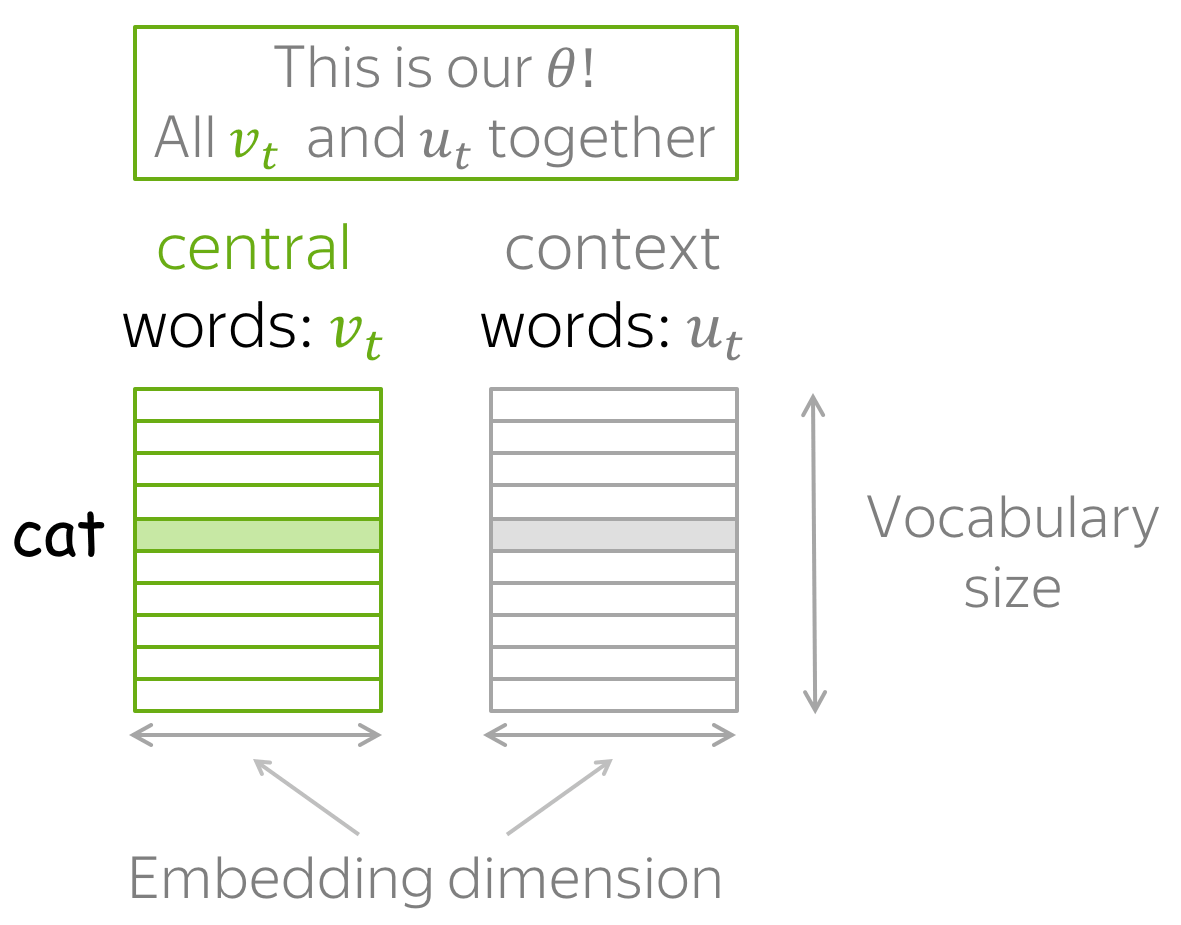
向量训练完成后,我们通常丢弃上下文向量,仅使用词向量。
然后对于中心词 c (c - 中心词)和上下文词 o (o - 上下文词),上下文词的概率是
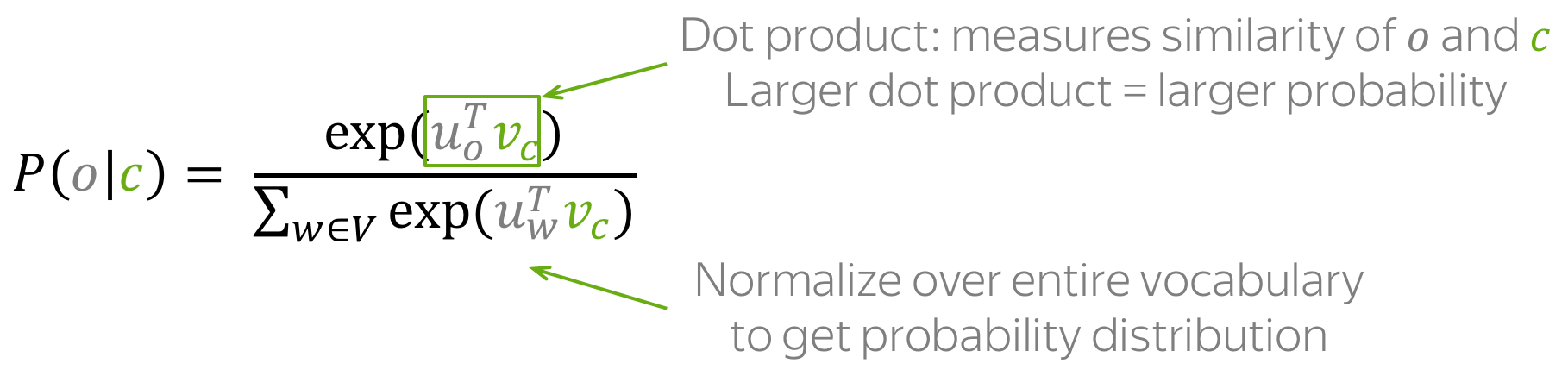
注意:这是 softmax 函数!
How to train: by Gradient Descent, One Word at a Time
让我们回想一下,我们的参数 θ 是词汇表中所有单词的向量 Vw 和 Uw 。这些向量通过梯度下降(使用某个学习率 α )优化训练目标来学习: \(\theta^{new} = \theta^{old} - \alpha \nabla_{\theta} J(\theta).\) 我们逐个进行这些更新:每次更新是针对一个中心词和它的一个上下文词的对。再看看损失函数: \(\color{#88bd33}{\mbox{Loss}}\color{black} =J(\theta)= -\frac{1}{T}\log L(\theta)= -\frac{1}{T}\sum\limits_{t=1}^T \sum\limits_{-m\le j \le m, j\neq 0}\log P(\color{#888}{w_{t+j}}\color{black}|\color{#88bd33}{w_t}\color{black}, \theta)= \frac{1}{T} \sum\limits_{t=1}^T \sum\limits_{-m\le j \le m, j\neq 0} J_{t,j}(\theta).\) 对于中心词 wt ,损失包含针对它的每个上下文词 wt+j 的一个独特项 Jt,j(θ) = −logP(wt+j|wt,θ) 。让我们更详细地看看这一项,并尝试理解如何为这一步进行更新。例如,让我们假设我们有一个句子

以中心词 cat 和四个上下文词为例。由于我们只关注一个步骤,我们将只选择其中一个上下文词;例如,我们选择 cute。那么中心词 cat 和上下文词 cute 的损失项为: \(J_{t,j}(\theta)= -\log P(\color{#888}{cute}\color{black}|\color{#88bd33}{cat}\color{black}) = -\log \frac{\exp\color{#888}{u_{cute}^T}\color{#88bd33}{v_{cat}}}{ \sum\limits_{w\in Voc}\exp{\color{#888}{u_w^T}\color{#88bd33}{v_{cat}} }} = -\color{#888}{u_{cute}^T}\color{#88bd33}{v_{cat}}\color{black} + \log \sum\limits_{w\in Voc}\exp{\color{#888}{u_w^T}\color{#88bd33}{v_{cat}}}\color{black}{.}\) 注意这一步中哪些参数是存在的:
- 从中心词的向量中,只有 Vcat ;
- 从上下文词的向量中,所有 Uw (对于词汇表中的所有词)。
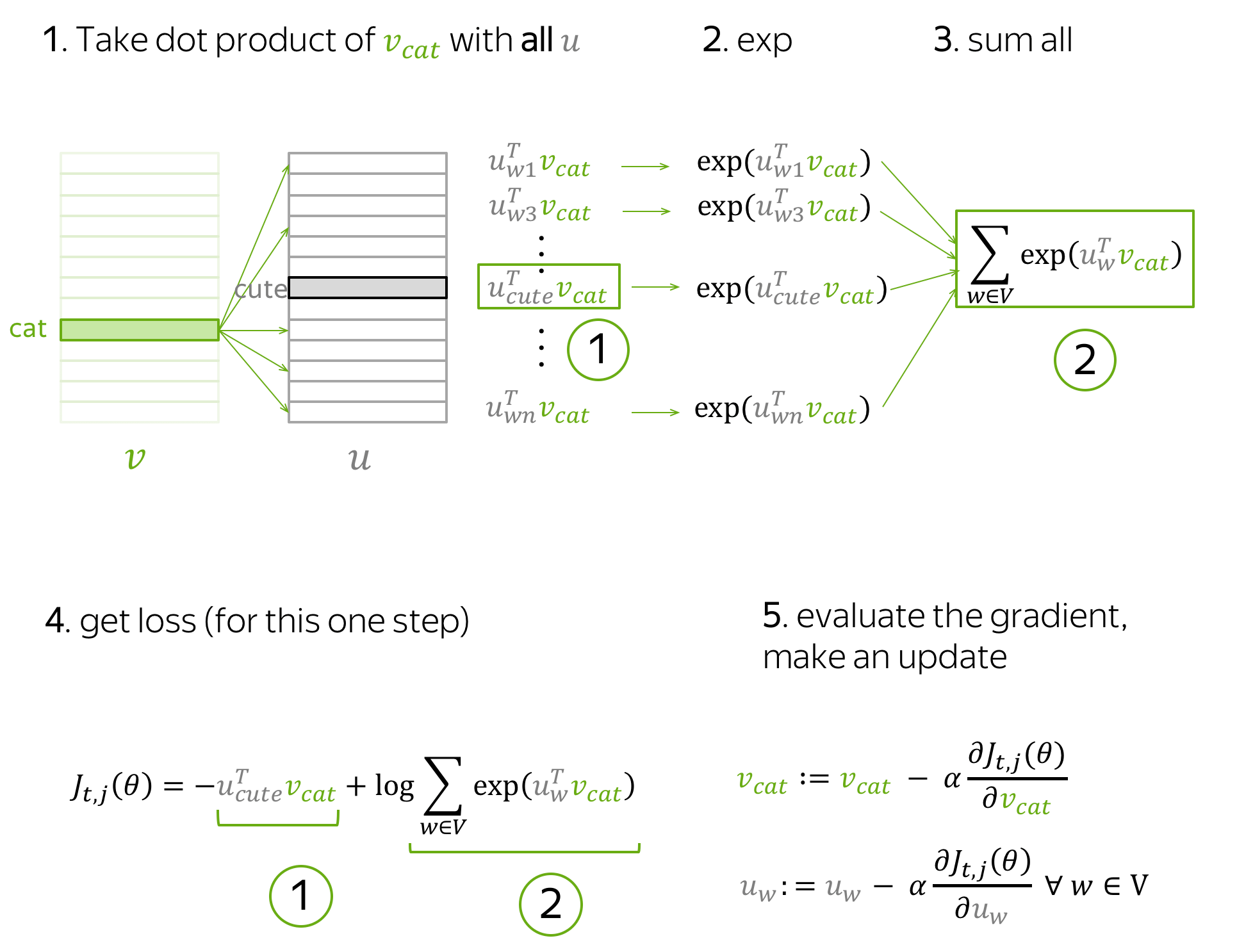
通过更新以最小化 Jt,j(θ) ,我们迫使参数增加 vcat 和 ucute 的相似度(点积),同时,对于词汇表中的其他词 w ,减少 vcat 和 uw 之间的相似度。
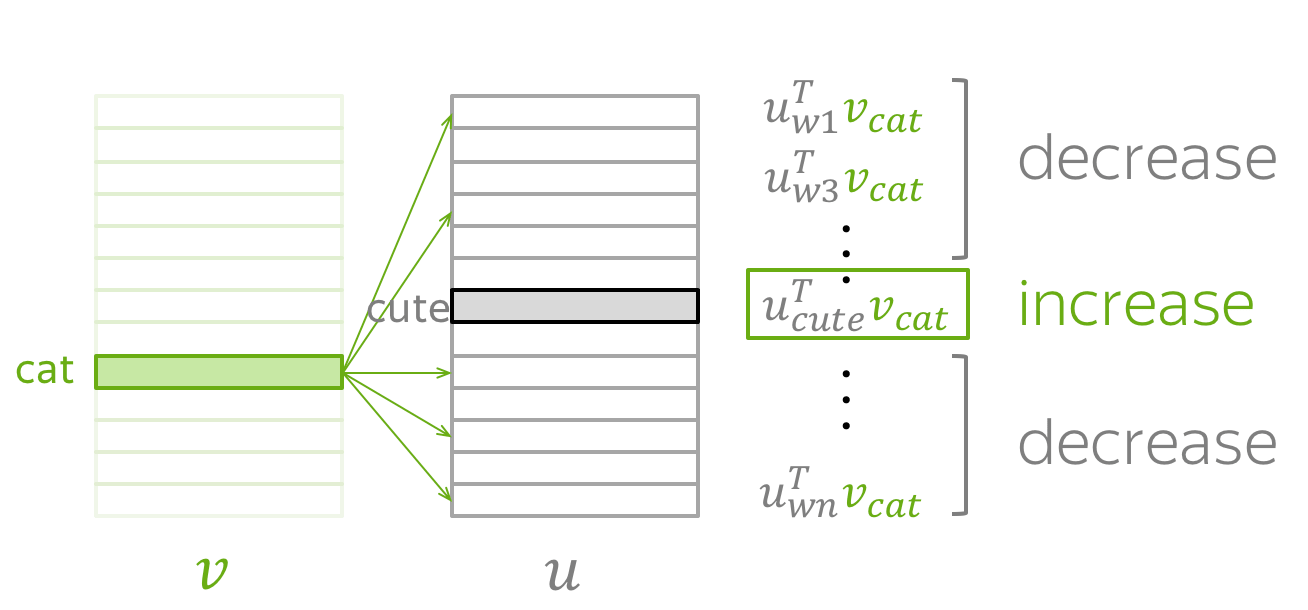
这可能听起来有点奇怪:为什么我们想要降低 vcat 与其他所有词的相似度,如果其中一些词也是有效的上下文词(例如,在我们的例句中,grey、playing、in)?
但不用担心:因为我们为每个上下文词(以及文本中的所有中心词)进行更新,在所有更新的平均值上,我们的向量将学习可能上下文的分布。
Faster Training: Negative Sampling
在上面的例子中,对于每个中心词和其上下文词的配对,我们必须更新所有上下文词的向量。这是非常低效的:每一步中,进行更新所需的时间与词汇量成正比。
但我们为什么在每一步都要考虑词汇中的所有上下文向量呢?例如,想象在当前步骤中,我们不仅考虑当前目标(cute)的上下文向量,还只考虑几个随机选择的词的上下文向量。图示展示了这种直觉。
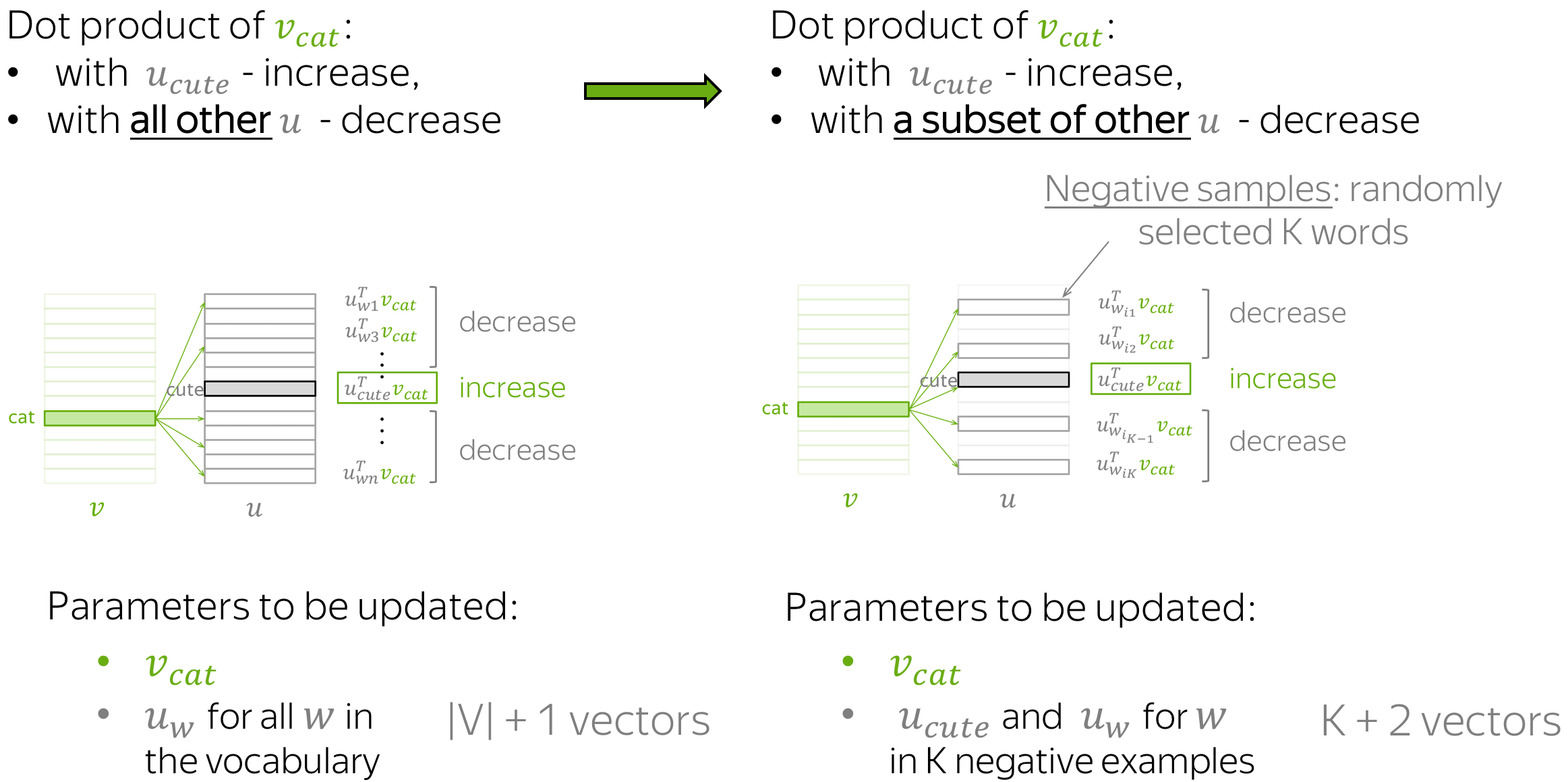
和之前一样,我们正在增加 vcat 和 ucute 之间的相似度。不同的是,现在我们减少 vcat 和上下文向量之间的相似度,不是对所有单词,而是仅对 K 个“负”示例子集。
由于我们有一个大型语料库,在所有更新的平均情况下,我们将每个向量更新足够多的次数,并且向量仍然能够很好地学习词语之间的关系。
形式上,这一步的新损失函数为: \(J_{t,j}(\theta)= -\log\sigma(\color{#888}{u_{cute}^T}\color{#88bd33}{v_{cat}}\color{black}) - \sum\limits_{w\in \{w_{i_1},\dots, w_{i_K}\}}\log\sigma({-\color{#888}{u_w^T}\color{#88bd33}{v_{cat}}}\color{black}),\) ,其中 wi1,…,wiK 是在这一步选择的 K 个负样本, σ(x)是 sigmoid 函数。
The Choice of Negative Examples
每个词只有少数几个”真实”的上下文。因此,随机选择的词很可能为”负”样本,即不是真实的上下文。这个简单想法不仅用于高效训练 Word2Vec,也应用于许多其他场景.
Word2Vec 根据词的经验分布随机采样负样本。设 U(w) 为词的单语料分布,即 U(w) 是词 w 在文本语料库中的频率。Word2Vec 修改这个分布,更频繁地采样低频词:它按 U3/4(w) 的比例进行采样。
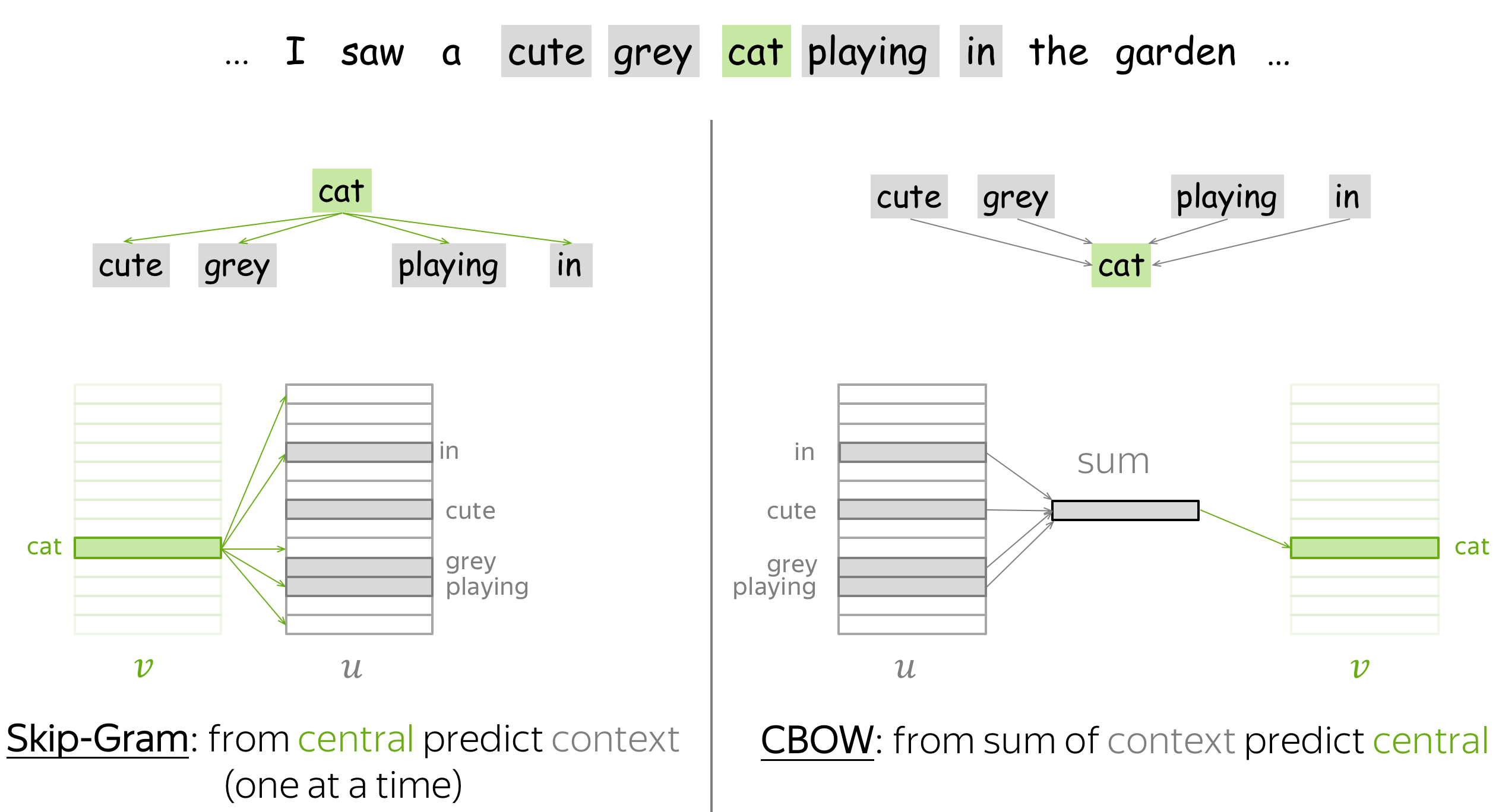
Word2Vec variants: Skip-Gram and CBOW
存在两种 Word2Vec 变体:Skip-Gram 和 CBOW。
Skip-Gram 是我们之前考虑的模型:它根据中心词预测上下文词。带负采样的 Skip-Gram 是最流行的方法。
CBOW(连续词袋模型)通过上下文向量的总和来预测中心词。这种简单的词向量总和被称为“词袋”,这也是该模型名称的由来。
原始 Word2Vec 论文是:
- Efficient Estimation of Word Representations in Vector Space
- Distributed Representations of Words and Phrases and their Compositionality
GloVe: Global Vectors for Word Representation
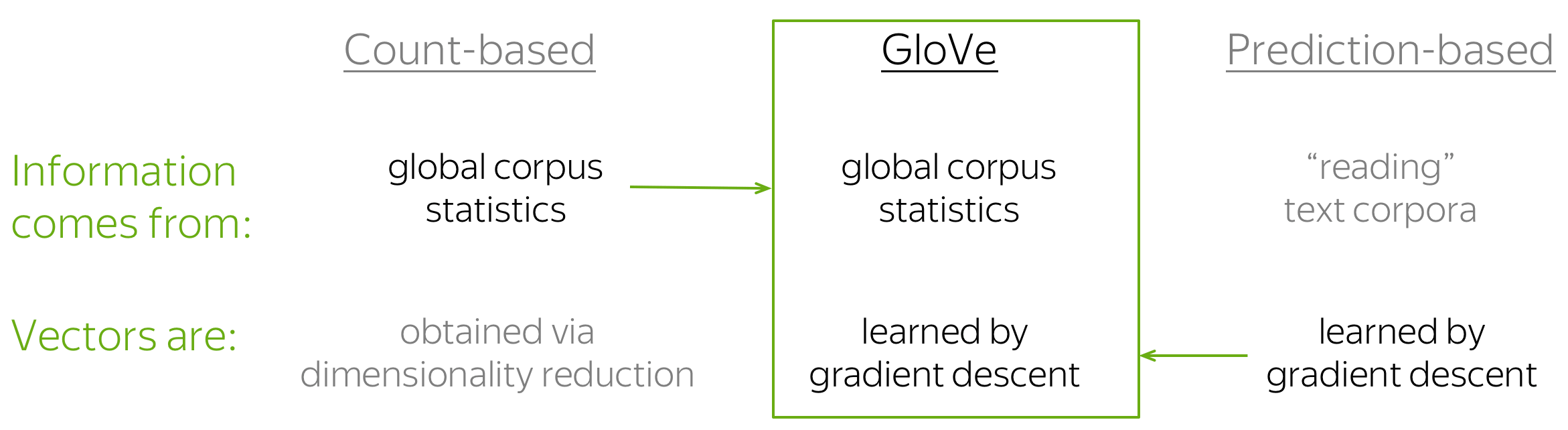
GloVe 模型是计数方法与预测方法(例如 Word2Vec)的结合。模型名称 GloVe 代表”Global Vectors”,这反映了它的理念:该方法利用语料库的全局信息来学习向量。
如前所述,最简单的基于计数的方方法使用共现计数来衡量词 w 与上下文 c 之间的关联:N(w, c)。GloVe 也使用这些计数来构建损失函数:
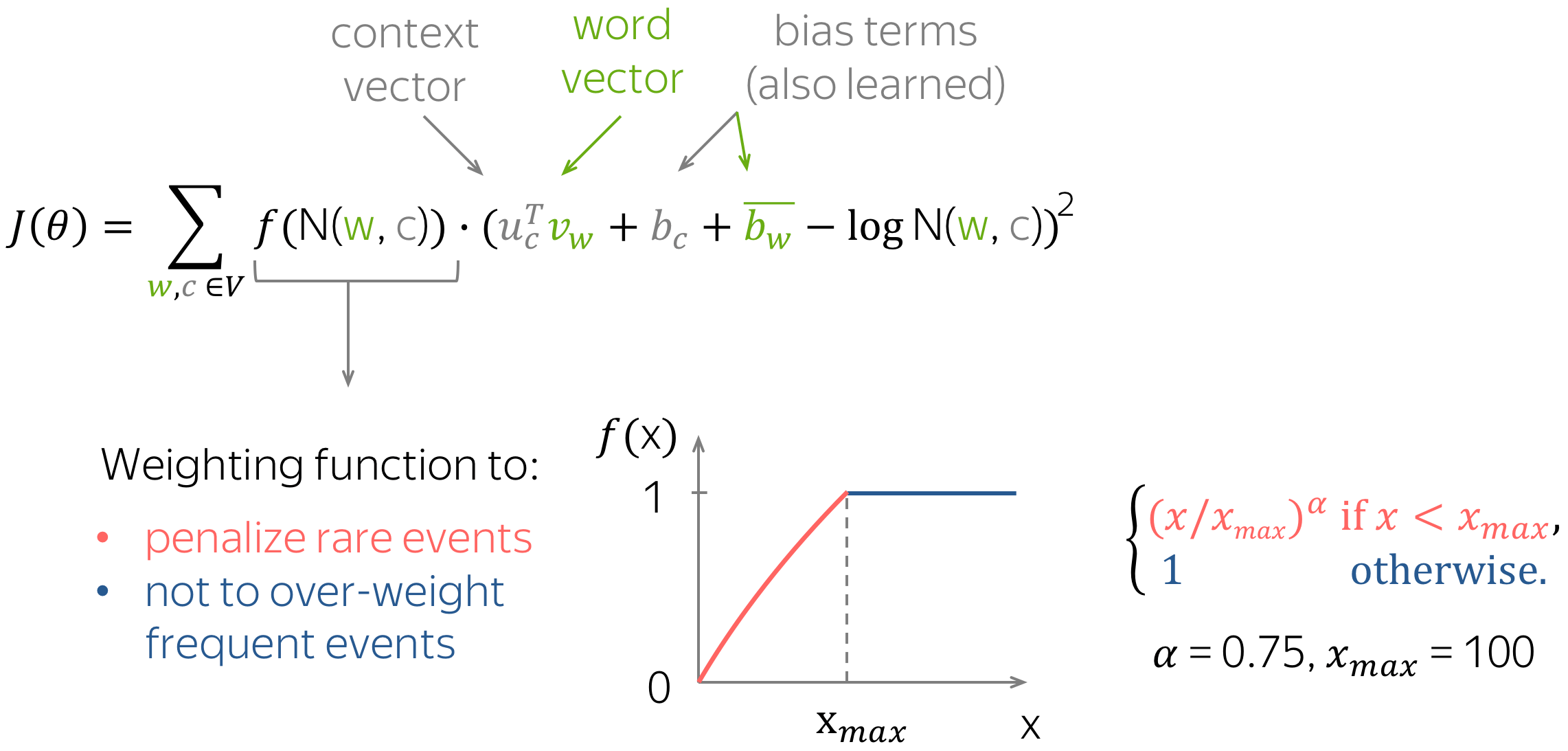
与 Word2Vec 类似,我们也有中心词和上下文词的不同向量——这些是我们的参数。此外,该方法为每个词向量有一个标量偏差项。
特别有趣的是 GloVe 控制稀有词和常见词影响的方式:对每对(w, c)的损失进行加权,使得
- 稀有事件受到惩罚
- 非常常见的事件不会被过度加权
Evaluation of Word Embeddings
我们如何判断一种获取词嵌入的方法比另一种方法更好?评估方法分为两种(不仅限于词嵌入):内在评估和外在评估。
Intrinsic Evaluation: Based on Internal Properties
这种评估方法关注嵌入的内部属性,即它们捕捉语义的能力。具体来说,在分析和可解释性部分,我们将详细讨论如何通过词相似性和词类比任务来评估嵌入。

Extrinsic Evaluation: On a Real Task
这种评估方式可以告诉你哪些词嵌入对于你真正关心的任务(例如文本分类、共指消解等)效果更好。在这种设置下,你需要为真实任务多次训练模型/算法:每个你想评估的词嵌入都需要一个模型。然后,通过观察这些模型的质量来决定哪些词嵌入更好。
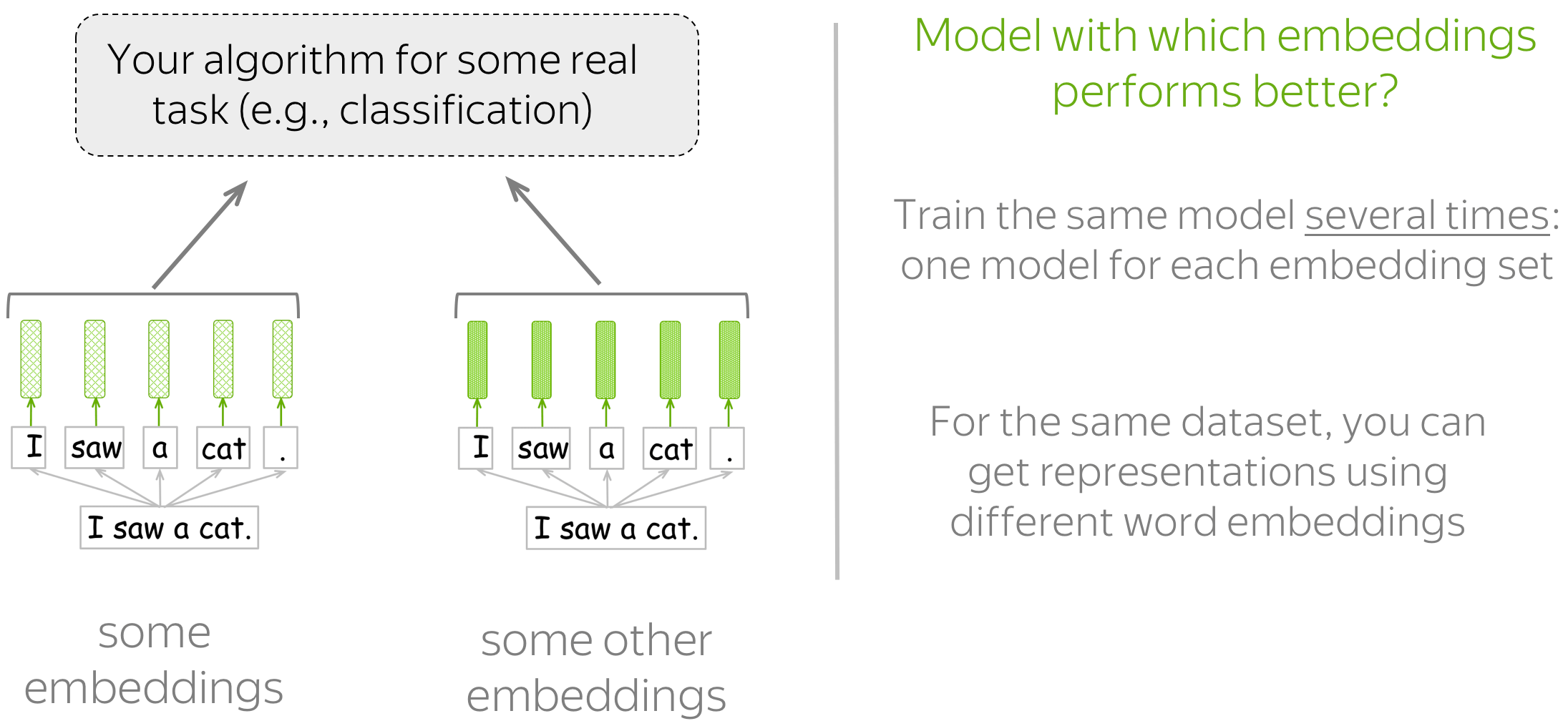
How to Choose?
