计算机研究生技术栈
基础技术栈
- 硬实力:编程语言(Python + C++ + Java) —> 机器学习 —> 神经网络 —> 大模型 —> 项目实现
- 软实力:文献检索 —> 文献阅读 —> 学术报告 —> 论文写作
编程语言能力提升
Python:流畅的Python(如何编写更加优质的Python代码)
机器学习能力提升
- 统计学习方法(李航) 一般三遍才能吃透
- Kaggle:真实的、完整的机器学习处理真实项目的过程
深度学习能力提升
- 神经网络与深度学习(邱锡鹏)
- 动手学深度学习(李沐)
- Kaggle竞赛
- 一般的神经网络训练全过程一般遵循下面的思路
| 行动 | 结果 | 数据类型 |
|---|---|---|
| 数据收集 | 数据集 | 八爪鱼采集器 |
| 数据读取 | 原始数据 | Jason / pandas / numpy |
| 数据处理 | 标准数据 | Numpy / sklearn |
| 数据封装 | 数值类型数据 | Torch.utils.data Dataset / DataLoader |
| 模型构建 | 模型 | Transformers AutoModel / AutoTokenizer |
| 训练流程 | 不断优化的权重 | Torch.nn /tqdm / optimizer |
| 权重存储 | 权重文件 | Torch.save / torch.load |
| 测试流程 | Precision Recall Accuracy | Sklearn numpy |
文献检索能力提升
在哪找论文
- 谷歌学术 (谷粉学术,谷歌学术的镜像,不用梯子)
- SCI - HUB
- 百度学术
发表在顶会 / 发表学校是知名学府的 论文就是好论文
如何快速了解一个课题的基本信息
- 知网、维普根据主题,关键字等搜索名校硕博论文(年份尽量新)
- 仔细阅读硕博论文中的国内外研究现状or相关工作部分
- 从硕博论文汇总寻找锚点文献(年份不重要,质量必须高)
- 前向或者后向搜索关联文献,扩充文献数量(保证扩充质量)
- 筛选高质量文献10篇左右作为核心文献
- 仔细阅读10篇文献全文(实验分析、讨论等)
- 基于硕博论文和10篇核心文献,初步撰写文献综述
- 基于扩展的文献扩展文献综述
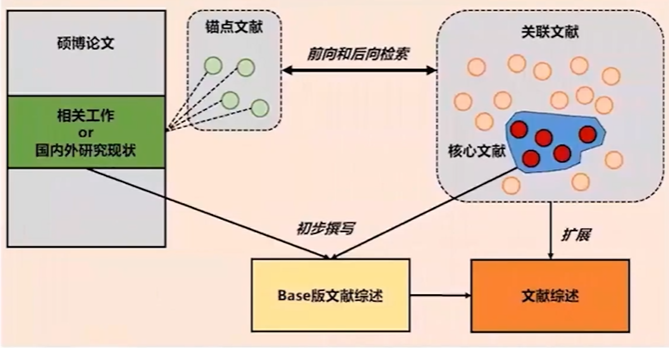
锚点文献:硕博论文中提到的关键参考文献
前向搜索 / 后向搜索:这篇论文引用了哪些文献,哪些文献引用了这篇论文
审稿人的审稿流程
- 读标题
- 读摘要
- 看Figure 1(非常重要)
- 看引言(Introduction)
这四步走完审稿人看懂你在干什么才能有希望中paper
如何寻找实验方法(idea)
嫁接法:相同任务类别的顶会/顶刊方法,应用到自己的任务上,根据任务特点稍作调整。注意任务级别,不要将低级任务方法应用到高级任务。尽量平级或者降级
先验法:将任务上的先验,例如知识库,知识图谱,启发式规则等注入到方法中。该方法几乎可以保证实验一次成功,失败概率很小
组合法:比较常见的方法,将类似任务上的几种有效方法作为模块集成到自己的方法中,形成一个组合性的方法。注意组合不要过多,每个模块不要过于复杂,控制好整体复杂度
实验分析
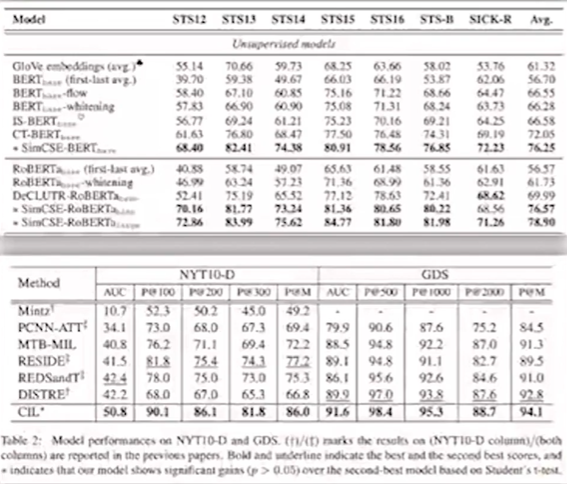
普通对比实验:目的是证明同等实验条件下,我们的方法在N个数据集上都比现有方法效果好。一般用表格呈现,加粗的是最好的结果,我们自己的方法一般在最后一个或者最后两个
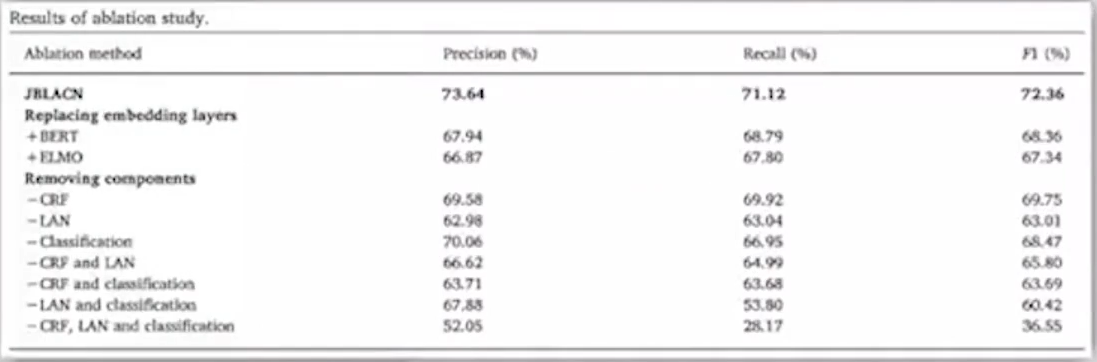
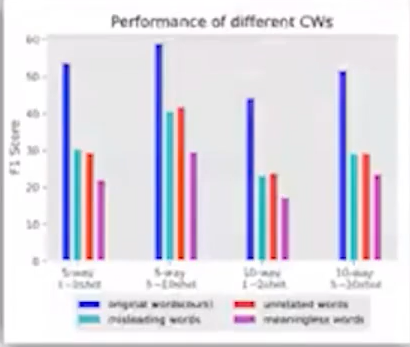
消融实验:目的是证明我们的方法中每个组件都是有效的,避免方法中包含负优化组件。一般用表格或者柱状图呈现(下图中的例子:最顶层是我们的方法,替换任何一个组件或者删除任何一个组件,最终效果都下降了,说明每个组件都有用)
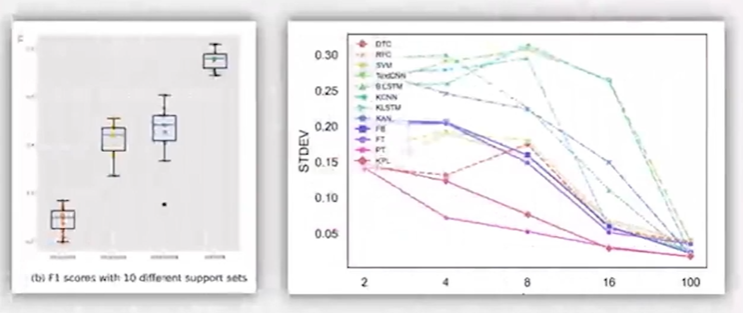
鲁棒性分析:目的是证明不同的实验条件下,我们的方法没有显著的性能波动,可以表现为测试指标的方差或者标准差较小。一般用箱型图或者折线图呈现(箱型图:统计结果的最大值,最小值,上1/4,下1/4的差距,箱子越长说明越不稳定)
超参数分析:目的是证明需要人为设置的超参数对模型性能的影响,并验证当前所设置的超参数是最优的,一般用柱状图或者折线图表现

可视化分析:目的是直观展示模型性能并在一定程度上验证模型的可解释性

可解释性分析:目的是验证模型的可解释性,通常是选取一个或者几个案例进行验证
原视频链接
【研0、研一必看!计算机研究生如何从头规划好学习路线!导师都不讲的文献检索方法与SCI论文写作技巧分享,轻松解决大小论文!】 https://www.bilibili.com/video/BV1QZ421x7Q3/?share_source=copy_web&vd_source=fa43e9d6cd4073e1172b87c3220f143c