动态规划基本技巧
动态规划设计:最长递增子序列
动态规划的套路:找到了问题的「状态」,明确了 dp 数组/函数的含义,定义了 base case;但是不知道如何确定「选择」,也就是找不到状态转移的关系,依然写不出动态规划解法,怎么办?
不要担心,动态规划的难点本来就在于寻找正确的状态转移方程,本文就借助经典的「最长递增子序列问题」来讲一讲设计动态规划的通用技巧:数学归纳思想。
最长递增子序列(Longest Increasing Subsequence,简写 LIS)是非常经典的一个算法问题,比较容易想到的是动态规划解法,时间复杂度 O(N^2),我们借这个问题来由浅入深讲解如何找状态转移方程,如何写出动态规划解法。比较难想到的是利用二分查找,时间复杂度是 O(NlogN),我们通过一种简单的纸牌游戏来辅助理解这种巧妙的解法。
题目
输入一个无序的整数数组,请你找到其中最长的严格递增子序列的长度,函数签名如下:
int lengthOfLIS(int[] nums);
比如说输入 nums=[10,9,2,5,3,7,101,18],其中最长的递增子序列是 [2,3,7,101],所以算法的输出应该是 4。
注意「子序列」和「子串」这两个名词的区别,子串一定是连续的,而子序列不一定是连续的。下面先来设计动态规划算法解决这个问题。
动态规划解法
动态规划的核心设计思想是数学归纳法。
相信大家对数学归纳法都不陌生,高中就学过,而且思路很简单。比如我们想证明一个数学结论,那么我们先假设这个结论在 k < n 时成立,然后根据这个假设,想办法推导证明出 k = n 的时候此结论也成立。如果能够证明出来,那么就说明这个结论对于 k 等于任何数都成立。
类似的,我们设计动态规划算法,不是需要一个 dp 数组吗?我们可以假设 dp[0...i-1] 都已经被算出来了,然后问自己:怎么通过这些结果算出 dp[i]?
直接拿最长递增子序列这个问题举例你就明白了。不过,首先要定义清楚 dp 数组的含义,即 dp[i] 的值到底代表着什么?
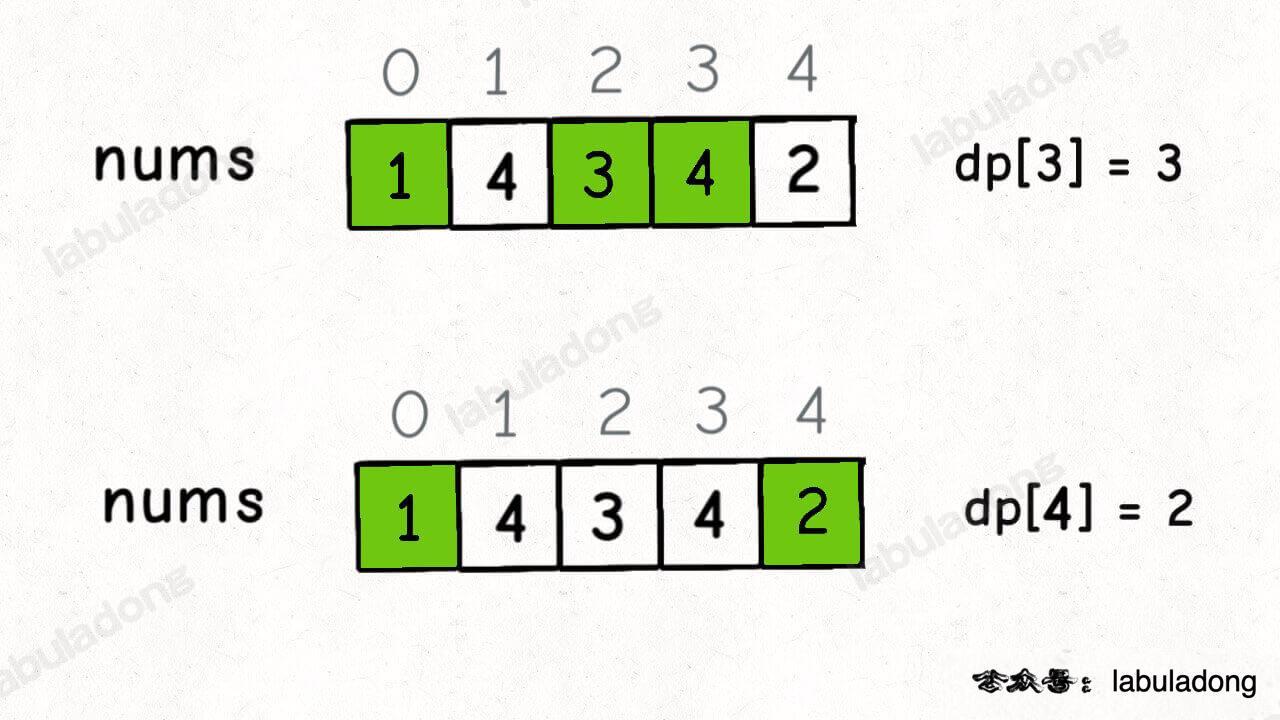
我们的定义是这样的:dp[i] 表示以 nums[i] 这个数结尾的最长递增子序列的长度。
根据这个定义,我们就可以推出 base case:dp[i] 初始值为 1,因为以 nums[i] 结尾的最长递增子序列起码要包含它自己。
举两个例子:
这个 GIF 展示了算法演进的过程:

根据这个定义,我们的最终结果(子序列的最大长度)应该是 dp 数组中的最大值。
int res = 0;
for (int i = 0; i < dp.length; i++) {
res = Math.max(res, dp[i]);
}
return res;
读者也许会问,刚才的算法演进过程中每个 dp[i] 的结果是我们肉眼看出来的,我们应该怎么设计算法逻辑来正确计算每个 dp[i] 呢?
这就是动态规划的重头戏,如何设计算法逻辑进行状态转移,才能正确运行呢?这里需要使用数学归纳的思想:
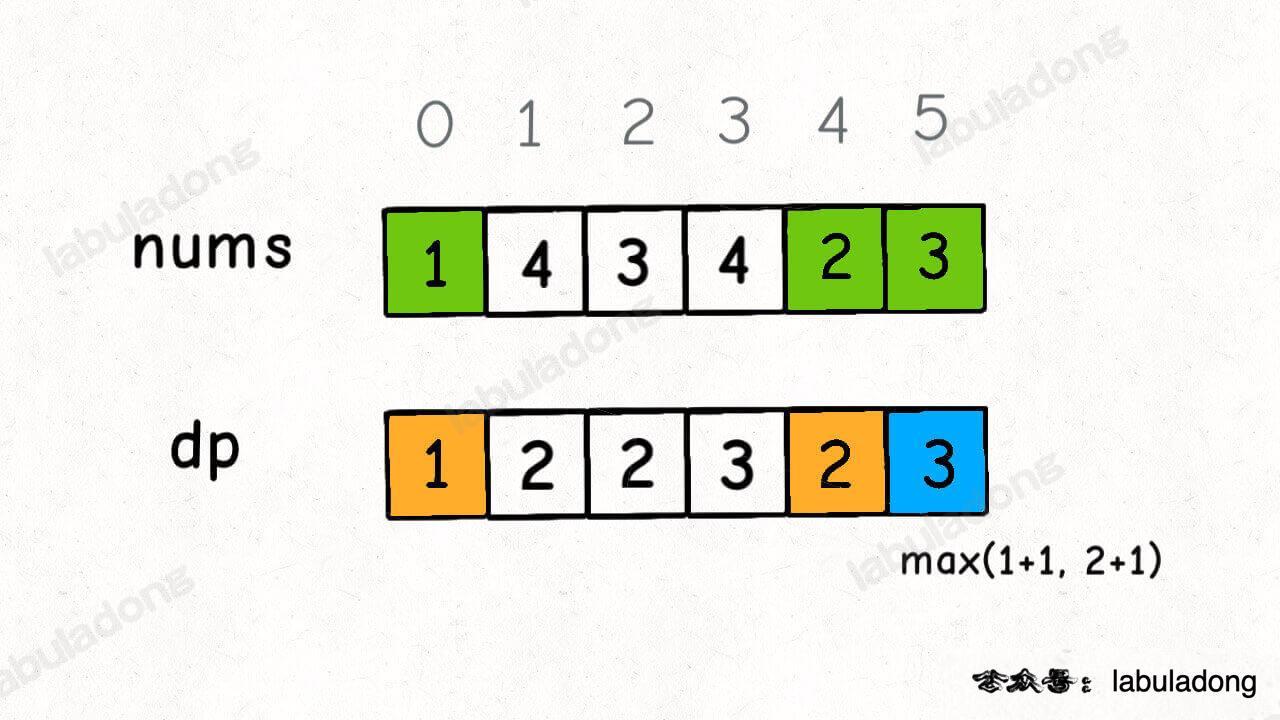
假设我们已经知道了 dp[0..4] 的所有结果,我们如何通过这些已知结果推出 dp[5] 呢?

根据刚才我们对 dp 数组的定义,现在想求 dp[5] 的值,也就是想求以 nums[5] 为结尾的最长递增子序列。
nums[5] = 3,既然是递增子序列,我们只要找到前面那些结尾比 3 小的子序列,然后把 3 接到这些子序列末尾,就可以形成一个新的递增子序列,而且这个新的子序列长度加一。
nums[5] 前面有哪些元素小于 nums[5]?这个好算,用 for 循环比较一波就能把这些元素找出来。
以这些元素为结尾的最长递增子序列的长度是多少?回顾一下我们对 dp 数组的定义,它记录的正是以每个元素为末尾的最长递增子序列的长度。
以我们举的例子来说,nums[0] 和 nums[4] 都是小于 nums[5] 的,然后对比 dp[0] 和 dp[4] 的值,我们让 nums[5] 和更长的递增子序列结合,得出 dp[5] = 3:
for (int j = 0; j < i; j++) {
if (nums[i] > nums[j]) {
dp[i] = Math.max(dp[i], dp[j] + 1);
}
}
当 i = 5 时,这段代码的逻辑就可以算出 dp[5]。其实到这里,这道算法题我们就基本做完了。
for (int i = 0; i < nums.length; i++) {
for (int j = 0; j < i; j++) {
// 寻找 nums[0..j-1] 中比 nums[i] 小的元素
if (nums[i] > nums[j]) {
// 把 nums[i] 接在后面,即可形成长度为 dp[j] + 1,
// 且以 nums[i] 为结尾的递增子序列
dp[i] = Math.max(dp[i], dp[j] + 1);
}
}
}
结合我们刚才说的 base case,下面我们看一下完整代码:
class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
// 定义:dp[i] 表示以 nums[i] 这个数结尾的最长递增子序列的长度
vector<int> dp(nums.size());
// base case:dp 数组全都初始化为 1
fill(dp.begin(), dp.end(), 1);
for (int i = 0; i < nums.size(); i++) {
for (int j = 0; j < i; j++) {
if (nums[i] > nums[j])
dp[i] = max(dp[i], dp[j] + 1);
}
}
int res = 0;
for (int i = 0; i < dp.size(); i++) {
res = max(res, dp[i]);
}
return res;
}
};
至此,这道题就解决了,时间复杂度 O(N^2)。总结一下如何找到动态规划的状态转移关系:
1、明确 dp 数组的定义。这一步对于任何动态规划问题都很重要,如果不得当或者不够清晰,会阻碍之后的步骤。
2、根据 dp 数组的定义,运用数学归纳法的思想,假设 dp[0...i-1] 都已知,想办法求出 dp[i],一旦这一步完成,整个题目基本就解决了。
但如果无法完成这一步,很可能就是 dp 数组的定义不够恰当,需要重新定义 dp 数组的含义;或者可能是 dp 数组存储的信息还不够,不足以推出下一步的答案,需要把 dp 数组扩大成二维数组甚至三维数组。
目前的解法是标准的动态规划,但对最长递增子序列问题来说,这个解法不是最优的,可能无法通过所有测试用例了,下面讲讲更高效的解法。
二分查找解法
正常人基本想不到这种解法(也许玩过某些纸牌游戏的人可以想出来)。所以了解一下就好。
根据题目的意思,我都很难想象这个问题竟然能和二分查找扯上关系。其实最长递增子序列和一种叫做 patience game 的纸牌游戏有关,甚至有一种排序方法就叫做 patience sorting(耐心排序)。
为了简单起见,后文跳过所有数学证明,通过一个简化的例子来理解一下算法思路。
首先,给你一排扑克牌,我们像遍历数组那样从左到右一张一张处理这些扑克牌,最终要把这些牌分成若干堆。
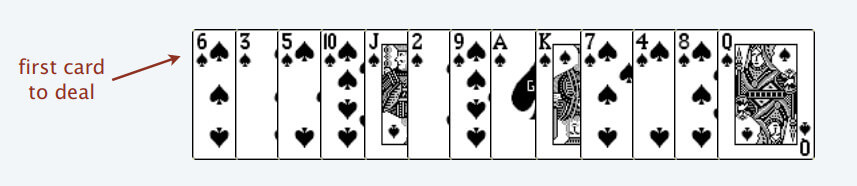
处理这些扑克牌要遵循以下规则:
只能把点数小的牌压到点数比它大的牌上;如果当前牌点数较大没有可以放置的堆,则新建一个堆,把这张牌放进去;如果当前牌有多个堆可供选择,则选择最左边的那一堆放置。
比如说上述的扑克牌最终会被分成这样 5 堆(我们认为纸牌 A 的牌面是最大的,纸牌 2 的牌面是最小的)。

为什么遇到多个可选择堆的时候要放到最左边的堆上呢?因为这样可以保证牌堆顶的牌有序(2, 4, 7, 8, Q),证明略。
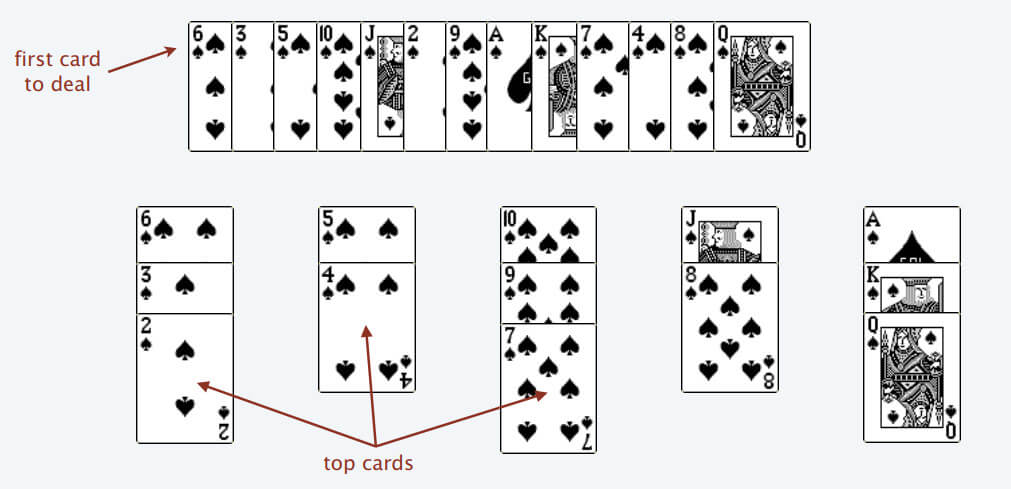
按照上述规则执行,可以算出最长递增子序列,牌的堆数就是最长递增子序列的长度,证明略。

我们只要把处理扑克牌的过程编程写出来即可。每次处理一张扑克牌不是要找一个合适的牌堆顶来放吗,牌堆顶的牌不是有序吗,这就能用到二分查找了:用二分查找来搜索当前牌应放置的位置。
class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
vector<int> top(nums.size());
// 牌堆数初始化为 0
int piles = 0;
for (int i = 0; i < nums.size(); i++) {
// 要处理的扑克牌
int poker = nums[i];
/***** 搜索左侧边界的二分查找 *****/
int left = 0, right = piles;
while (left < right) {
int mid = (left + right) / 2;
if (top[mid] > poker) {
right = mid;
} else if (top[mid] < poker) {
left = mid + 1;
} else {
right = mid;
}
}
/*********************************/
// 没找到合适的牌堆,新建一堆
if (left == piles) piles++;
// 把这张牌放到牌堆顶
top[left] = poker;
}
// 牌堆数就是 LIS 长度
return piles;
}
};
拓展到二维
题目
给你一个二维整数数组 envelopes ,其中 envelopes[i] = [wi, hi] ,表示第 i 个信封的宽度和高度。
当另一个信封的宽度和高度都比这个信封大的时候,这个信封就可以放进另一个信封里,如同俄罗斯套娃一样。
请计算 最多能有多少个 信封能组成一组“俄罗斯套娃”信封(即可以把一个信封放到另一个信封里面)。
注意:不允许旋转信封。
示例 1:
输入:envelopes = [[5,4],[6,4],[6,7],[2,3]]
输出:3
解释:最多信封的个数为 3, 组合为: [2,3] => [5,4] => [6,7]。
示例 2:
输入:envelopes = [[1,1],[1,1],[1,1]]
输出:1
提示:
1 <= envelopes.length <= 105envelopes[i].length == 21 <= wi, hi <= 105
思路
这道题目其实是最长递增子序列的一个变种,因为每次合法的嵌套是大的套小的,相当于在二维平面中找一个最长递增的子序列,其长度就是最多能嵌套的信封个数。
前面说的标准 LIS 算法只能在一维数组中寻找最长子序列,而我们的信封是由 (w, h) 这样的二维数对形式表示的,如何把 LIS 算法运用过来呢?

读者也许会想,通过 w × h 计算面积,然后对面积进行标准的 LIS 算法。但是稍加思考就会发现这样不行,比如 1 × 10 大于 3 × 3,但是显然这样的两个信封是无法互相嵌套的。
这道题的解法比较巧妙:
先对宽度 w 进行升序排序,如果遇到 w 相同的情况,则按照高度 h 降序排序;之后把所有的 h 作为一个数组,在这个数组上计算 LIS 的长度就是答案。
画个图理解一下,先对这些数对进行排序:

然后在 h 上寻找最长递增子序列,这个子序列就是最优的嵌套方案:

那么为什么这样就可以找到可以互相嵌套的信封序列呢?稍微思考一下就明白了:
首先,对宽度 w 从小到大排序,确保了 w 这个维度可以互相嵌套,所以我们只需要专注高度 h 这个维度能够互相嵌套即可。
其次,两个 w 相同的信封不能相互包含,所以对于宽度 w 相同的信封,对高度 h 进行降序排序,保证二维 LIS 中不存在多个 w 相同的信封(因为题目说了长宽相同也无法嵌套)。
class Solution {
public:
// envelopes = { { w, h }, { w, h }...}
int maxEnvelopes(vector<vector<int>>& envelopes) {
int n = envelopes.size();
// 按宽度升序排列,如果宽度一样,则按高度降序排列
sort(envelopes.begin(), envelopes.end(), [](vector<int>& a, vector<int>& b) {
return a[0] == b[0] ? b[1] > a[1] : a[0] < b[0];
});
// 对高度数组寻找 LIS
vector<int> height(n, 0);
for (int i = 0; i < n; ++i)
height[i] = envelopes[i][1];
return lengthOfLIS(height);
}
int lengthOfLIS(vector<int>& nums) {
// 见前文
}
};
最优子结构原理和dp数组遍历方向
最优子结构详解
「最优子结构」是某些问题的一种特定性质,并不是动态规划问题专有的。也就是说,很多问题其实都具有最优子结构,只是其中大部分不具有重叠子问题,所以我们不把它们归为动态规划系列问题而已。
我先举个很容易理解的例子:假设你们学校有 10 个班,你已经计算出了每个班的最高考试成绩。那么现在我要求你计算全校最高的成绩,你会不会算?当然会,而且你不用重新遍历全校学生的分数进行比较,而是只要在这 10 个最高成绩中取最大的就是全校的最高成绩。
我给你提出的这个问题就符合最优子结构:可以从子问题的最优结果推出更大规模问题的最优结果。让你算每个班的最优成绩就是子问题,你知道所有子问题的答案后,就可以借此推出全校学生的最优成绩这个规模更大的问题的答案。
你看,这么简单的问题都有最优子结构性质,只是因为显然没有重叠子问题,所以我们简单地求最值肯定用不出动态规划。
再举个例子:假设你们学校有 10 个班,你已知每个班的最大分数差(最高分和最低分的差值)。那么现在我让你计算全校学生中的最大分数差,你会不会算?可以想办法算,但是肯定不能通过已知的这 10 个班的最大分数差推到出来。因为这 10 个班的最大分数差不一定就包含全校学生的最大分数差,比如全校的最大分数差可能是 3 班的最高分和 6 班的最低分之差。
这次我给你提出的问题就不符合最优子结构,因为你没办通过每个班的最优值推出全校的最优值,没办法通过子问题的最优值推出规模更大的问题的最优值。
想满足最优子结,子问题之间必须互相独立。全校的最大分数差可能出现在两个班之间,显然子问题不独立,所以这个问题本身不符合最优子结构。
那么遇到这种最优子结构失效情况,怎么办?策略是:改造问题。对于最大分数差这个问题,我们不是没办法利用已知的每个班的分数差吗,那我只能这样写一段暴力代码:
int result = 0;
for (Student a : school) {
for (Student b : school) {
if (a is b) continue;
result = max(result, |a.score - b.score|);
}
}
return result;
改造问题,也就是把问题等价转化:最大分数差,不就等价于最高分数和最低分数的差么,那不就是要求最高和最低分数么,不就是我们讨论的第一个问题么,不就具有最优子结构了么?那现在改变思路,借助最优子结构解决最值问题,再回过头解决最大分数差问题,是不是就高效多了?
当然,上面这个例子太简单了,不过请读者回顾一下,我们做动态规划问题,是不是一直在求各种最值,本质跟我们举的例子没啥区别,无非需要处理一下重叠子问题。
再举个常见但也十分简单的例子,求一棵二叉树的最大值,不难吧(简单起见,假设节点中的值都是非负数):
int maxVal(TreeNode* root) {
if (root == NULL)
return -1;
int left = maxVal(root->left);
int right = maxVal(root->right);
return max(root->val, max(left, right));
}
你看这个问题也符合最优子结构,以 root 为根的树的最大值,可以通过两边子树(子问题)的最大值推导出来,结合刚才学校和班级的例子,很容易理解吧。
当然这也不是动态规划问题,旨在说明,最优子结构并不是动态规划独有的一种性质,能求最值的问题大部分都具有这个性质;但反过来,最优子结构性质作为动态规划问题的必要条件,一定是让你求最值的,以后碰到那种恶心人的最值题,思路往动态规划想就对了,这就是套路。
动态规划不就是从最简单的 base case 往后推导吗,可以想象成一个链式反应,以小博大。但只有符合最优子结构的问题,才有发生这种链式反应的性质。
找最优子结构的过程,其实就是证明状态转移方程正确性的过程,方程符合最优子结构就可以写暴力解了,写出暴力解就可以看出有没有重叠子问题了,有则优化,无则 OK。这也是套路,经常刷题的读者应该能体会。
如何一眼看出重叠子问题
无法判断这个解法是否存在重叠子问题,就无法确定是否可以运用备忘录等方法去优化算法效率。
首先,最简单粗暴的方式就是画图,把递归树画出来,看看有没有重复的节点。

这棵递归树很明显存在重复的节点,所以我们可以通过备忘录避免冗余计算。
但毕竟斐波那契数列问题太简单了,实际的动态规划问题比较复杂,比如二维甚至三维的动态规划,当然也可以画递归树,但不免有些复杂。
比如在 最小路径和问题 中,我们写出了这样一个暴力解法:
int dp(int grid[][], int i, int j) {
if (i == 0 && j == 0) {
return grid[0][0];
}
if (i < 0 || j < 0) {
return INT_MAX;
}
return min(
dp(grid, i - 1, j),
dp(grid, i, j - 1)
) + grid[i][j];
}
你不需要读过前文,光看这个函数代码就能看出来,该函数递归过程中参数 i, j 在不断变化,即「状态」是 (i, j) 的值,你是否可以判断这个解法是否存在重叠子问题呢?
假设输入的 i = 8, j = 7,二维状态的递归树如下图,显然出现了重叠子问题:

但稍加思考就可以知道,其实根本没必要画图,可以通过递归框架直接判断是否存在重叠子问题。
具体操作就是直接删掉代码细节,抽象出该解法的递归框架:
int dp(int[][] grid, int i, int j) {
dp(grid, i - 1, j), // #1
dp(grid, i, j - 1) // #2
}
可以看到 i, j 的值在不断减小,那么我问你一个问题:如果我想从状态 (i, j) 转移到 (i-1, j-1),有几种路径?
显然有两种路径,可以是 (i, j) -> #1 -> #2 或者 (i, j) -> #2 -> #1,不止一种,说明 (i-1, j-1) 会被多次计算,所以一定存在重叠子问题。
再举个稍微复杂的例子,后文 正则表达式问题 的暴力解代码:
bool dp(string s, int i, string p, int j) {
int m = s.size(), n = p.size();
// base case
if (j == n) {
return i == m;
}
if (i == m) {
if ((n - j) % 2 == 1) {
return false;
}
for (; j + 1 < n; j += 2) {
if (p[j + 1] != '*') {
return false;
}
}
return true;
}
bool res = false;
if (s[i] == p[j] || p[j] == '.') {
if (j < n - 1 && p[j + 1] == '*') {
res = dp(s, i, p, j + 2) || dp(s, i + 1, p, j);
} else {
res = dp(s, i + 1, p, j + 1);
}
} else {
if (j < n - 1 && p[j + 1] == '*') {
res = dp(s, i, p, j + 2);
} else {
res = false;
}
}
return res;
}
代码有些复杂对吧,如果画图的话有些麻烦,但我们不画图,直接忽略所有细节代码和条件分支,只抽象出递归框架:
boolean dp(String s, int i, String p, int j) {
dp(s, i, p, j + 2); // #1
dp(s, i + 1, p, j); // #2
dp(s, i + 1, p, j + 1); // #3
}
和上一题一样,这个解法的「状态」也是 (i, j) 的值,那么我继续问你问题:如果我想从状态 (i, j) 转移到 (i+2, j+2),有几种路径?
显然,至少有两条路径:(i, j) -> #1 -> #2 -> #2 和 (i, j) -> #3 -> #3,这就说明这个解法存在巨量重叠子问题。
所以,不用画图就知道这个解法也存在重叠子问题,需要用备忘录技巧去优化。
dp数组的大小设置
比如说后文 编辑距离问题,首先讲的是自顶向下的递归解法,实现了这样一个 dp 函数:
class Solution {
public:
int minDistance(string s1, string s2) {
int m = s1.length(), n = s2.length();
// 按照 dp 函数的定义,计算 s1 和 s2 的最小编辑距离
return dp(s1, m - 1, s2, n - 1);
}
// 定义:s1[0..i] 和 s2[0..j] 的最小编辑距离是 dp(s1, i, s2, j)
int dp(string s1, int i, string s2, int j) {
// 处理 base case
if (i == -1) {
return j + 1;
}
if (j == -1) {
return i + 1;
}
// 进行状态转移
if (s1[i] == s2[j]) {
return dp(s1, i - 1, s2, j - 1);
} else {
return min({
dp(s1, i, s2, j - 1) + 1,
dp(s1, i - 1, s2, j) + 1,
dp(s1, i - 1, s2, j - 1) + 1
});
}
}
private:
// Helper function to find the minimum of three integers
int min(std::initializer_list<int> ilist) {
return *std::min_element(ilist.begin(), ilist.end());
}
};
然后改造成了自底向上的迭代解法:
// 注意:cpp 代码由 chatGPT🤖 根据我的 java 代码翻译,旨在帮助不同背景的读者理解算法逻辑。
// 本代码不保证正确性,仅供参考。如有疑惑,可以参照我写的 java 代码对比查看。
class Solution {
public:
int minDistance(string s1, string s2) {
int m = s1.length(), n = s2.length();
// 定义:s1[0..i] 和 s2[0..j] 的最小编辑距离是 dp[i+1][j+1]
vector<vector<int>> dp(m + 1, vector<int>(n + 1));
// 初始化 base case
for (int i = 1; i <= m; i++)
dp[i][0] = i;
for (int j = 1; j <= n; j++)
dp[0][j] = j;
// 自底向上求解
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
// 进行状态转移
if (s1[i-1] == s2[j-1]) {
dp[i][j] = dp[i - 1][j - 1];
} else {
dp[i][j] = min(
dp[i - 1][j] + 1,
min(dp[i][j - 1] + 1,
dp[i - 1][j - 1] + 1)
);
}
}
}
// 按照 dp 数组的定义,存储 s1 和 s2 的最小编辑距离
return dp[m][n];
}
};
这两种解法思路是完全相同的,但就有提问,为什么迭代解法中的 dp 数组初始化大小要设置为 int[m+1][n+1]?为什么 s1[0..i] 和 s2[0..j] 的最小编辑距离要存储在 dp[i+1][j+1] 中,有一位索引偏移?
能不能模仿 dp 函数的定义,把 dp 数组初始化为 int[m][n],然后让 s1[0..i] 和 s2[0..j] 的最小编辑距离要存储在 dp[i][j] 中?
理论上,你怎么定义都可以,只要根据定义处理好 base case 就可以。
你看 dp 函数的定义,dp(s1, i, s2, j) 计算 s1[0..i] 和 s2[0..j] 的编辑距离,那么 i, j 等于 -1 时代表空串的 base case,所以函数开头处理了这两种特殊情况。
再看 dp 数组,你当然也可以定义 dp[i][j] 存储 s1[0..i] 和 s2[0..j] 的编辑距离,但问题是 base case 怎么搞?索引怎么能是 -1 呢?
所以我们把 dp 数组初始化为 int[m+1][n+1],让索引整体偏移一位,把索引 0 留出来作为 base case 表示空串,然后定义 dp[i+1][j+1] 存储 s1[0..i] 和 s2[0..j] 的编辑距离。
dp数组的遍历方向
我们拿二维 dp 数组来举例,有时候我们是正向遍历:
int[][] dp = new int[m][n];
for (int i = 0; i < m; i++)
for (int j = 0; j < n; j++)
// 计算 dp[i][j]
有时候我们反向遍历:
for (int i = m - 1; i >= 0; i--)
for (int j = n - 1; j >= 0; j--)
// 计算 dp[i][j]
有时候可能会斜向遍历:
// 斜着遍历数组
for (int l = 2; l <= n; l++) {
for (int i = 0; i <= n - l; i++) {
int j = l + i - 1;
// 计算 dp[i][j]
}
}
甚至更让人迷惑的是,有时候发现正向反向遍历都可以得到正确答案,比如我们在 团灭股票问题 中有的地方就正反皆可。
如果仔细观察的话可以发现其中的原因,你只要把住两点就行了:
1、遍历的过程中,所需的状态必须是已经计算出来的。
2、遍历结束后,存储结果的那个位置必须已经被计算出来。
下面来具体解释上面两个原则是什么意思。
比如编辑距离这个经典的问题,详解见后文 编辑距离详解,我们通过对 dp 数组的定义,确定了 base case 是 dp[..][0] 和 dp[0][..],最终答案是 dp[m][n];而且我们通过状态转移方程知道 dp[i][j] 需要从 dp[i-1][j], dp[i][j-1], dp[i-1][j-1] 转移而来,如下图:
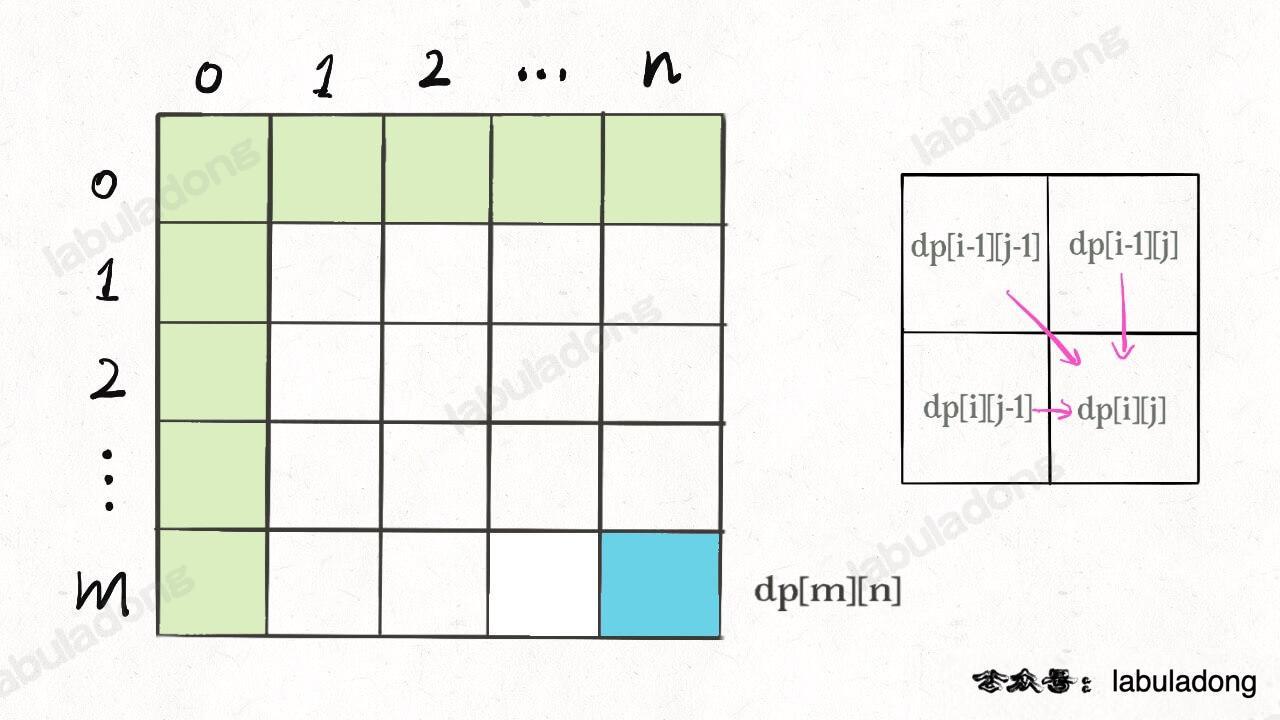
那么,参考刚才说的两条原则,你该怎么遍历 dp 数组?肯定是正向遍历:
for (int i = 1; i < m; i++)
for (int j = 1; j < n; j++)
// 通过 dp[i-1][j], dp[i][j - 1], dp[i-1][j-1]
// 计算 dp[i][j]
因为,这样每一步迭代的左边、上边、左上边的位置都是 base case 或者之前计算过的,而且最终结束在我们想要的答案 dp[m][n]。
再举一例,回文子序列问题,详见后文 子序列问题模板,我们通过过对 dp 数组的定义,确定了 base case 处在中间的对角线,dp[i][j] 需要从 dp[i+1][j], dp[i][j-1], dp[i+1][j-1] 转移而来,想要求的最终答案是 dp[0][n-1],如下图:

这种情况根据刚才的两个原则,就可以有两种正确的遍历方式:
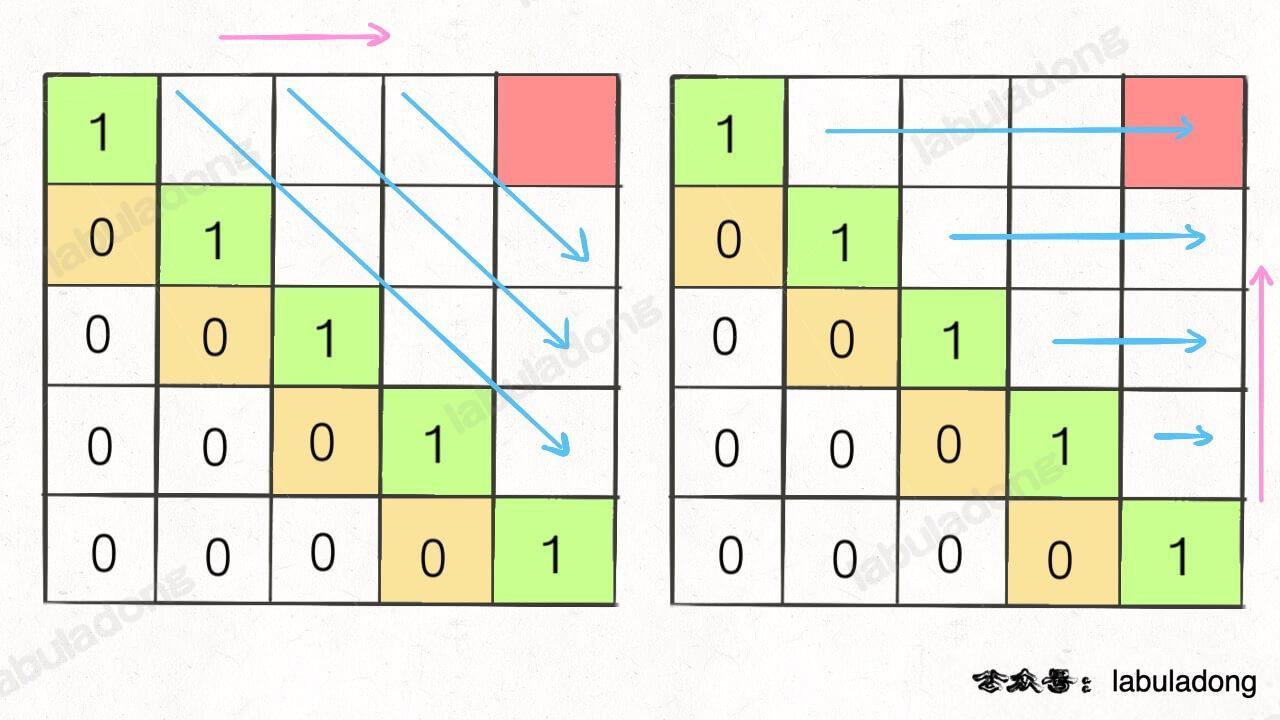
要么从左至右斜着遍历,要么从下向上从左到右遍历,这样才能保证每次 dp[i][j] 的左边、下边、左下边已经计算完毕,得到正确结果。
现在,你应该理解了这两个原则,主要就是看 base case 和最终结果的存储位置,保证遍历过程中使用的数据都是计算完毕的就行,有时候确实存在多种方法可以得到正确答案,可根据个人口味自行选择。
base case和备忘录的初始值设定
题目
输入为一个 n * n 的二维数组 matrix,请你计算从第一行落到最后一行,经过的路径和最小为多少。
int minFallingPathSum(vector<vector<int>>& matrix);
就是说你可以站在 matrix 的第一行的任意一个元素,需要下降到最后一行。
每次下降,可以向下、向左下、向右下三个方向移动一格。也就是说,可以从 matrix[i][j] 降到 matrix[i+1][j] 或 matrix[i+1][j-1] 或 matrix[i+1][j+1] 三个位置。
请你计算下降的「最小路径和」,比如说题目给了一个例子:
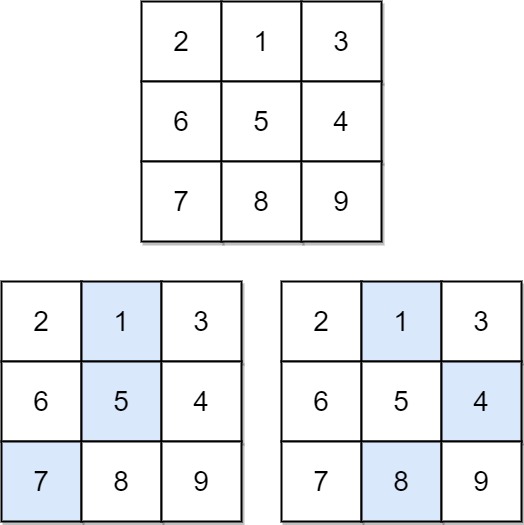
输入:matrix = [[2,1,3],[6,5,4],[7,8,9]]
输出:13
最小的路径和为 13,具体是如下几种路径:
思路
首先我们可以定义一个 dp 函数:
int dp(int** matrix, int i, int j);
这个 dp 函数的含义如下:
从第一行(matrix[0][..])向下落,落到位置 matrix[i][j] 的最小路径和为 dp(matrix, i, j)。
根据这个定义,我们可以把主函数的逻辑写出来:
int minFallingPathSum(vector<vector<int>>& matrix) {
int n = matrix.size();
int res = INT_MAX;
// 终点可能在最后一行的任意一列
for (int j = 0; j < n; j++) {
res = min(res, dp(matrix, n - 1, j));
}
return res;
}
因为我们可能落到最后一行的任意一列,所以要穷举一下,看看落到哪一列才能得到最小的路径和。
接下来看看 dp 函数如何实现。
对于 matrix[i][j],只有可能从 matrix[i-1][j], matrix[i-1][j-1], matrix[i-1][j+1] 这三个位置转移过来。
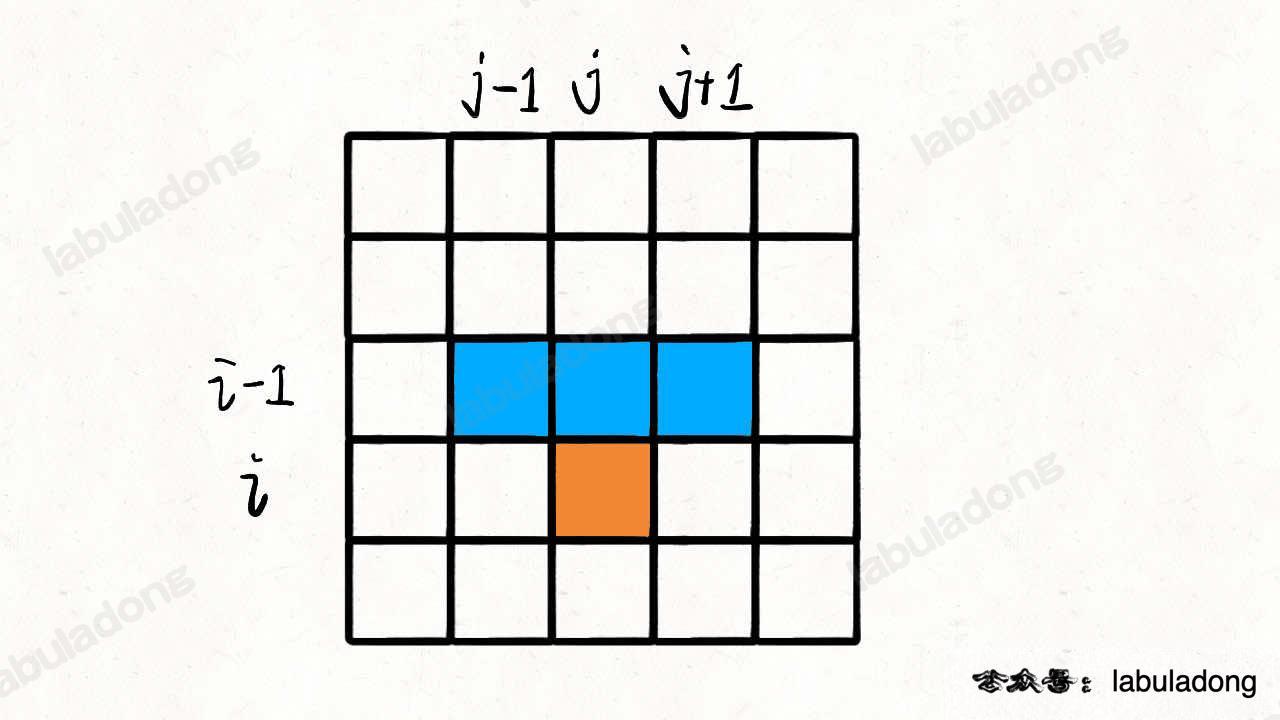
那么,只要知道到达 (i-1, j), (i-1, j-1), (i-1, j+1) 这三个位置的最小路径和,加上 matrix[i][j] 的值,就能够计算出来到达位置 (i, j) 的最小路径和:
int dp(vector<vector<int>>& matrix, int i, int j) {
// 非法索引检查
if (i < 0 || j < 0 ||
i >= matrix.size() ||
j >= matrix[0].size()) {
// 返回一个特殊值
return 99999;
}
// base case
if (i == 0) {
return matrix[i][j];
}
// 状态转移
return matrix[i][j] + min({
dp(matrix, i - 1, j),
dp(matrix, i - 1, j - 1),
dp(matrix, i - 1, j + 1)
});
}
int min(int a, int b, int c) {
return min(a, min(b, c));
}
当然,上述代码是暴力穷举解法,我们可以用备忘录的方法消除重叠子问题,完整代码如下:
class Solution {
public:
int minFallingPathSum(vector<vector<int>>& matrix) {
int n = matrix.size();
int res = INT_MAX;
// 备忘录里的值初始化为 66666
memo = vector<vector<int>>(n, vector<int>(n, 66666));
// 终点可能在 matrix[n-1] 的任意一列
for (int j = 0; j < n; j++) {
res = min(res, dp(matrix, n - 1, j));
}
return res;
}
private:
// 备忘录
vector<vector<int>> memo;
int dp(vector<vector<int>>& matrix, int i, int j) {
// 1、索引合法性检查
if (i < 0 || j < 0 || i >= matrix.size() || j >= matrix[0].size()) {
return 99999;
}
// 2、base case
if (i == 0) {
return matrix[0][j];
}
// 3、查找备忘录,防止重复计算
if (memo[i][j] != 66666) {
return memo[i][j];
}
// 进行状态转移
memo[i][j] = matrix[i][j] + min({dp(matrix, i - 1, j), dp(matrix, i - 1, j - 1), dp(matrix, i - 1, j + 1)});
return memo[i][j];
}
int min(initializer_list<int> values) {
return *min_element(values.begin(), values.end());
}
};
本文对于这个 dp 函数仔细探讨三个问题:
1、对于索引的合法性检测,返回值为什么是 99999?其他的值行不行?
2、base case 为什么是 i == 0?
3、备忘录 memo 的初始值为什么是 66666?其他值行不行?
首先,说说 base case 为什么是 i == 0,返回值为什么是 matrix[0][j],这是根据 dp 函数的定义所决定的。
回顾我们的 dp 函数定义:
从第一行(matrix[0][..])向下落,落到位置 matrix[i][j] 的最小路径和为 dp(matrix, i, j)。
根据这个定义,我们就是从 matrix[0][j] 开始下落。那如果我们想落到的目的地就是 i == 0,所需的路径和当然就是 matrix[0][j] 呗。
再说说备忘录 memo 的初始值为什么是 66666,这是由题目给出的数据范围决定的。
备忘录 memo 数组的作用是什么?
就是防止重复计算,将 dp(matrix, i, j) 的计算结果存进 memo[i][j],遇到重复计算可以直接返回。
那么,我们必须要知道 memo[i][j] 到底存储计算结果没有,对吧?如果存结果了,就直接返回;没存,就去递归计算。
所以,memo 的初始值一定得是特殊值,和合法的答案有所区分。
我们回过头看看题目给出的数据范围:
matrix是n x n的二维数组,其中1 <= n <= 100;对于二维数组中的元素,有-100 <= matrix[i][j] <= 100。
假设 matrix 的大小是 100 x 100,所有元素都是 100,那么从第一行往下落,得到的路径和就是 100 x 100 = 10000,也就是最大的合法答案。
类似的,依然假设 matrix 的大小是 100 x 100,所有元素是 -100,那么从第一行往下落,就得到了最小的合法答案 -100 x 100 = -10000。
也就是说,这个问题的合法结果会落在区间 [-10000, 10000] 中。
所以,我们 memo 的初始值就要避开区间 [-10000, 10000],换句话说,memo 的初始值只要在区间 (-inf, -10001] U [10001, +inf) 中就可以。
最后,说说对于不合法的索引,返回值应该如何确定,这需要根据我们状态转移方程的逻辑确定。
对于这道题,状态转移的基本逻辑如下:
int dp(int[][] matrix, int i, int j) {
return matrix[i][j] + min(
dp(matrix, i - 1, j),
dp(matrix, i - 1, j - 1),
dp(matrix, i - 1, j + 1)
);
}
显然,i - 1, j - 1, j + 1 这几个运算可能会造成索引越界,对于索引越界的 dp 函数,应该返回一个不可能被取到的值。
因为我们调用的是 min 函数,最终返回的值是最小值,所以对于不合法的索引,只要 dp 函数返回一个永远不会被取到的最大值即可。
刚才说了,合法答案的区间是 [-10000, 10000],所以我们的返回值只要大于 10000 就相当于一个永不会取到的最大值。
换句话说,只要返回区间 [10001, +inf) 中的一个值,就能保证不会被取到。
至此,我们就把动态规划相关的三个细节问题举例说明了。
拓展延伸一下,建议大家做题时,除了题意本身,一定不要忽视题目给定的其他信息。
本文举的例子,测试用例数据范围可以确定「什么是特殊值」,从而帮助我们将思路转化成代码。
除此之外,数据范围还可以帮我们估算算法的时间/空间复杂度。
比如说,有的算法题,你只想到一个暴力求解思路,时间复杂度比较高。如果发现题目给定的数据量比较大,那么肯定可以说明这个求解思路有问题或者存在优化的空间。
除了数据范围,有时候题目还会限制我们算法的时间复杂度,这种信息其实也暗示着一些东西。
比如要求我们的算法复杂度是 O(NlogN),你想想怎么才能搞出一个对数级别的复杂度呢?
肯定得用到 二分搜索 或者二叉树相关的数据结构,比如 TreeMap,PriorityQueue 之类的对吧。
再比如,有时候题目要求你的算法时间复杂度是 O(MN),这可以联想到什么?
可以大胆猜测,常规解法是用 回溯算法 暴力穷举,但是更好的解法是动态规划,而且是一个二维动态规划,需要一个 M * N 的二维 dp 数组,所以产生了这样一个时间复杂度。
如果你早就胸有成竹了,那就当我没说,毕竟猜测也不一定准确;但如果你本来就没啥解题思路,那有了这些推测之后,最起码可以给你的思路一些方向吧?
总之,多动脑筋,不放过任何蛛丝马迹,你不成为刷题小能手才怪。
子序列类型问题
经典动态规划:编辑距离
题目
给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
示例 1:
输入:word1 = "horse", word2 = "ros"
输出:3
解释:
horse -> rorse (将 'h' 替换为 'r')
rorse -> rose (删除 'r')
rose -> ros (删除 'e')
示例 2:
输入:word1 = "intention", word2 = "execution"
输出:5
解释:
intention -> inention (删除 't')
inention -> enention (将 'i' 替换为 'e')
enention -> exention (将 'n' 替换为 'x')
exention -> exection (将 'n' 替换为 'c')
exection -> execution (插入 'u')
提示:
0 <= word1.length, word2.length <= 500word1和word2由小写英文字母组成
思路
编辑距离问题就是给我们两个字符串 s1 和 s2,只能用三种操作,让我们把 s1 变成 s2,求最少的操作数。需要明确的是,不管是把 s1 变成 s2 还是反过来,结果都是一样的,所以后文就以 s1 变成 s2 举例。
后文 最长公共子序列 说过,解决两个字符串的动态规划问题,一般都是用两个指针 i, j 分别指向两个字符串的最后,然后一步步往前移动,缩小问题的规模。
设两个字符串分别为 "rad" 和 "apple",为了把 s1 变成 s2,算法会这样进行:

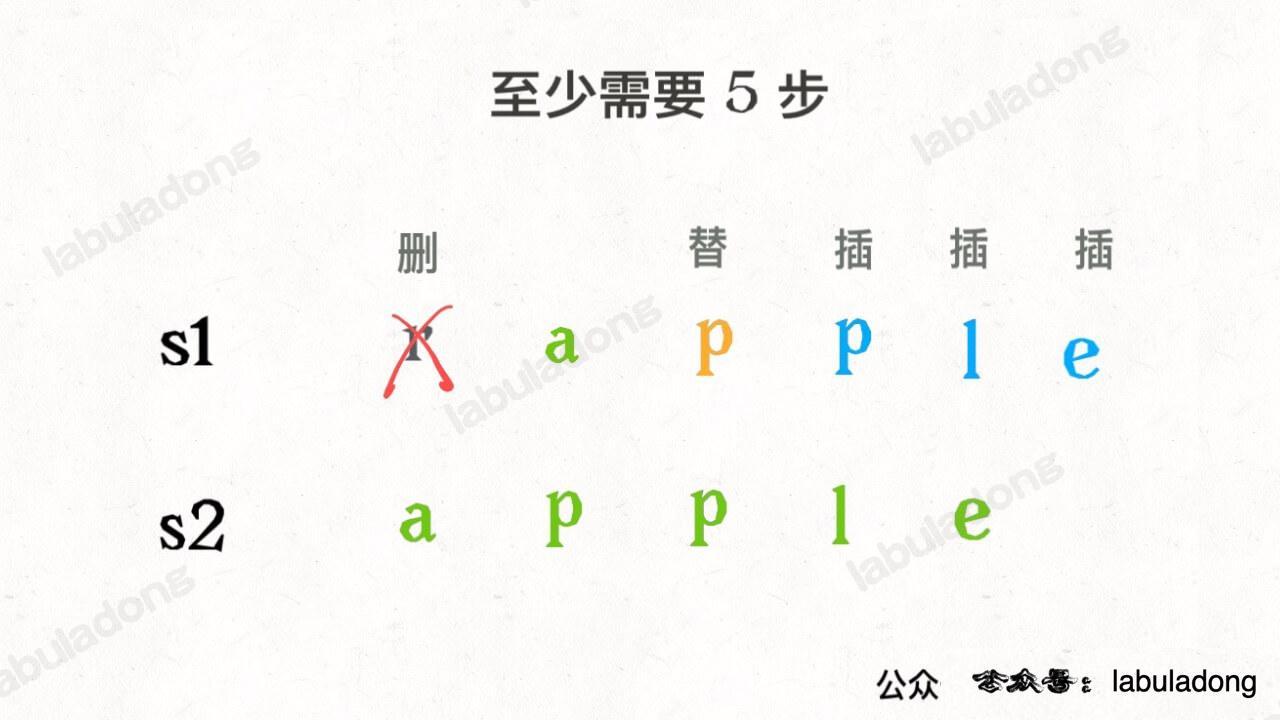
请记住这个 GIF 过程,这样就能算出编辑距离。关键在于如何做出正确的操作,稍后会讲。
根据上面的 GIF,可以发现操作不只有三个,其实还有第四个操作,就是什么都不要做(skip)。比如这个情况:

因为这两个字符本来就相同,为了使编辑距离最小,显然不应该对它们有任何操作,直接往前移动 i, j 即可。
还有一个很容易处理的情况,就是 j 走完 s2 时,如果 i 还没走完 s1,那么只能用删除操作把 s1 缩短为 s2。比如这个情况:
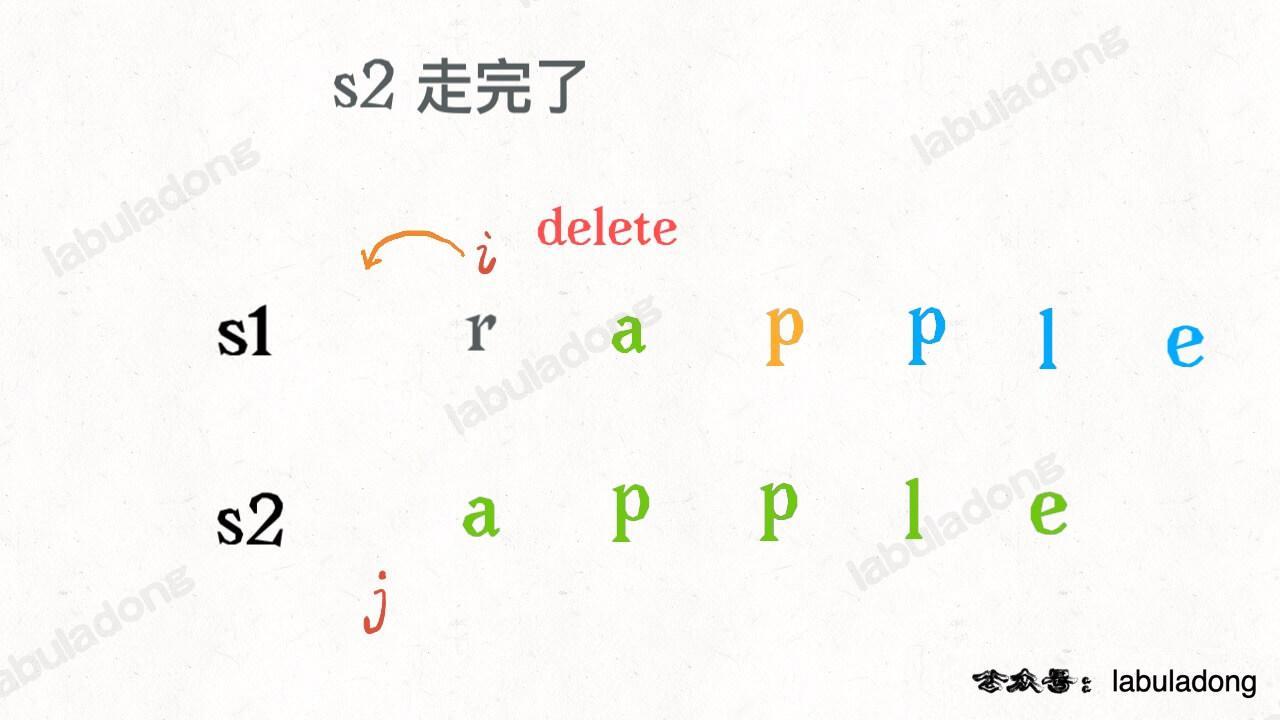
类似的,如果 i 走完 s1 时 j 还没走完了 s2,那就只能用插入操作把 s2 剩下的字符全部插入 s1。等会会看到,这两种情况就是算法的 base case。
代码
先梳理一下之前的思路:
base case 是 i 走完 s1 或 j 走完 s2,可以直接返回另一个字符串剩下的长度。
对于每对儿字符 s1[i] 和 s2[j],可以有四种操作:
if s1[i] == s2[j]:
啥都别做(skip)
i, j 同时向前移动
else:
三选一:
插入(insert)
删除(delete)
替换(replace)
有这个框架,问题就已经解决了。读者也许会问,这个「三选一」到底该怎么选择呢?很简单,全试一遍,哪个操作最后得到的编辑距离最小,就选谁。这里需要递归技巧,先看下暴力解法代码:
class Solution {
public:
int minDistance(string s1, string s2) {
int m = s1.size(), n = s2.size();
// i,j 初始化指向最后一个索引
return dp(s1, m - 1, s2, n - 1);
}
private:
// 定义:返回 s1[0..i] 和 s2[0..j] 的最小编辑距离
int dp(string &s1, int i, string &s2, int j) {
// base case
if (i == -1) return j + 1;
if (j == -1) return i + 1;
if (s1[i] == s2[j]) {
return dp(s1, i - 1, s2, j - 1); // 啥都不做
}
return min({
dp(s1, i, s2, j - 1) + 1, // 插入
dp(s1, i - 1, s2, j) + 1, // 删除
dp(s1, i - 1, s2, j - 1) + 1 // 替换
});
}
};
下面来详细解释一下这段递归代码,base case 应该不用解释了,主要解释一下递归部分。
先来看这段代码:
if s1[i] == s2[j]:
return dp(s1, i - 1, s2, j - 1); # 啥都不做
# 解释:
# 本来就相等,不需要任何操作
# s1[0..i] 和 s2[0..j] 的最小编辑距离等于
# s1[0..i-1] 和 s2[0..j-1] 的最小编辑距离
# 也就是说 dp(i, j) 等于 dp(i-1, j-1)
如果 s1[i] != s2[j],就要对三个操作递归了,稍微需要点思考:
dp(s1, i, s2, j - 1) + 1, # 插入
# 解释:
# 我直接在 s1[i] 插入一个和 s2[j] 一样的字符
# 那么 s2[j] 就被匹配了,前移 j,继续跟 i 对比
# 别忘了操作数加一

dp(s1, i - 1, s2, j) + 1, # 删除
# 解释:
# 我直接把 s[i] 这个字符删掉
# 前移 i,继续跟 j 对比
# 操作数加一

dp(s1, i - 1, s2, j - 1) + 1 # 替换
# 解释:
# 我直接把 s1[i] 替换成 s2[j],这样它俩就匹配了
# 同时前移 i,j 继续对比
# 操作数加一

现在,你应该完全理解这段短小精悍的代码了。还有点小问题就是,这个解法是暴力解法,存在重叠子问题,需要用动态规划技巧来优化。
动态规划优化
备忘录很好加,原来的代码稍加修改即可:
class Solution {
private:
// 备忘录
vector<vector<int>> memo;
int dp(string s1, int i, string s2, int j) {
if (i == -1) return j + 1;
if (j == -1) return i + 1;
// 查备忘录,避免重叠子问题
if (memo[i][j] != -1) {
return memo[i][j];
}
// 状态转移,结果存入备忘录
if (s1[i] == s2[j]) {
memo[i][j] = dp(s1, i - 1, s2, j - 1);
} else {
memo[i][j] = min(
dp(s1, i, s2, j - 1) + 1,
dp(s1, i - 1, s2, j) + 1,
dp(s1, i - 1, s2, j - 1) + 1
);
}
return memo[i][j];
}
public:
int minDistance(string word1, string word2) {
int m = word1.size(), n = word2.size();
// 备忘录初始化为特殊值,代表还未计算
memo = vector<vector<int>>(m, vector<int>(n, -1));
return dp(word1, m - 1, word2, n - 1);
}
int min(int a, int b, int c) {
return min(a, min(b, c));
}
};
主要说下 DP table 的解法:
首先明确 dp 数组的含义,dp 数组是一个二维数组,长这样:
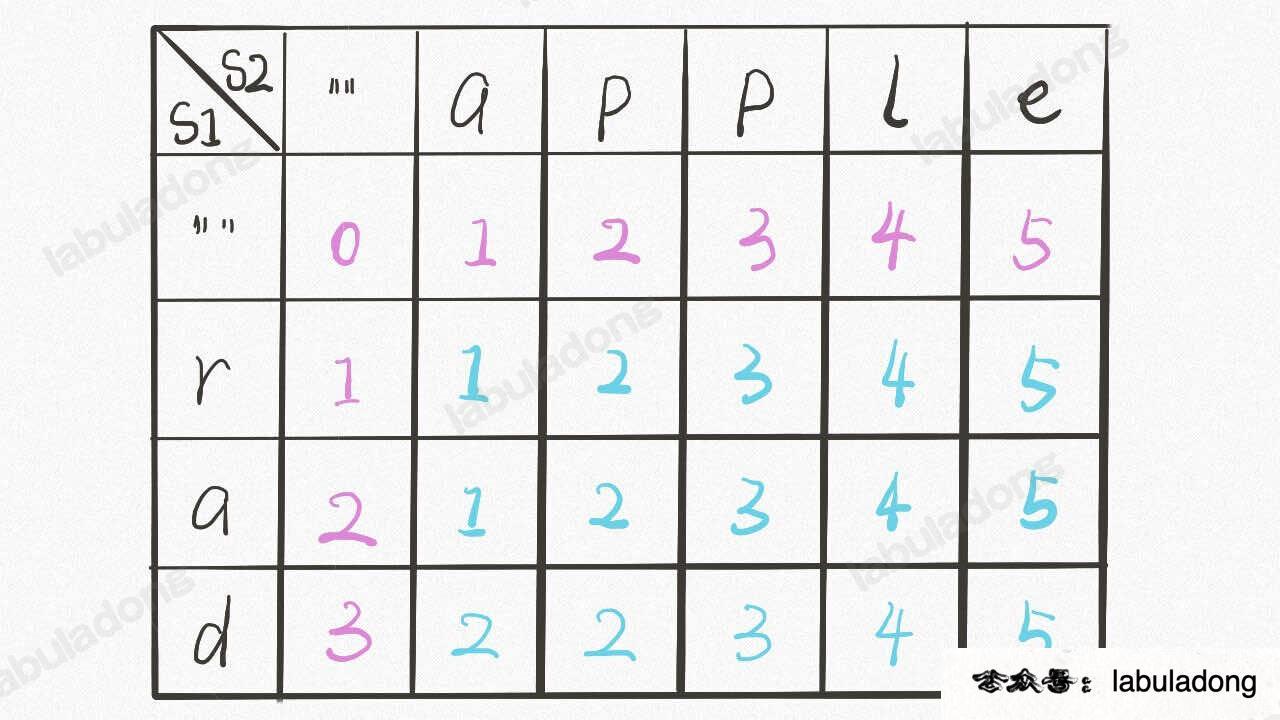
有了之前递归解法的铺垫,应该很容易理解。dp[..][0] 和 dp[0][..] 对应 base case,dp[i][j] 的含义和之前的 dp 函数类似:
int dp(String s1, int i, String s2, int j)
// 返回 s1[0..i] 和 s2[0..j] 的最小编辑距离
dp[i-1][j-1]
// 存储 s1[0..i] 和 s2[0..j] 的最小编辑距离
dp 函数的 base case 是 i, j 等于 -1,而数组索引至少是 0,所以 dp 数组会偏移一位。
既然 dp 数组和递归 dp 函数含义一样,也就可以直接套用之前的思路写代码,唯一不同的是,DP table 是自底向上求解,递归解法是自顶向下求解:
class Solution {
public:
int minDistance(string s1, string s2) {
int m = s1.length(), n = s2.length();
// 定义:s1[0..i] 和 s2[0..j] 的最小编辑距离是 dp[i+1][j+1]
vector<vector<int>> dp(m + 1, vector<int>(n + 1, 0));
// base case
for (int i = 1; i <= m; i++)
dp[i][0] = i;
for (int j = 1; j <= n; j++)
dp[0][j] = j;
// 自底向上求解
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (s1[i-1] == s2[j-1]) {
dp[i][j] = dp[i - 1][j - 1];
} else {
dp[i][j] = min(
dp[i - 1][j] + 1,
dp[i][j - 1] + 1,
dp[i - 1][j - 1] + 1
);
}
}
}
// 储存着整个 s1 和 s2 的最小编辑距离
return dp[m][n];
}
int min(int a, int b, int c) {
return std::min(a, std::min(b, c));
}
};
扩展延伸
一般来说,处理两个字符串的动态规划问题,都是按本文的思路处理,建立 DP table。为什么呢,因为易于找出状态转移的关系,比如编辑距离的 DP table:

还有一个细节,既然每个 dp[i][j] 只和它附近的三个状态有关,空间复杂度是可以压缩成 O(min(M, N)) 的(M,N 是两个字符串的长度)。不难,但是可解释性大大降低,读者可以自己尝试优化一下。
你可能还会问,这里只求出了最小的编辑距离,那具体的操作是什么?
这个其实很简单,代码稍加修改,给 dp 数组增加额外的信息即可:
class Node {
public:
int val;
int choice;
// 0 代表啥都不做
// 1 代表插入
// 2 代表删除
// 3 代表替换
};
Node** dp;
val 属性就是之前的 dp 数组的数值,choice 属性代表操作。在做最优选择时,顺便把操作记录下来,然后就从结果反推具体操作。
我们的最终结果不是 dp[m][n] 吗,这里的 val 存着最小编辑距离,choice 存着最后一个操作,比如说是插入操作,那么就可以左移一格:
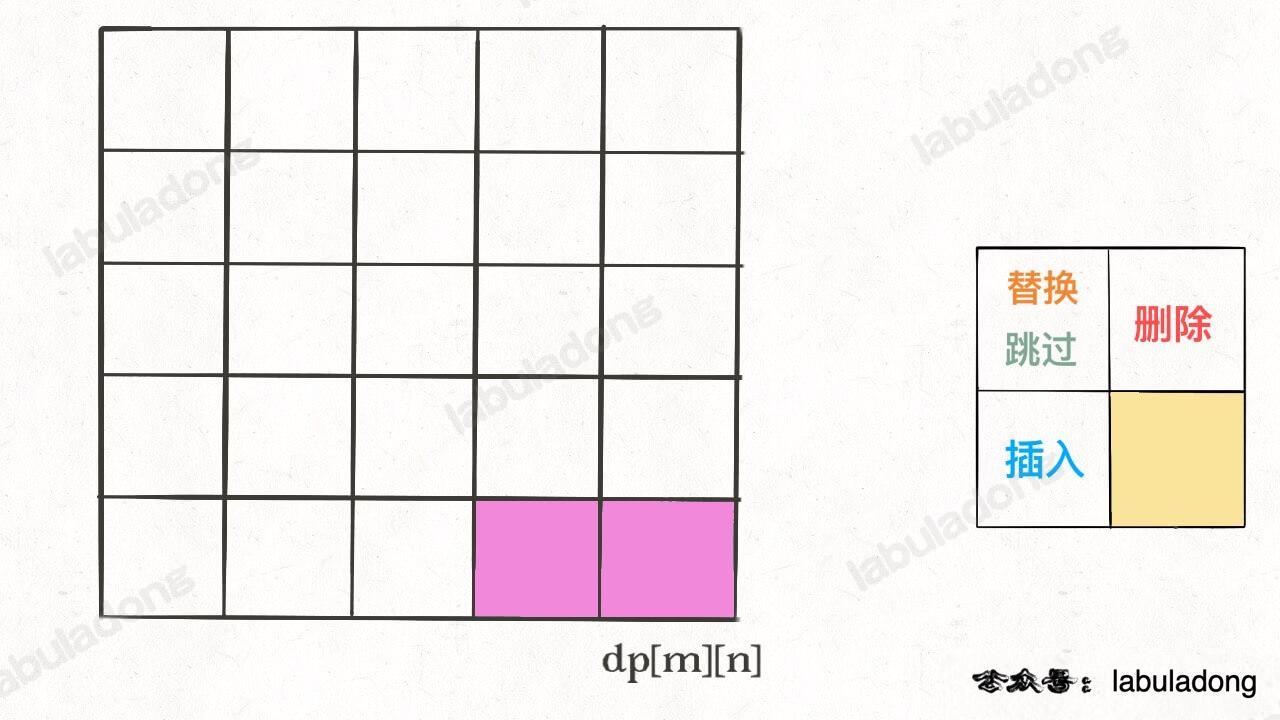
重复此过程,可以一步步回到起点 dp[0][0],形成一条路径,按这条路径上的操作进行编辑,就是最佳方案。
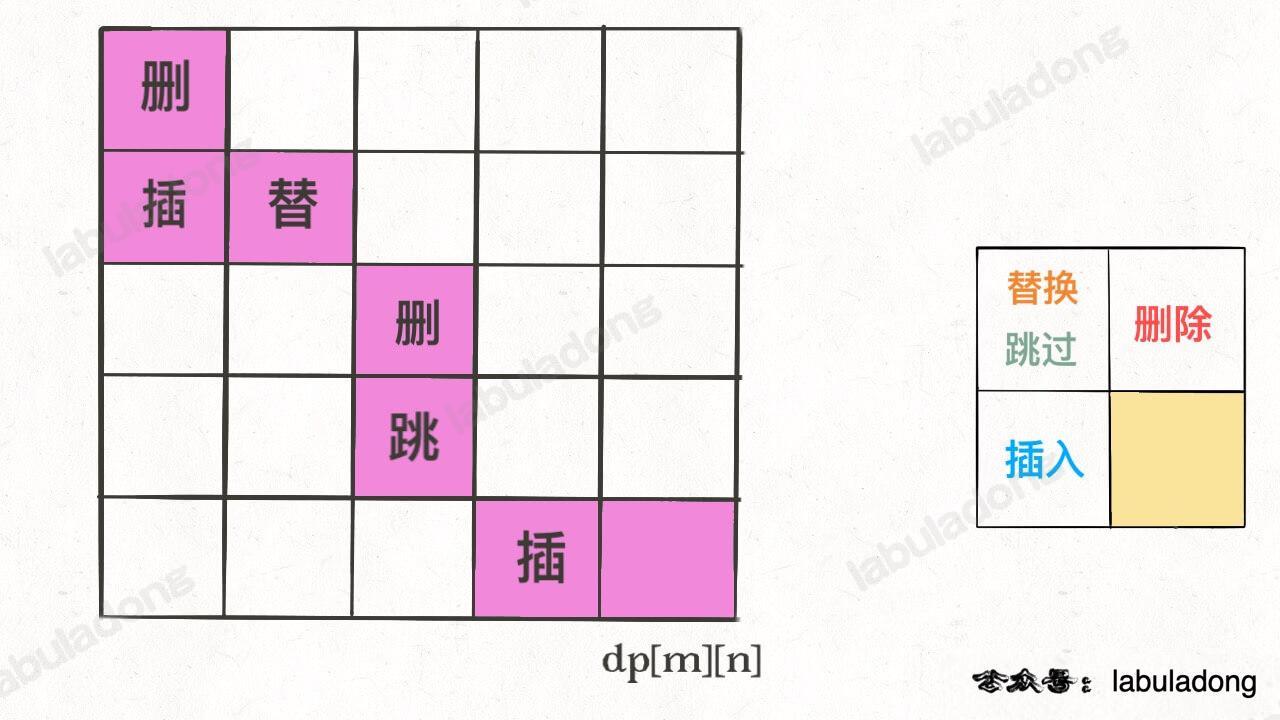
应大家的要求,我把这个思路也写出来,你可以自己运行试一下:
int minDistance(String s1, String s2) {
int m = s1.length(), n = s2.length();
Node[][] dp = new Node[m + 1][n + 1];
// base case
for (int i = 0; i <= m; i++) {
// s1 转化成 s2 只需要删除一个字符
dp[i][0] = new Node(i, 2);
}
for (int j = 1; j <= n; j++) {
// s1 转化成 s2 只需要插入一个字符
dp[0][j] = new Node(j, 1);
}
// 状态转移方程
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (s1.charAt(i-1) == s2.charAt(j-1)){
// 如果两个字符相同,则什么都不需要做
Node node = dp[i - 1][j - 1];
dp[i][j] = new Node(node.val, 0);
} else {
// 否则,记录代价最小的操作
dp[i][j] = minNode(
dp[i - 1][j],
dp[i][j - 1],
dp[i-1][j-1]
);
// 并且将编辑距离加一
dp[i][j].val++;
}
}
}
// 根据 dp table 反推具体操作过程并打印
printResult(dp, s1, s2);
return dp[m][n].val;
}
// 计算 delete, insert, replace 中代价最小的操作
Node minNode(Node a, Node b, Node c) {
Node res = new Node(a.val, 2);
if (res.val > b.val) {
res.val = b.val;
res.choice = 1;
}
if (res.val > c.val) {
res.val = c.val;
res.choice = 3;
}
return res;
}
最后,printResult 函数反推结果并把具体的操作打印出来:
void printResult(Node[][] dp, String s1, String s2) {
int rows = dp.length;
int cols = dp[0].length;
int i = rows - 1, j = cols - 1;
System.out.println("Change s1=" + s1 + " to s2=" + s2 + ":\n");
while (i != 0 && j != 0) {
char c1 = s1.charAt(i - 1);
char c2 = s2.charAt(j - 1);
int choice = dp[i][j].choice;
System.out.print("s1[" + (i - 1) + "]:");
switch (choice) {
case 0:
// 跳过,则两个指针同时前进
System.out.println("skip '" + c1 + "'");
i--; j--;
break;
case 1:
// 将 s2[j] 插入 s1[i],则 s2 指针前进
System.out.println("insert '" + c2 + "'");
j--;
break;
case 2:
// 将 s1[i] 删除,则 s1 指针前进
System.out.println("delete '" + c1 + "'");
i--;
break;
case 3:
// 将 s1[i] 替换成 s2[j],则两个指针同时前进
System.out.println(
"replace '" + c1 + "'" + " with '" + c2 + "'");
i--; j--;
break;
}
}
// 如果 s1 还没有走完,则剩下的都是需要删除的
while (i > 0) {
System.out.print("s1[" + (i - 1) + "]:");
System.out.println("delete '" + s1.charAt(i - 1) + "'");
i--;
}
// 如果 s2 还没有走完,则剩下的都是需要插入 s1 的
while (j > 0) {
System.out.print("s1[0]:");
System.out.println("insert '" + s2.charAt(j - 1) + "'");
j--;
}
}
背包类型问题
0-1背包
给你一个可装载重量为 W 的背包和 N 个物品,每个物品有重量和价值两个属性。其中第 i 个物品的重量为 wt[i],价值为 val[i]。现在让你用这个背包装物品,每个物品只能用一次,在不超过被包容量的前提下,最多能装的价值是多少?

举个简单的例子,输入如下:
N = 3, W = 4
wt = [2, 1, 3]
val = [4, 2, 3]
算法返回 6,选择前两件物品装进背包,总重量 3 小于 W,可以获得最大价值 6。
题目就是这么简单,一个典型的动态规划问题。这个题目中的物品不可以分割,要么装进包里,要么不装,不能说切成两块装一半。这就是 0-1 背包这个名词的来历。
动态规划标准套路
第一步要明确两点,「状态」和「选择」。
先说状态,如何才能描述一个问题局面?只要给几个物品和一个背包的容量限制,就形成了一个背包问题呀。所以状态有两个,就是「背包的容量」和「可选择的物品」。
再说选择,也很容易想到啊,对于每件物品,你能选择什么?选择就是「装进背包」或者「不装进背包」嘛。
明白了状态和选择,动态规划问题基本上就解决了,对于自底向上的思考方式,代码的一般框架是这样:
for 状态1 in 状态1的所有取值:
for 状态2 in 状态2的所有取值:
for ...
dp[状态1][状态2][...] = 择优(选择1,选择2...)
第二步要明确 dp 数组的定义。
首先看看刚才找到的「状态」,有两个,也就是说我们需要一个二维 dp 数组。
dp[i][w] 的定义如下:对于前 i 个物品,当前背包的容量为 w,这种情况下可以装的最大价值是 dp[i][w]。
比如说,如果 dp[3][5] = 6,其含义为:对于给定的一系列物品中,若只对前 3 个物品进行选择,当背包容量为 5 时,最多可以装下的价值为 6。
根据这个定义,我们想求的最终答案就是 dp[N][W]。base case 就是 dp[0][..] = dp[..][0] = 0,因为没有物品或者背包没有空间的时候,能装的最大价值就是 0。
细化上面的框架:
int[][] dp[N+1][W+1]
dp[0][..] = 0
dp[..][0] = 0
for i in [1..N]:
for w in [1..W]:
dp[i][w] = max(
把物品 i 装进背包,
不把物品 i 装进背包
)
return dp[N][W]
第三步,根据「选择」,思考状态转移的逻辑。
简单说就是,上面伪码中「把物品 i 装进背包」和「不把物品 i 装进背包」怎么用代码体现出来呢?
这就要结合对 dp 数组的定义,看看这两种选择会对状态产生什么影响:
先重申一下刚才我们的 dp 数组的定义:
dp[i][w] 表示:对于前 i 个物品(从 1 开始计数),当前背包的容量为 w 时,这种情况下可以装下的最大价值是 dp[i][w]。
如果你没有把这第 i 个物品装入背包,那么很显然,最大价值 dp[i][w] 应该等于 dp[i-1][w],继承之前的结果。
如果你把这第 i 个物品装入了背包,那么 dp[i][w] 应该等于 val[i-1] + dp[i-1][w - wt[i-1]]。
首先,由于数组索引从 0 开始,而我们定义中的 i 是从 1 开始计数的,所以 val[i-1] 和 wt[i-1] 表示第 i 个物品的价值和重量。
你如果选择将第 i 个物品装进背包,那么第 i 个物品的价值 val[i-1] 肯定就到手了,接下来你就要在剩余容量 w - wt[i-1] 的限制下,在前 i - 1 个物品中挑选,求最大价值,即 dp[i-1][w - wt[i-1]]。
综上就是两种选择,我们都已经分析完毕,也就是写出来了状态转移方程,可以进一步细化代码:
for i in [1..N]:
for w in [1..W]:
dp[i][w] = max(
dp[i-1][w],
dp[i-1][w - wt[i-1]] + val[i-1]
)
return dp[N][W]
最后一步,把伪码翻译成代码,处理一些边界情况。
#include <cassert>
// 完全背包问题
// 输入:
// - W: 背包的最大容量
// - N: 物品的数量
// - wt: 物品的重量数组,wt[i-1]表示第i个物品的重量
// - val: 物品的价值数组,val[i-1]表示第i个物品的价值
// 输出:
// - 最大价值
int knapsack(int W, int N, int wt[], int val[]) {
assert(N == sizeof(wt)/sizeof(wt[0])); // 确保N和wt的长度匹配
int dp[N + 1][W + 1]; // base case 已初始化为0
for (int i = 1; i <= N; i++) {
for (int w = 1; w <= W; w++) {
if (w - wt[i - 1] < 0) {
// 这种情况下只能选择不装入背包
dp[i][w] = dp[i - 1][w];
} else {
// 装入或者不装入背包,择优
dp[i][w] = std::max(
dp[i - 1][w - wt[i-1]] + val[i-1],
dp[i - 1][w]
);
}
}
}
return dp[N][W];
}
子集背包
问题分析
题目
输入一个只包含正整数的非空数组 nums,请你写一个算法,判断这个数组是否可以被分割成两个子集,使得两个子集的元素和相等。
算法的函数签名如下:
// 输入一个集合,返回是否能够分割成和相等的两个子集
bool canPartition(vector<int>& nums);
比如说输入 nums = [1,5,11,5],算法返回 true,因为 nums 可以分割成 [1,5,5] 和 [11] 这两个子集。
如果说输入 nums = [1,3,2,5],算法返回 false,因为 nums 无论如何都不能分割成两个和相等的子集。
思路
首先回忆一下背包问题大致的描述是什么:
给你一个可装载重量为 W 的背包和 N 个物品,每个物品有重量和价值两个属性。其中第 i 个物品的重量为 wt[i],价值为 val[i],现在让你用这个背包装物品,最多能装的价值是多少?
那么对于这个问题,我们可以先对集合求和,得出 sum,把问题转化为背包问题:
给一个可装载重量为 sum / 2 的背包和 N 个物品,每个物品的重量为 nums[i]。现在让你装物品,是否存在一种装法,能够恰好将背包装满?
你看,这就是背包问题的模型,甚至比我们之前的经典背包问题还要简单一些,下面我们就直接转换成背包问题,开始套前文讲过的背包问题框架即可。
解法分析
第一步要明确两点,「状态」和「选择」。
这个前文 经典动态规划:背包问题 已经详细解释过了,状态就是「背包的容量」和「可选择的物品」,选择就是「装进背包」或者「不装进背包」。
第二步要明确 dp 数组的定义。
按照背包问题的套路,可以给出如下定义:
dp[i][j] = x 表示,对于前 i 个物品(i 从 1 开始计数),当前背包的容量为 j 时,若 x 为 true,则说明可以恰好将背包装满,若 x 为 false,则说明不能恰好将背包装满。
比如说,如果 dp[4][9] = true,其含义为:对于容量为 9 的背包,若只是在前 4 个物品中进行选择,可以有一种方法把背包恰好装满。
或者说对于本题,含义是对于给定的集合中,若只在前 4 个数字中进行选择,存在一个子集的和可以恰好凑出 9。
根据这个定义,我们想求的最终答案就是 dp[N][sum/2],base case 就是 dp[..][0] = true 和 dp[0][..] = false,因为背包没有空间的时候,就相当于装满了,而当没有物品可选择的时候,肯定没办法装满背包。
第三步,根据「选择」,思考状态转移的逻辑。
回想刚才的 dp 数组含义,可以根据「选择」对 dp[i][j] 得到以下状态转移:
如果不把 nums[i] 算入子集,或者说你不把这第 i 个物品装入背包,那么是否能够恰好装满背包,取决于上一个状态 dp[i-1][j],继承之前的结果。
如果把 nums[i] 算入子集,或者说你把这第 i 个物品装入了背包,那么是否能够恰好装满背包,取决于状态 dp[i-1][j-nums[i-1]]。
dp[i - 1][j-nums[i-1]] 也很好理解:你如果装了第 i 个物品,就要看背包的剩余重量 j - nums[i-1] 限制下是否能够被恰好装满。
换句话说,如果 j - nums[i-1] 的重量可以被恰好装满,那么只要把第 i 个物品装进去,也可恰好装满 j 的重量;否则的话,重量 j 肯定是装不满的。
最后一步,把伪码翻译成代码,处理一些边界情况。
class Solution {
public:
bool canPartition(vector<int>& nums) {
int sum = 0;
for (int num : nums) sum += num;
// 和为奇数时,不可能划分成两个和相等的集合
if (sum % 2 != 0) return false;
int n = nums.size();
sum = sum / 2;
vector<vector<bool>> dp(n + 1, vector<bool>(sum + 1, false));
// base case
for (int i = 0; i <= n; i++)
dp[i][0] = true;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= sum; j++) {
if (j - nums[i - 1] < 0) {
// 背包容量不足,不能装入第 i 个物品
dp[i][j] = dp[i - 1][j];
} else {
// 装入或不装入背包
dp[i][j] = dp[i - 1][j] || dp[i - 1][j - nums[i - 1]];
}
}
}
return dp[n][sum];
}
};
进一步优化
注意到 dp[i][j] 都是通过上一行 dp[i-1][..] 转移过来的,之前的数据都不会再使用了。
class Solution {
public:
bool canPartition(vector<int>& nums) {
int sum = 0;
for (int num : nums) sum += num;
// 和为奇数时,不可能划分成两个和相等的集合
if (sum % 2 != 0) return false;
int n = nums.size();
sum = sum / 2;
vector<bool> dp(sum + 1, false);
// base case
dp[0] = true;
for (int i = 0; i < n; i++) {
for (int j = sum; j >= 0; j--) {
if (j - nums[i] >= 0) {
dp[j] = dp[j] || dp[j - nums[i]];
}
}
}
return dp[sum];
}
};
其实这段代码和之前的解法思路完全相同,只在一行 dp 数组上操作,i 每进行一轮迭代,dp[j] 其实就相当于 dp[i-1][j],所以只需要一维数组就够用了。
唯一需要注意的是 j 应该从后往前反向遍历,因为每个物品(或者说数字)只能用一次,以免之前的结果影响其他的结果。
至此,子集切割的问题就完全解决了,时间复杂度 O(n\*sum),空间复杂度 O(sum)。
完全背包
题目
给定不同面额的硬币 coins 和一个总金额 amount,写一个函数来计算可以凑成总金额的硬币组合数。假设每一种面额的硬币有无限个。
我们要完成的函数的签名如下:
int change(int amount, vector<int>& coins);
比如说输入 amount = 5, coins = [1,2,5],算法应该返回 4,因为有如下 4 种方式可以凑出目标金额:
5=5
5=2+2+1
5=2+1+1+1
5=1+1+1+1+1
如果输入的 amount = 5, coins = [3],算法应该返回 0,因为用面额为 3 的硬币无法凑出总金额 5。
我们可以把这个问题转化为背包问题的描述形式:
有一个背包,最大容量为 amount,有一系列物品 coins,每个物品的重量为 coins[i],每个物品的数量无限。请问有多少种方法,能够把背包恰好装满?
这个问题和我们前面讲过的两个背包问题,有一个最大的区别就是,每个物品的数量是无限的,这也就是传说中的「完全背包问题」,没啥高大上的,无非就是状态转移方程有一点变化而已。
下面就以背包问题的描述形式,继续按照流程来分析。
解题思路
第一步要明确两点,「状态」和「选择」。
状态有两个,就是「背包的容量」和「可选择的物品」,选择就是「装进背包」或者「不装进背包」嘛,背包问题的套路都是这样。
明白了状态和选择,动态规划问题基本上就解决了,只要往这个框架套就完事儿了:
for 状态1 in 状态1的所有取值:
for 状态2 in 状态2的所有取值:
for ...
dp[状态1][状态2][...] = 计算(选择1,选择2...)
第二步要明确 dp 数组的定义。
首先看看刚才找到的「状态」,有两个,也就是说我们需要一个二维 dp 数组。
dp[i][j] 的定义如下:
若只使用前 i 个物品(可以重复使用),当背包容量为 j 时,有 dp[i][j] 种方法可以装满背包。
换句话说,翻译回我们题目的意思就是:
若只使用 coins 中的前 i 个(i 从 1 开始计数)硬币的面值,若想凑出金额 j,有 dp[i][j] 种凑法。
经过以上的定义,可以得到:
base case 为 dp[0][..] = 0, dp[..][0] = 1。i = 0 代表不使用任何硬币面值,这种情况下显然无法凑出任何金额;j = 0 代表需要凑出的目标金额为 0,那么什么都不做就是唯一的一种凑法。
我们最终想得到的答案就是 dp[N][amount],其中 N 为 coins 数组的大小。
大致的伪码思路如下:
int dp[N+1][amount+1]
dp[0][..] = 0
dp[..][0] = 1
for i in [1..N]:
for j in [1..amount]:
把物品 i 装进背包,
不把物品 i 装进背包
return dp[N][amount]
第三步,根据「选择」,思考状态转移的逻辑。
注意,我们这个问题的特殊点在于物品的数量是无限的,所以这里和之前写的 0-1 背包问题 文章有所不同。
如果你不把这第 i 个物品装入背包,也就是说你不使用 coins[i-1] 这个面值的硬币,那么凑出面额 j 的方法数 dp[i][j] 应该等于 dp[i-1][j],继承之前的结果。
如果你把这第 i 个物品装入了背包,也就是说你使用 coins[i-1] 这个面值的硬币,那么 dp[i][j] 应该等于 dp[i][j-coins[i-1]]。
dp[i][j-coins[i-1]] 也不难理解,如果你决定使用这个面值的硬币,那么就应该关注如何凑出金额 j - coins[i-1]。
比如说,你想用面值为 2 的硬币凑出金额 5,那么如果你知道了凑出金额 3 的方法,再加上一枚面额为 2 的硬币,不就可以凑出 5 了嘛。
综上就是两种选择,而我们想求的 dp[i][j] 是「共有多少种凑法」,所以 dp[i][j] 的值应该是以上两种选择的结果之和:
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= amount; j++) {
if (j - coins[i-1] >= 0)
dp[i][j] = dp[i - 1][j]
+ dp[i][j-coins[i-1]];
return dp[N][W]
最后一步,把伪码翻译成代码,处理一些边界情况。
int change(int amount, vector<int>& coins) {
int n = coins.size();
vector<vector<int>> dp(n + 1, vector<int>(amount + 1));
// base case
for (int i = 0; i <= n; i++)
dp[i][0] = 1;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= amount; j++)
if (j - coins[i-1] >= 0)
dp[i][j] = dp[i - 1][j]
+ dp[i][j - coins[i-1]];
else
dp[i][j] = dp[i - 1][j];
}
return dp[n][amount];
}
而且,我们通过观察可以发现,dp 数组的转移只和 dp[i][..] 和 dp[i-1][..] 有关,所以可以使用前文讲的 动态规划空间压缩技巧,进一步降低算法的空间复杂度:
int change(int amount, vector<int>& coins) {
int n = coins.size();
vector<int> dp(amount + 1);
dp[0] = 1; // base case
for (int i = 0; i < n; i++)
for (int j = 1; j <= amount; j++)
if (j - coins[i] >= 0)
dp[j] = dp[j] + dp[j-coins[i]];
return dp[amount];
}
这个解法和之前的思路完全相同,将二维 dp 数组压缩为一维,时间复杂度 O(N*amount),空间复杂度 O(amount)。
动态规划玩游戏
动态规划之最小路径和
题目
现在给你输入一个二维数组 grid,其中的元素都是非负整数,现在你站在左上角,只能向右或者向下移动,需要到达右下角。现在请你计算,经过的路径和最小是多少?
函数签名如下:
int minPathSum(vector<vector<int>>& grid);
比如题目举的例子,输入如下的 grid 数组:
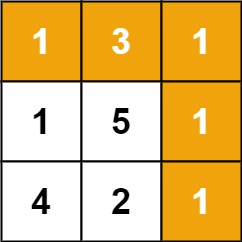
算法应该返回 7,最小路径和为 7,就是上图黄色的路径。
思路
一般来说,让你在二维矩阵中求最优化问题(最大值或者最小值),肯定需要递归 + 备忘录,也就是动态规划技巧。
就拿题目举的例子来说,我给图中的几个格子编个号方便描述:
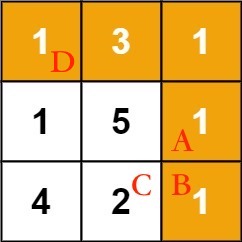
我们想计算从起点 D 到达 B 的最小路径和,那你说怎么才能到达 B 呢?
题目说了只能向右或者向下走,所以只有从 A 或者 C 走到 B。
那么算法怎么知道从 A 走到 B 才能使路径和最小,而不是从 C 走到 B 呢?
难道是因为位置 A 的元素大小是 1,位置 C 的元素是 2,1 小于 2,所以一定要从 A 走到 B 才能使路径和最小吗?
其实不是的,真正的原因是,从 D 走到 A 的最小路径和是 6,而从 D 走到 C 的最小路径和是 8,6 小于 8,所以一定要从 A 走到 B 才能使路径和最小。
换句话说,我们把「从 D 走到 B 的最小路径和」这个问题转化成了「从 D 走到 A 的最小路径和」和 「从 D 走到 C 的最小路径和」这两个问题。
理解了上面的分析,这不就是状态转移方程吗?所以这个问题肯定会用到动态规划技巧来解决。
比如我们定义如下一个 dp 函数:
int dp(int grid[][], int i, int j);
这个 dp 函数的定义如下:
从左上角位置 (0, 0) 走到位置 (i, j) 的最小路径和为 dp(grid, i, j)。
根据这个定义,我们想求的最小路径和就可以通过调用这个 dp 函数计算出来:
int minPathSum(vector<vector<int>>& grid) {
int m = grid.size();
int n = grid[0].size();
// 计算从左上角走到右下角的最小路径和
return dp(grid, m - 1, n - 1);
}
再根据刚才的分析,很容易发现,dp(grid, i, j) 的值取决于 dp(grid, i - 1, j) 和 dp(grid, i, j - 1) 返回的值。
我们可以直接写代码了:
int dp(vector<vector<int>>& grid, int i, int j) {
// base case
if (i == 0 && j == 0) {
return grid[0][0];
}
// 如果索引出界,返回一个很大的值,
// 保证在取 min 的时候不会被取到
if (i < 0 || j < 0) {
return INT_MAX;
}
// 左边和上面的最小路径和加上 grid[i][j]
// 就是到达 (i, j) 的最小路径和
return min(
dp(grid, i - 1, j),
dp(grid, i, j - 1)
) + grid[i][j];
}
上述代码逻辑已经完整了,接下来就分析一下,这个递归算法是否存在重叠子问题?是否需要用备忘录优化一下执行效率?
前文多次说过判断重叠子问题的技巧,首先抽象出上述代码的递归框架:
int dp(int i, int j) {
dp(i - 1, j); // #1
dp(i, j - 1); // #2
}
如果我想从 dp(i, j) 递归到 dp(i-1, j-1),有几种不同的递归调用路径?
可以是 dp(i, j) -> #1 -> #2 或者 dp(i, j) -> #2 -> #1,不止一种,说明 dp(i-1, j-1) 会被多次计算,所以一定存在重叠子问题。
那么我们可以使用备忘录技巧进行优化:
class Solution {
private:
//备忘录
vector<vector<int>> memo;
int dp(vector<vector<int>> &grid, int i, int j) {
//base case
if (i == 0 && j == 0) {
return grid[0][0];
}
if (i < 0 || j < 0) {
return INT_MAX;
}
//避免重复计算
if (memo[i][j] != -1) {
return memo[i][j];
}
//将计算结果记入备忘录
memo[i][j] = min(
dp(grid, i - 1, j),
dp(grid, i, j - 1)
) + grid[i][j];
return memo[i][j];
}
public:
int minPathSum(vector<vector<int>>& grid) {
int m = grid.size();
int n = grid[0].size();
//构造备忘录,初始值全部设为 -1
memo = vector<vector<int>>(m, vector<int>(n, -1));
return dp(grid, m - 1, n - 1);
}
};
至此,本题就算是解决了,时间复杂度和空间复杂度都是 O(MN),标准的自顶向下动态规划解法。
能不能用自底向上的迭代解法来做这道题呢?完全可以的。
首先,类似刚才的 dp 函数,我们需要一个二维 dp 数组,定义如下:
从左上角位置 (0, 0) 走到位置 (i, j) 的最小路径和为 dp[i][j]。
状态转移方程当然不会变的,dp[i][j] 依然取决于 dp[i-1][j] 和 dp[i][j-1],直接看代码吧:
class Solution {
public:
int minPathSum(vector<vector<int>>& grid) {
int m = grid.size();
int n = grid[0].size();
vector<vector<int>> dp(m, vector<int>(n, 0));
// **** base case ****
dp[0][0] = grid[0][0];
for (int i = 1; i < m; i++)
dp[i][0] = dp[i - 1][0] + grid[i][0];
for (int j = 1; j < n; j++)
dp[0][j] = dp[0][j - 1] + grid[0][j];
// *******************
// 状态转移
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
dp[i][j] = min(
dp[i - 1][j],
dp[i][j - 1]
) + grid[i][j];
}
}
return dp[m - 1][n - 1];
}
};
这个解法的 base case 看起来和递归解法略有不同,但实际上是一样的。
因为状态转移为下面这段代码:
dp[i][j] = Math.min(
dp[i - 1][j],
dp[i][j - 1]
) + grid[i][j];
那如果 i 或者 j 等于 0 的时候,就会出现索引越界的错误。
所以我们需要提前计算出 dp[0][..] 和 dp[..][0],然后让 i 和 j 的值从 1 开始迭代。
dp[0][..] 和 dp[..][0] 的值怎么算呢?其实很简单,第一行和第一列的路径和只有下面这一种情况嘛:

那么按照 dp 数组的定义,dp[i][0] = sum(grid[0..i][0]), dp[0][j] = sum(grid[0][0..j]),也就是如下代码:
// **** base case ****
dp[0][0] = grid[0][0];
for (int i = 1; i < m; i++)
dp[i][0] = dp[i - 1][0] + grid[i][0];
for (int j = 1; j < n; j++)
dp[0][j] = dp[0][j - 1] + grid[0][j];
// *******************
如何优化空间复杂度
也可以用滚动数组的思路,不过这里的滚动数组不是数字,而是真的数组,利用两个vector记录第一行和第一列的数据,然后更新即可。
通关《魔塔》
「魔塔」是一款经典的地牢类游戏,碰怪物要掉血,吃血瓶能加血,你要收集钥匙,一层一层上楼,最后救出美丽的公主。
现在手机上仍然可以玩这个游戏:
题目
输入一个存储着整数的二维数组 grid,如果 grid[i][j] > 0,说明这个格子装着血瓶,经过它可以增加对应的生命值;如果 grid[i][j] == 0,则这是一个空格子,经过它不会发生任何事情;如果 grid[i][j] < 0,说明这个格子有怪物,经过它会损失对应的生命值。
现在你是一名骑士,将会出现在最左上角,公主被困在最右下角,你只能向右和向下移动,请问你初始至少需要多少生命值才能成功救出公主?
换句话说,就是问你至少需要多少初始生命值,能够让骑士从最左上角移动到最右下角,且任何时候生命值都要大于 0。
函数签名如下:
int calculateMinimumHP(vector<vector<int>>& grid);
思路
比如题目给我们举的例子,输入如下一个二维数组 grid,用 K 表示骑士,用 P 表示公主:

算法应该返回 7,也就是说骑士的初始生命值至少为 7 时才能成功救出公主,行进路线如图中的箭头所示。
上文 最小路径和 写过类似的问题,问你从左上角到右下角的最小路径和是多少。
我们做算法题一定要尝试举一反三,感觉今天这道题和最小路径和有点关系对吧?
想要最小化骑士的初始生命值,是不是意味着要最大化骑士行进路线上的血瓶?是不是相当于求「最大路径和」?是不是可以直接套用计算「最小路径和」的思路?
但是稍加思考,发现这个推论并不成立,吃到最多的血瓶,并不一定就能获得最小的初始生命值。
比如如下这种情况,如果想要吃到最多的血瓶获得「最大路径和」,应该按照下图箭头所示的路径,初始生命值需要 11:
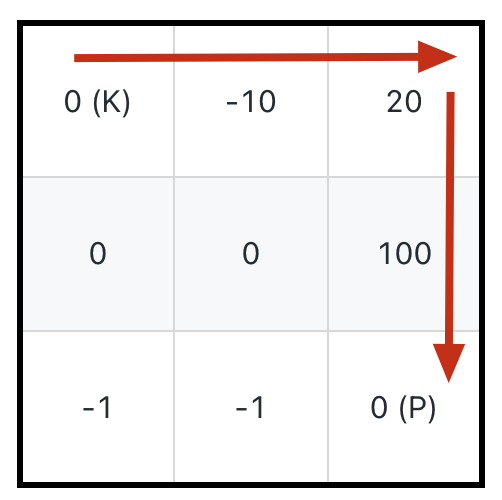
但也很容易看到,正确的答案应该是下图箭头所示的路径,初始生命值只需要 1:
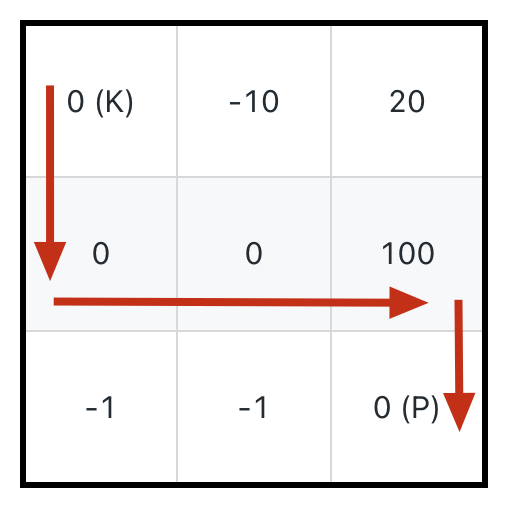
所以,关键不在于吃最多的血瓶,而是在于如何损失最少的生命值。
这类求最值的问题,肯定要借助动态规划技巧,要合理设计 dp 数组/函数的定义。类比前文 最小路径和问题,dp 函数签名肯定长这样:
int dp(int** grid, int i, int j);
但是这道题对 dp 函数的定义比较有意思,按照常理,这个 dp 函数的定义应该是:
从左上角(grid[0][0])走到 grid[i][j] 至少需要 dp(grid, i, j) 的生命值。
这样定义的话,base case 就是 i, j 都等于 0 的时候,我们可以这样写代码:
int dp(vector<vector<int>>& grid, int i, int j) {
// base case
if (i == 0 && j == 0) {
// 保证骑士落地不死就行了
return grid[i][j] > 0 ? 1 : -grid[i][j] + 1;
}
...
}
int calculateMinimumHP(vector<vector<int>>& grid) {
int m = grid.size();
int n = grid[0].size();
// 我们想计算左上角到右下角所需的最小生命值
return dp(grid, m - 1, n - 1);
}
接下来我们需要找状态转移了,还记得如何找状态转移方程吗?我们这样定义 dp 函数能否正确进行状态转移呢?
我们希望 dp(i, j) 能够通过 dp(i-1, j) 和 dp(i, j-1) 推导出来,这样就能不断逼近 base case,也就能够正确进行状态转移。
具体来说,「到达 A 的最小生命值」应该能够由「到达 B 的最小生命值」和「到达 C 的最小生命值」推导出来:
但问题是,能推出来么?实际上是不能的。
因为按照 dp 函数的定义,你只知道「能够从左上角到达 B 的最小生命值」,但并不知道「到达 B 时的生命值」。
「到达 B 时的生命值」是进行状态转移的必要参考,举个例子你就明白了,假设下图这种情况:

这种情况下,骑士救公主的最优路线是什么?
显然是按照图中蓝色的线走到 B,最后走到 A 对吧,这样初始血量只需要 1 就可以;如果走黄色箭头这条路,先走到 C 然后走到 A,初始血量至少需要 6。
为什么会这样呢?骑士走到 B 和 C 的最少初始血量都是 1,为什么最后是从 B 走到 A,而不是从 C 走到 A 呢?
因为骑士走到 B 的时候生命值为 11,而走到 C 的时候生命值依然是 1。
如果骑士执意要通过 C 走到 A,那么初始血量必须加到 6 点才行;而如果通过 B 走到 A,初始血量为 1 就够了,因为路上吃到血瓶了,生命值足够抗 A 上面怪物的伤害。
这下应该说的很清楚了,再回顾我们对 dp 函数的定义,上图的情况,算法只知道 dp(1, 2) = dp(2, 1) = 1,都是一样的,怎么做出正确的决策,计算出 dp(2, 2) 呢?
所以说,我们之前对 dp 数组的定义是错误的,信息量不足,算法无法做出正确的状态转移。
正确的做法需要反向思考,依然是如下的 dp 函数:
int dp(int** grid, int i, int j);
但是我们要修改 dp 函数的定义:
从 grid[i][j] 到达终点(右下角)所需的最少生命值是 dp(grid, i, j)。
那么可以这样写代码:
int calculateMinimumHP(vector<vector<int>>& grid) {
// 我们想计算左上角到右下角所需的最小生命值
return dp(grid, 0, 0);
}
int dp(vector<vector<int>>& grid, int i, int j) {
int m = grid.size();
int n = grid[0].size();
// base case
if (i == m - 1 && j == n - 1) {
return grid[i][j] >= 0 ? 1 : -grid[i][j] + 1;
}
...
}
根据新的 dp 函数定义和 base case,我们想求 dp(0, 0),那就应该试图通过 dp(i, j+1) 和 dp(i+1, j) 推导出 dp(i, j),这样才能不断逼近 base case,正确进行状态转移。
具体来说,「从 A 到达右下角的最少生命值」应该由「从 B 到达右下角的最少生命值」和「从 C 到达右下角的最少生命值」推导出来:
能不能推导出来呢?这次是可以的,假设 dp(0, 1) = 5, dp(1, 0) = 4,那么可以肯定要从 A 走向 C,因为 4 小于 5 嘛。
那么怎么推出 dp(0, 0) 是多少呢?
假设 A 的值为 1,既然知道下一步要往 C 走,且 dp(1, 0) = 4 意味着走到 grid[1][0] 的时候至少要有 4 点生命值,那么就可以确定骑士出现在 A 点时需要 4 - 1 = 3 点初始生命值,对吧。
那如果 A 的值为 10,落地就能捡到一个大血瓶,超出了后续需求,4 - 10 = -6 意味着骑士的初始生命值为负数,这显然不可以,骑士的生命值小于 1 就挂了,所以这种情况下骑士的初始生命值应该是 1。
综上,状态转移方程已经推出来了:
int res = min(
dp(i + 1, j),
dp(i, j + 1)
) - grid[i][j];
dp(i, j) = res <= 0 ? 1 : res;
根据这个核心逻辑,加一个备忘录消除重叠子问题,就可以直接写出最终的代码了:
class Solution {
public:
// 主函数
int calculateMinimumHP(vector<vector<int>>& grid) {
int m = grid.size();
int n = grid[0].size();
// 备忘录中都初始化为 -1
memo = vector<vector<int>>(m, vector<int>(n, -1));
return dp(grid, 0, 0);
}
private:
// 备忘录,消除重叠子问题
vector<vector<int>> memo;
// 定义:从 (i, j) 到达右下角,需要的初始血量至少是多少
int dp(vector<vector<int>>& grid, int i, int j) {
int m = grid.size();
int n = grid[0].size();
// base case
if (i == m - 1 && j == n - 1) {
return grid[i][j] >= 0 ? 1 : -grid[i][j] + 1;
}
if (i == m || j == n) {
return INT_MAX;
}
// 避免重复计算
if (memo[i][j] != -1) {
return memo[i][j];
}
// 状态转移逻辑
int res = min(
dp(grid, i, j + 1),
dp(grid, i + 1, j)
) - grid[i][j];
// 骑士的生命值至少为 1
memo[i][j] = res <= 0 ? 1 : res;
return memo[i][j];
}
};
通关《辐射4》
封面图是一款叫做《辐射4》的游戏中的一个任务剧情画面:

这个可以转动的圆盘类似是一个密码机关,中间偏上的位置有个红色的指针看到没,你只要转动圆盘可以让指针指向不同的字母,然后再按下中间的按钮就可以输入指针指向的字母。
只要转动圆环,让指针依次指向 R、A、I、L、R、O、A、D 并依次按下按钮,就可以触发机关,打开旁边的门。
至于密码为什么是这几个字母,在游戏中的剧情有暗示。
那么这个游戏场景和动态规划有什么关系呢?
我们来没事儿找事儿地想一想,拨动圆盘输入这些字母还挺麻烦的,按照什么顺序才能使得拨动圆盘所需的操作次数最少呢?
拨动圆盘的不同方法所需的操作次数肯定是不同的。
比如说想把一个字母对准到指针上,你可以顺时针转圆盘,也可以逆时针转圆盘;而且某些字母可能不止出现一次,比如上图中大写字母 O 就在圆盘的不同位置出现了三次,到时候应该拨哪个 O 才能使得整体的操作次数最少呢?
遇到求最值的问题,基本都是由动态规划算法来解决,因为动态规划本身就是运筹优化算法的一种嘛。
题目
给你输入一个字符串 ring 代表圆盘上的字符(指针位置在 12 点钟方向,初始指向 ring[0]),再输入一个字符串 key 代表你需要拨动圆盘输入的字符串,你的算法需要返回输入这个 key 至少进行多少次操作(拨动一格圆盘和按下圆盘中间的按钮都算是一次操作)。
函数签名如下:
int findRotateSteps(string ring, string key);
比如题目举的例子,输入 ring = "godding", key = "gd",对应的圆盘如下(大写只是为了清晰,实际上输入的字符串都是小写字母):
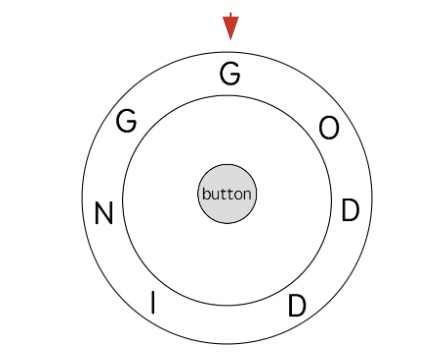
我们需要输入 key = "gd",算法返回 4。
因为现在指针指的字母就是字母 "g",所以可以直接按下中间的按钮,然后再将圆盘逆时针拨动两格,让指针指向字母 "d",然后再按一次中间的按钮。
上述过程,按了两次按钮,拨了两格转盘,总共操作了 4 次,是最少的操作次数,所以算法应该返回 4。
思路
我们这里可以首先给题目做一个等价,转动圆盘是不是就等于拨动指针?
原题可以转化为:圆盘固定,我们可以拨动指针;现在需要我们拨动指针并按下按钮,以最少的操作次数输入 key 对应的字符串。
那么,这个问题如何使用动态规划的技巧解决呢?或者说,这道题的「状态」和「选择」是什么呢?
「状态」就是「当前需要输入的字符」和「当前圆盘指针的位置」。
再具体点,「状态」就是 i 和 j 两个变量。我们可以用 i 表示当前圆盘上指针指向的字符(也就是 ring[i]);用 j 表示需要输入的字符(也就是 key[j])。
这样我们可以写这样一个 dp 函数:
int dp(string ring, int i, string key, int j);
这个 dp 函数的定义如下:
当圆盘指针指向 ring[i] 时,输入字符串 key[j..] 至少需要 dp(ring, i, key, j) 次操作。
根据这个定义,题目其实就是想计算 dp(ring, 0, key, 0) 的值,而且我们可以把 dp 函数的 base case 写出来:
int dp(string ring, int i, string key, int j) {
// base case,完成输入
if (j == key.length()) return 0;
// ...
}
接下来,思考一下如何根据状态做选择,如何进行状态转移?
「选择」就是「如何拨动指针得到待输入的字符」。
再具体点就是,对于现在想输入的字符 key[j],我们可以如何拨动圆盘,得到这个字符?
比如说输入 ring = "gdonidg",现在圆盘的状态如下图:
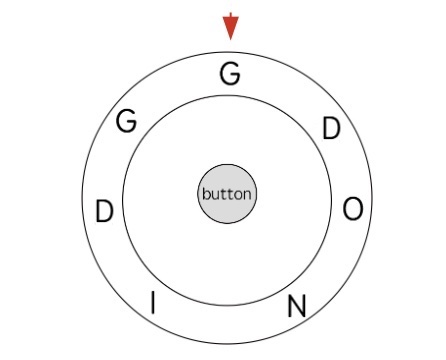
假设我想输入的字符 key[j] = "d",圆盘中有两个字母 "d",而且我可以顺时针也可以逆时针拨动指针,所以总共有四种「选择」输入字符 "d",我们需要选择操作次数最少的那个拨法。
大致的代码逻辑如下:
int dp(string ring, int i, string key, int j) {
// base case 完成输入
if (j == key.length()) return 0;
// 做选择
int res = INT_MAX;
for (int k : {index of character key[j] in ring}) {
res = min(
cost of clockwise rotation from i to k,
cost of counterclockwise rotation from i to k
);
}
return res;
}
至于到底是顺时针还是逆时针,其实非常好判断,怎么近就怎么来;但是对于圆盘中的两个字符 "d",还能是怎么近怎么来吗?
不能,因为这和 key[i] 之后需要输入的字符有关,还是上面的例子:
如果输入的是 key = "di",那么即便右边的 "d" 离得近,也应该去左边的 "d",因为左边的 "d" 旁边就是 "i",「整体」的操作数最少。
那么,应该如何判断呢?其实就是穷举,递归调用 dp 函数,把两种选择的「整体」代价算出来,然后再做比较就行了。
讲到这就差不多了,直接看代码吧:
class Solution {
// 字符 -> 索引列表
unordered_map<char, vector<int>> charToIndex;
// 备忘录
vector<vector<int>> memo;
// 主函数
public:
int findRotateSteps(string ring, string key) {
int m = ring.size();
int n = key.size();
// 备忘录全部初始化为 0
memo = vector<vector<int>>(m, vector<int>(n, 0));
// 记录圆环上字符到索引的映射
for (int i = 0; i < ring.size(); i++) {
char c = ring[i];
if (!charToIndex.count(c)) {
charToIndex[c] = vector<int>();
}
charToIndex[c].push_back(i);
}
// 圆盘指针最初指向 12 点钟方向,
// 从第一个字符开始输入 key
return dp(ring, 0, key, 0);
}
// 计算圆盘指针在 ring[i],输入 key[j..] 的最少操作数
private:
int dp(const string& ring, int i, const string& key, int j) {
// base case 完成输入
if (j == key.size()) return 0;
// 查找备忘录,避免重叠子问题
if (memo[i][j] != 0) return memo[i][j];
int n = ring.size();
// 做选择
int res = INT_MAX;
// ring 上可能有多个字符 key[j]
for (int k : charToIndex[key[j]]) {
// 拨动指针的次数
int delta = abs(k - i);
// 选择顺时针还是逆时针
delta = min(delta, n - delta);
// 将指针拨到 ring[k],继续输入 key[j+1..]
int subProblem = dp(ring, k, key, j + 1);
// 选择「整体」操作次数最少的
// 加一是因为按动按钮也是一次操作
res = min(res, 1 + delta + subProblem);
}
// 将结果存入备忘录
memo[i][j] = res;
return res;
}
};
加权最短路径
题目
现在有 n 个城市,分别用 0, 1…, n - 1 这些序号表示,城市之间的航线用三元组 [from, to, price] 来表示,比如说三元组 [0,1,100] 就表示,从城市 0 到城市 1 之间的机票价格是 100 元。
题目会给你输入若干参数:正整数 n 代表城市个数,数组 flights 装着若干三元组代表城市间的航线及价格,城市编号 src 代表你所在的城市,城市编号 dst 代表你要去的目标城市,整数 K 代表你最多经过的中转站个数。
函数签名如下:
int findCheapestPrice(int n, vector<vector<int>>& flights, int src, int dst, int K);
请你的算法计算,在 K 次中转之内,从 src 到 dst 所需的最小花费是多少钱,如果无法到达,则返回 -1。
比方说题目给的例子:
n = 3, flights = [[0,1,100],[1,2,100],[0,2,500]], src = 0, dst = 2, K = 1
航线就是如下这张图所示,有向边代表航向的方向,边上的数字代表航线的机票价格:

出发点是 0,到达点是 2,允许的最大中转次数 K 为 1,所以最小的开销就是图中红色的两条边,从 0 出发,经过中转城市 1 到达目标城市 2,所以算法的返回值应该是 200。
注意这个中转次数的上限 K 是比较棘手的,如果上述题目将 K 改为 0,也就是不允许中转,那么我们的算法只能返回 500 了,也就是直接从 0 飞到 2。
思路
很明显,这题就是个加权有向图中求最短路径的问题。
说白了,就是给你一幅加权有向图,让你求 src 到 dst 权重最小的一条路径,同时要满足,这条路径最多不能超过 K + 1 条边(经过 K 个节点相当于经过 K + 1 条边)。
我们来分析下求最短路径相关的算法。
BFS算法思路
我们前文 BFS 算法框架详解 中说到,求最短路径,肯定可以用 BFS 算法来解决。
因为 BFS 算法相当于从起始点开始,一步一步向外扩散,那当然是离起点越近的节点越先被遍历到,如果 BFS 遍历的过程中遇到终点,那么走的肯定是最短路径。
不过呢,我们在 BFS 算法框架详解 用的是普通的队列 Queue 来遍历多叉树,而对于加权图的最短路径来说,普通的队列不管用了,得用优先级队列 PriorityQueue。
为什么呢?也好理解,在多叉树(或者扩展到无权图)的遍历中,与其说边没有权重,不如说每条边的权重都是 1,起点与终点之间的路径权重就是它们之间「边」的条数。
这样,按照 BFS 算法一步步向四周扩散的逻辑,先遍历到的节点和起点之间的「边」更少,累计的权重当然少。
换言之,先进入 Queue 的节点就是离起点近的,路径权重小的节点。
但对于加权图,路径中边的条数和路径的权重并不是正相关的关系了,有的路径可能边的条数很少,但每条边的权重都很大,那显然这条路径权重也会很大,很难成为最短路径。
比如题目给的这个例子:
你是可以一步从 0 走到 2,但路径权重不见得是最小的。
所以,对于加权图的场景,我们需要优先级队列「自动排序」的特性,将路径权重较小的节点排在队列前面,以此为基础施展 BFS 算法,也就变成了 Dijkstra 算法。
class Solution {
public:
struct State {
// 图节点的 id
int id;
// 从 src 节点到当前节点的花费
int costFromSrc;
// 从 src 节点到当前节点经过的节点个数
int nodeNumFromSrc;
State(int id, int costFromSrc, int nodeNumFromSrc) {
this->id = id;
this->costFromSrc = costFromSrc;
this->nodeNumFromSrc = nodeNumFromSrc;
}
};
// 自定义比较器,以实现优先队列中costFromSrc较小的元素优先
class CompareState {
public:
bool operator()(State const& s1, State const& s2) {
return s1.costFromSrc > s2.costFromSrc;
}
};
int findCheapestPrice(int n, vector<vector<int>>& flights, int src, int dst, int K) {
vector<vector<int*>> graph(n);
for (vector<int> edge : flights) {
int from = edge[0];
int to = edge[1];
int price = edge[2];
int* arr = new int[2]{to, price};
graph[from].push_back(arr);
}
// 启动 dijkstra 算法
// 计算以 src 为起点在 k 次中转到达 dst 的最短路径
K++;
return dijkstra(graph, src, K, dst);
}
int dijkstra(vector<vector<int*>>& graph, int src, int k, int dst) {
// 定义:从起点 src 到达节点 i 的最短路径权重为 distTo[i]
vector<int> distTo(graph.size(), INT_MAX);
// 定义:从起点 src 到达节点 i 的最小权重路径至少要经过 nodeNumTo[i] 个节点
vector<int> nodeNumTo(graph.size(), INT_MAX);
// base case
distTo[src] = 0;
nodeNumTo[src] = 0;
// 优先级队列,costFromSrc 较小的排在前面
priority_queue<State, vector<State>, CompareState> pq;
// 从起点 src 开始进行 BFS
pq.push(State(src, 0, 0));
while (!pq.empty()) {
State curState = pq.top();
pq.pop();
int curNodeID = curState.id;
int costFromSrc = curState.costFromSrc;
int curNodeNumFromSrc = curState.nodeNumFromSrc;
if (curNodeID == dst) {
// 找到最短路径
return costFromSrc;
}
if (curNodeNumFromSrc == k) {
// 中转次数耗尽
continue;
}
// 将当前节点相邻节点装入队列
for (int* neighbor : graph[curNodeID]) {
int nextNodeID = neighbor[0];
int costToNextNode = costFromSrc + neighbor[1];
// 中转次数消耗 1
int nextNodeNumFromSrc = curNodeNumFromSrc + 1;
// 更新 dp table
if (distTo[nextNodeID] > costToNextNode) {
distTo[nextNodeID] = costToNextNode;
nodeNumTo[nextNodeID] = nextNodeNumFromSrc;
}
// 剪枝,如果中转次数更多,花费还更大,那必然不会是最短路径
if (costToNextNode > distTo[nextNodeID]
&& nextNodeNumFromSrc > nodeNumTo[nextNodeID]) {
continue;
}
pq.push(State(nextNodeID, costToNextNode, nextNodeNumFromSrc));
}
}
return -1;
}
};
动态规划思路
加权最短路径问题,再加个 K 的限制也无妨,不也是个求最值的问题嘛,动态规划统统拿下。
我们先不管 K 的限制,单就「加权最短路径」这个问题来看看,它怎么就是个动态规划问题了呢?
比方说,现在我想计算 src 到 dst 的最短路径:

最小权重是多少?我不知道。
但我可以把问题进行分解:
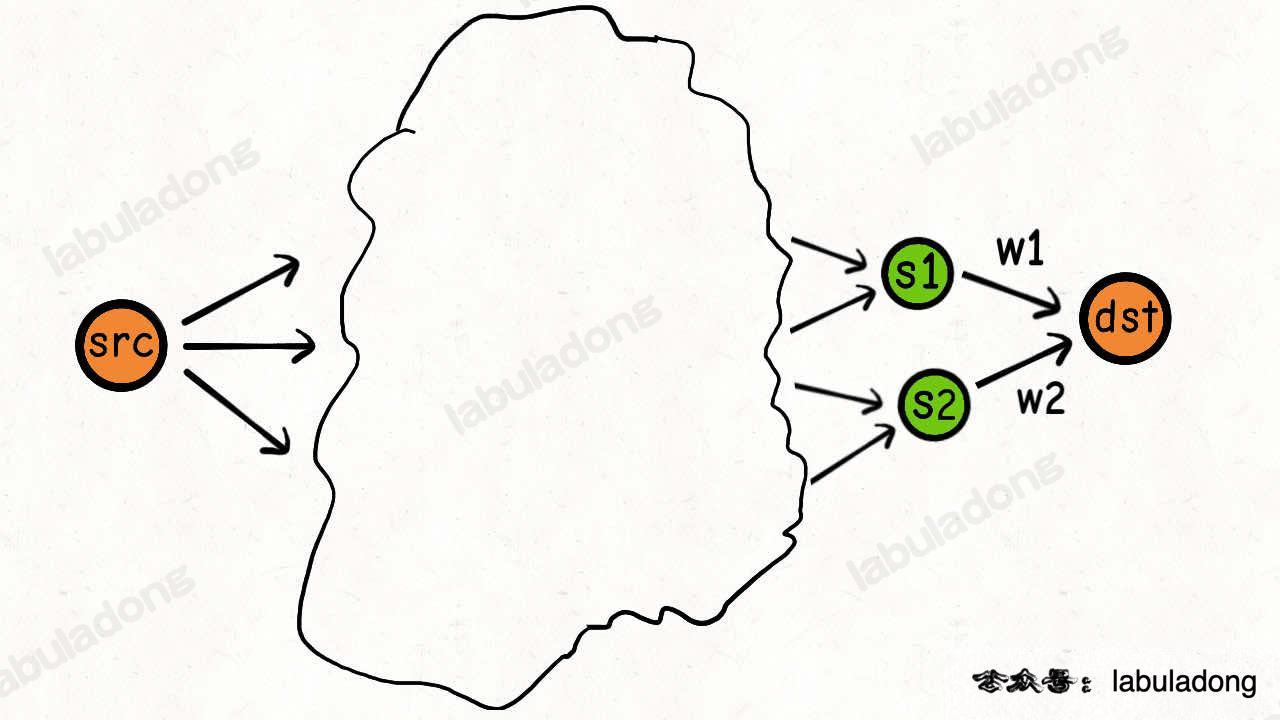
s1, s2 是指向 dst 的相邻节点,它们之间的权重我是知道的,分别是 w1, w2。
只要我知道了从 src 到 s1, s2 的最短路径,我不就知道 src 到 dst 的最短路径了吗!
minPath(src, dst) = min(
minPath(src, s1) + w1,
minPath(src, s2) + w2
)
这其实就是递归关系了,就是这么简单。
不过别忘了,题目对我们的最短路径还有个「路径上不能超过 K + 1 条边」的限制。
那么我们不妨定义这样一个 dp 函数:
int dp(int s, int k);
函数的定义如下:
从起点 src 出发,k 步之内(一步就是一条边)到达节点 s 的最小路径权重为 dp(s, k)。
那么,dp 函数的 base case 就显而易见了:
// 定义:从 src 出发,k 步之内到达 s 的最小成本
int dp(int s, int k) {
// 从 src 到 src,一步都不用走
if (s == src) {
return 0;
}
// 如果步数用尽,就无解了
if (k == 0) {
return -1;
}
// ...
}
题目想求的最小机票开销就可以用 dp(dst, K+1) 来表示:
添加了一个 K 条边的限制,状态转移方程怎么写呢?其实和刚才是一样的:
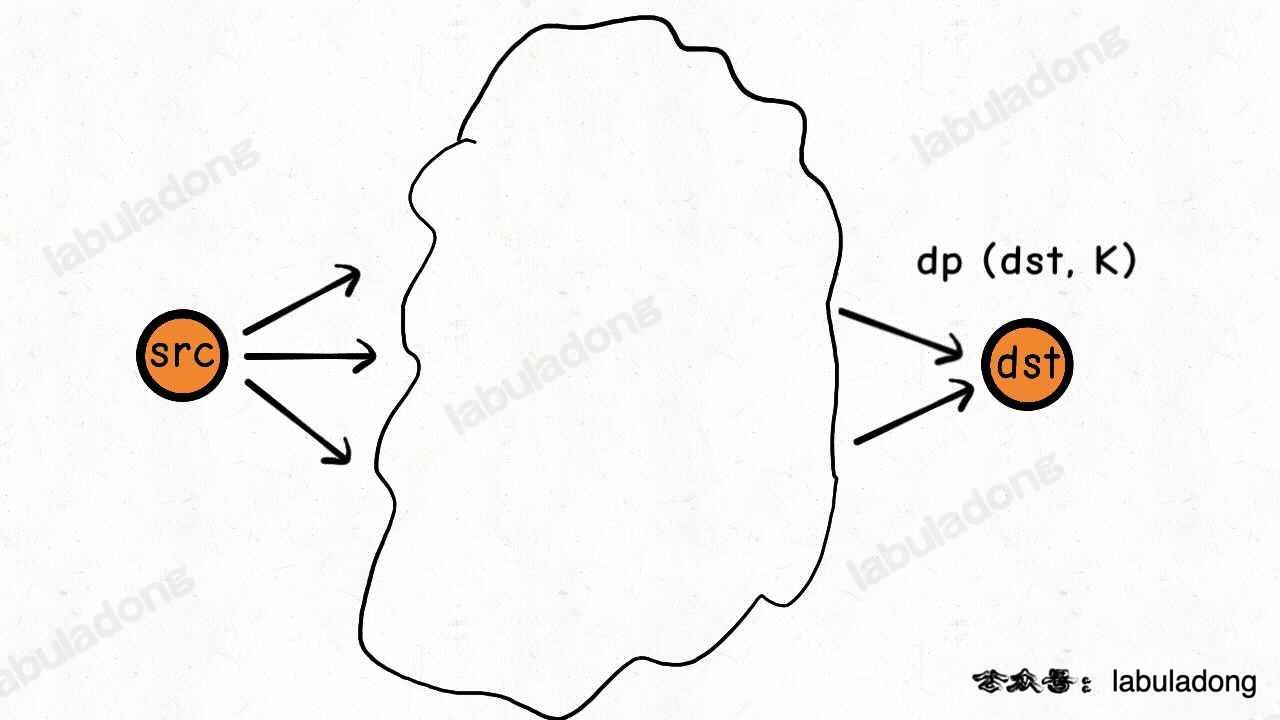
K 步之内从 src 到 dst 的最小路径权重是多少?我不知道。
但我可以把问题分解:

s1, s2 是指向 dst 的相邻节点,我只要知道 K - 1 步之内从 src 到达 s1, s2,那我就可以在 K 步之内从 src 到达 dst。
也就是如下关系式:
dp(dst, k) = min(
dp(s1, k - 1) + w1,
dp(s2, k - 1) + w2
)
这就是新的状态转移方程,如果你能看懂这个算式,就已经可以解决这道题了。
代码实现
根据上述思路,我怎么知道 s1, s2 是指向 dst 的相邻节点,他们之间的权重是 w1, w2?
我希望给一个节点,就能知道有谁指向这个节点,还知道它们之间的权重,对吧。
专业点说,得用一个数据结构记录每个节点的「入度」indegree,即存储所有指向该节点的相邻节点,以及它们之间边的权重。
具体看代码吧,我们用一个哈希表 indegree 存储入度,然后实现 dp 函数:
class Solution {
public:
// 哈希表记录每个点的入度,键是节点编号,值是指向该节点的相邻节点以及之间的权重
// to -> [from, price]
unordered_map<int, vector<pair<int, int>>> indegree;
int src, dst;
int findCheapestPrice(int n, vector<vector<int>>& flights, int src, int dst, int K) {
// 将中转站个数转化成边的条数
K++;
this->src = src;
this->dst = dst;
for(const auto& f : flights) {
int from = f[0];
int to = f[1];
int price = f[2];
// 记录谁指向该节点,以及之间的权重
indegree[to].push_back(make_pair(from, price));
}
return dp(dst, K);
}
// 定义:从 src 出发,k 步之内到达 s 的最短路径权重
int dp(int s, int k) {
// base case
if (s == src) {
return 0;
}
if (k == 0) {
return -1;
}
// 初始化为最大值,方便等会取最小值
int res = INT_MAX;
if (indegree.count(s)) {
// 当 s 有入度节点时,分解为子问题
for(const auto& v : indegree[s]) {
int from = v.first;
int price = v.second;
// 从 src 到达相邻的入度节点所需的最短路径权重
int subProblem = dp(from, k - 1);
// 跳过无解的情况
if (subProblem != -1) {
res = min(res, subProblem + price);
}
}
}
// 如果还是初始值,说明此节点不可达
return res == INT_MAX ? -1 : res;
}
};
有之前的铺垫,这段解法逻辑应该是很清晰的。当然,对于动态规划问题,肯定要消除重叠子问题。
为什么有重叠子问题?很简单,如果某个节点同时指向两个其他节点,那么这两个节点就有相同的一个入度节点,就会产生重复的递归计算。
怎么消除重叠子问题?找问题的「状态」。
状态是什么?在问题分解(状态转移)的过程中变化的,就是状态。
谁在变化?显然就是 dp 函数的参数 s 和 k,每次递归调用,目标点 s 和步数约束 k 在变化。
所以,本题的状态有两个,应该算是二维动态规划,我们可以用一个 memo 二维数组或者哈希表作为备忘录,减少重复计算。
我们选用二维数组做备忘录吧,注意 K 是从 1 开始算的,所以备忘录初始大小要再加一:
class Solution {
int src, dst;
unordered_map<int, vector<vector<int>>> indegree;
// 备忘录
vector<vector<int>> memo;
public:
int findCheapestPrice(int n, vector<vector<int>>& flights, int src, int dst, int K) {
K++;
this->src = src;
this->dst = dst;
// 初始化备忘录,全部填一个特殊值
memo = vector<vector<int>>(n, vector<int>(K + 1, -888));
// 初始化 indegree 的代码不变
// ...
return dp(dst, K);
}
// 定义:从 src 出发,k 步之内到达 s 的最小成本
int dp(int s, int k) {
// base case
if (s == src) {
return 0;
}
if (k == 0) {
return -1;
}
// 查备忘录,防止冗余计算
if (memo[s][k] != -888) {
return memo[s][k];
}
// 状态转移代码不变
// ...
// 存入备忘录
memo[s][k] = res == INT_MAX ? -1 : res;
return memo[s][k];
}
};
博弈问题
有趣的「石头游戏」,通过题目的限制条件,这个游戏是先手必胜的。但是智力题终究是智力题,真正的算法问题肯定不会是投机取巧能搞定的。所以,本文就借石头游戏来讲讲「假设两个人都足够聪明,最后谁会获胜」这一类问题该如何用动态规划算法解决。
博弈类问题的套路都差不多,其核心思路是在二维 dp 的基础上使用元组分别存储两个人的博弈结果。
石头游戏
你和你的朋友面前有一排石头堆,用一个数组 piles 表示,piles[i] 表示第 i 堆石子有多少个。你们轮流拿石头,一次拿一堆,但是只能拿走最左边或者最右边的石头堆。所有石头被拿完后,谁拥有的石头多,谁获胜。
石头的堆数可以是任意正整数,石头的总数也可以是任意正整数,这样就能打破先手必胜的局面了。比如有三堆石头 piles = [1, 100, 3],先手不管拿 1 还是 3,能够决定胜负的 100 都会被后手拿走,后手会获胜。
假设两人都很聪明,请你写一个 stoneGame 函数,返回先手和后手的最后得分(石头总数)之差。比如上面那个例子,先手能获得 4 分,后手会获得 100 分,你的算法应该返回 -96:
int stoneGame(int[] nums);
这个 stoneGame 函数怎么写呢?博弈问题的难点在于,两个人要轮流进行选择,而且都贼精明,应该如何编程表示这个过程呢?其实不难,首先明确 dp 数组的含义,然后只要找到「状态」和「选择」,一切就水到渠成了。
定义dp数组的含义
介绍 dp 数组的含义之前,先看一下 dp 数组最终的样子:
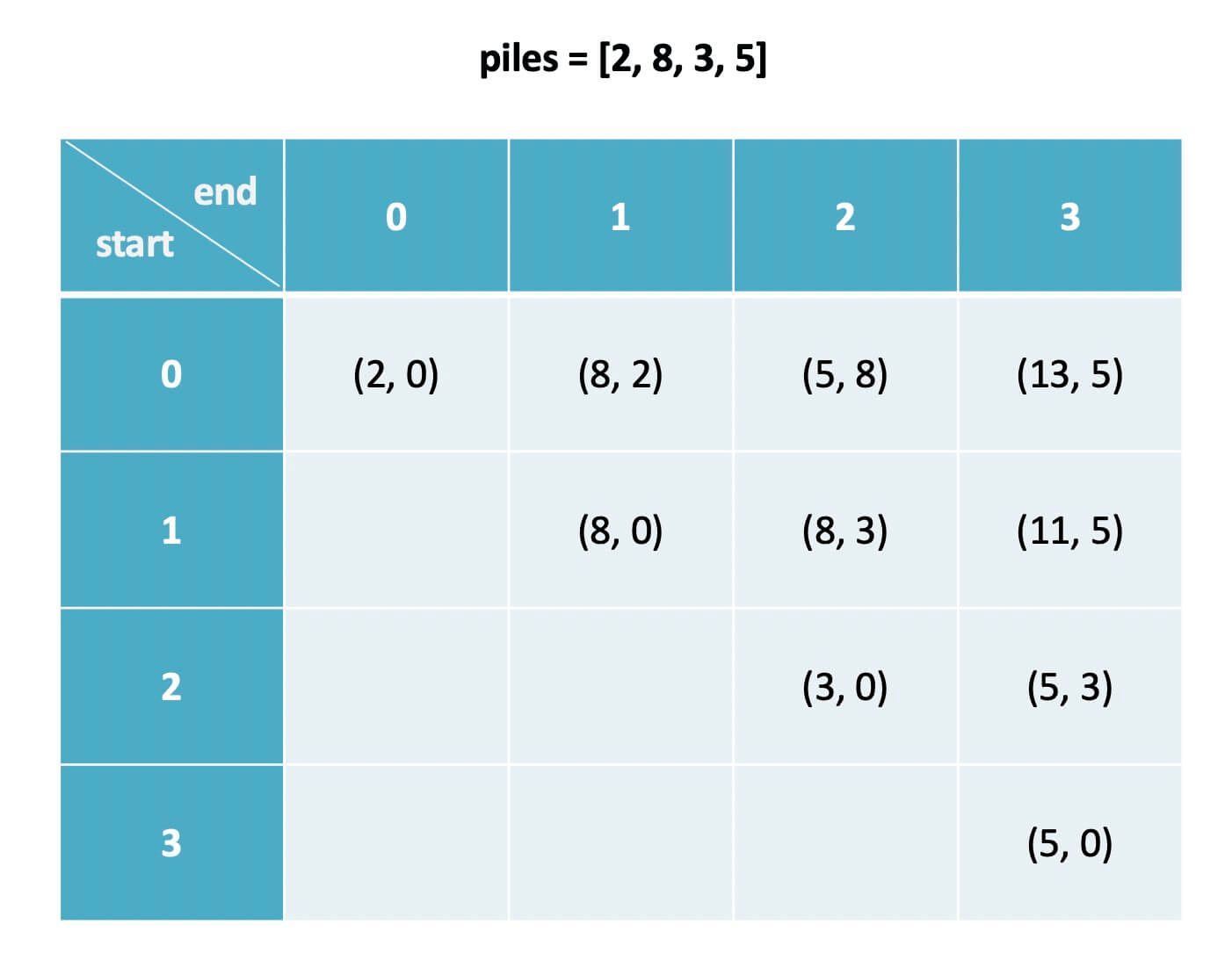
下文讲解时,认为元组是包含 first 和 second 属性的一个类,而且为了节省篇幅,将这两个属性简写为 fir 和 sec。比如按上图的数据,我们说 dp[1][3].fir = 11,dp[0][1].sec = 2。
先回答几个读者可能提出的问题:
这个二维 dp table 中存储的是元组,怎么编程表示呢?这个 dp table 有一半根本没用上,怎么优化?很简单,都不要管,先把解题的思路想明白了再谈也不迟。
以下是对 dp 数组含义的解释:
dp[i][j].fir = x 表示,对于 piles[i...j] 这部分石头堆,先手能获得的最高分数为 x。
dp[i][j].sec = y 表示,对于 piles[i...j] 这部分石头堆,后手能获得的最高分数为 y。
举例理解一下,假设 piles = [2, 8, 3, 5],索引从 0 开始,那么:
dp[0][1].fir = 8 意味着:面对石头堆 [2, 8],先手最多能够获得 8 分;dp[1][3].sec = 5 意味着:面对石头堆 [8, 3, 5],后手最多能够获得 5 分。
我们想求的答案是先手和后手最终分数之差,按照这个定义也就是 dp[0][n-1].fir - dp[0][n-1].sec,即面对整个 piles,先手的最优得分和后手的最优得分之差。
状态转移方程
写状态转移方程很简单,首先要找到所有「状态」和每个状态可以做的「选择」,然后择优。
根据前面对 dp 数组的定义,状态显然有三个:开始的索引 i,结束的索引 j,当前轮到的人。
dp[i][j][fir or sec]
其中:
0 <= i < piles.length
i <= j < piles.length
对于这个问题的每个状态,可以做的选择有两个:选择最左边的那堆石头,或者选择最右边的那堆石头。 我们可以这样穷举所有状态:
n = piles.length
for 0 <= i < n:
for j <= i < n:
for who in {fir, sec}:
dp[i][j][who] = max(left, right)
上面的伪码是动态规划的一个大致的框架,这道题的难点在于,两人足够聪明,而且是交替进行选择的,也就是说先手的选择会对后手有影响,这怎么表达出来呢?
根据我们对 dp 数组的定义,很容易解决这个难点,写出状态转移方程:
dp[i][j].fir = max(piles[i] + dp[i+1][j].sec, piles[j] + dp[i][j-1].sec)
dp[i][j].fir = max( 选择最左边的石头堆 , 选择最右边的石头堆 )
# 解释:我作为先手,面对 piles[i...j] 时,有两种选择:
# 要么我选择最左边的那一堆石头 piles[i],局面变成了 piles[i+1...j],
# 然后轮到对方选了,我变成了后手,此时我作为后手的最优得分是 dp[i+1][j].sec
# 要么我选择最右边的那一堆石头 piles[j],局面变成了 piles[i...j-1]
# 然后轮到对方选了,我变成了后手,此时我作为后手的最优得分是 dp[i][j-1].sec
if 先手选择左边:
dp[i][j].sec = dp[i+1][j].fir
if 先手选择右边:
dp[i][j].sec = dp[i][j-1].fir
# 解释:我作为后手,要等先手先选择,有两种情况:
# 如果先手选择了最左边那堆,给我剩下了 piles[i+1...j]
# 此时轮到我,我变成了先手,此时的最优得分是 dp[i+1][j].fir
# 如果先手选择了最右边那堆,给我剩下了 piles[i...j-1]
# 此时轮到我,我变成了先手,此时的最优得分是 dp[i][j-1].fir
根据 dp 数组的定义,我们也可以找出 base case,也就是最简单的情况:
dp[i][j].fir = piles[i]
dp[i][j].sec = 0
其中 0 <= i == j < n
# 解释:i 和 j 相等就是说面前只有一堆石头 piles[i]
# 那么显然先手的得分为 piles[i]
# 后手没有石头拿了,得分为 0
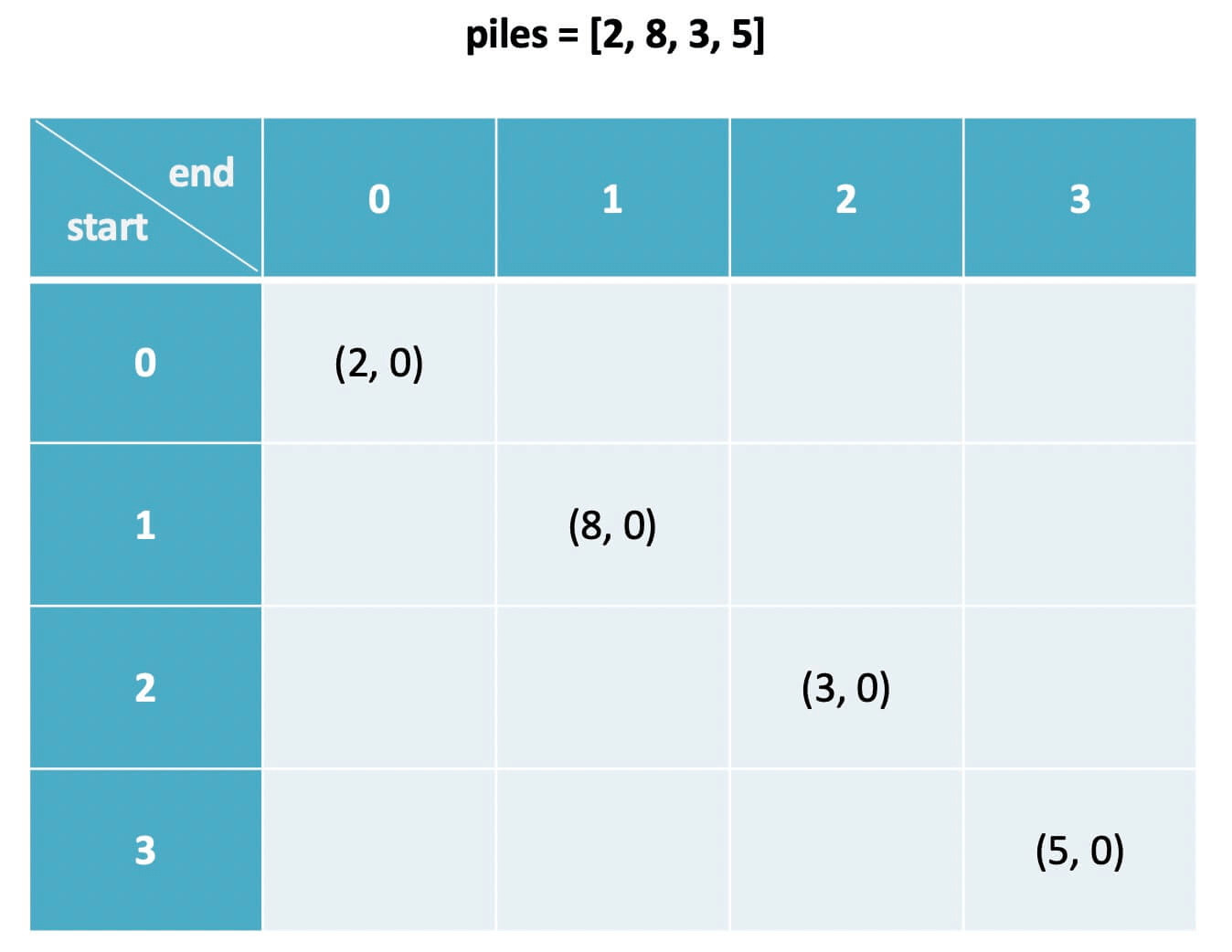
这里需要注意一点,我们发现 base case 是斜着的,而且我们推算 dp[i][j] 时需要用到 dp[i+1][j] 和 dp[i][j-1]:

判断 dp 数组遍历方向的原则,算法应该倒着遍历 dp 数组:
for (int i = n - 2; i >= 0; i--) {
for (int j = i + 1; j < n; j++) {
dp[i][j] = ...
}
}
代码实现
如何实现这个 fir 和 sec 元组呢,你可以用 python,自带元组类型;或者使用 C++ 的 pair 容器;或者用一个三维数组 dp[n][n][2],最后一个维度就相当于元组;或者我们自己写一个 Pair 类:
class Pair {
private:
int fir, sec;
public:
Pair(int fir, int sec) {
this->fir = fir;
this->sec = sec;
}
};
然后直接把我们的状态转移方程翻译成代码即可,注意我们要倒着遍历数组:
#include <iostream>
#include <algorithm>
using namespace std;
struct Pair {
int fir, sec;
Pair(int f, int s) : fir(f), sec(s) {}
};
/* 返回游戏最后先手和后手的得分之差 */
int stoneGame(int* piles, int n) {
// 初始化 dp 数组
Pair** dp = new Pair*[n];
for (int i = 0; i < n; i++)
dp[i] = new Pair[n];
for (int i = 0; i < n; i++)
for (int j = i; j < n; j++)
dp[i][j] = Pair(0, 0);
// 填入 base case
for (int i = 0; i < n; i++) {
dp[i][i].fir = piles[i];
dp[i][i].sec = 0;
}
// 倒着遍历数组
for (int i = n - 2; i >= 0; i--) {
for (int j = i + 1; j < n; j++) {
// 先手选择最左边或最右边的分数
int left = piles[i] + dp[i+1][j].sec;
int right = piles[j] + dp[i][j-1].sec;
// 套用状态转移方程
// 先手肯定会选择更大的结果,后手的选择随之改变
if (left > right) {
dp[i][j].fir = left;
dp[i][j].sec = dp[i+1][j].fir;
} else {
dp[i][j].fir = right;
dp[i][j].sec = dp[i][j-1].fir;
}
}
}
Pair res = dp[0][n-1];
for (int i = 0; i < n; i++) {
delete[] dp[i];
}
delete[] dp;
return res.fir - res.sec;
}
int main() {
int piles[] = {3, 9, 1, 2};
int n = sizeof(piles) / sizeof(*piles);
cout << stoneGame(piles, n) << endl;
return 0;
}
总结
本文给出了解决博弈问题的动态规划解法。博弈问题的前提一般都是在两个聪明人之间进行,编程描述这种游戏的一般方法是二维 dp 数组,数组中通过元组分别表示两人的最优决策。
之所以这样设计,是因为先手在做出选择之后,就成了后手,后手在对方做完选择后,就变成了先手。这种角色转换使得我们可以重用之前的结果,典型的动态规划标志。
四键键盘
题目
假设你有一个特殊的键盘,上面只有四个键,它们分别是:
1、A 键:在屏幕上打印一个 A。
2、Ctrl-A 键:选中整个屏幕。
3、Ctrl-C 键:复制选中的区域到缓冲区。
4、Ctrl-V 键:将缓冲区的内容输入到光标所在的屏幕上。
这就和我们平时使用的全选复制粘贴功能完全相同嘛,只不过题目把 Ctrl 的组合键视为了一个键。现在要求你只能进行 N 次操作,请你计算屏幕上最多能显示多少个 A?
函数签名如下:
int maxA(int N);
比如说输入 N = 3,算法返回 3,因为连按 3 次 A 键是最优的方案。
如果输入是 N = 7,则算法返回 9,最优的操作序列如下:
A, A, A, Ctrl-A, Ctrl-C, Ctrl-V, Ctrl-V
可以得到 9 个 A。
如何在 N 次敲击按钮后得到最多的 A?我们穷举呗,每次有对于每次按键,我们可以穷举四种可能,很明显就是一个动态规划问题。
第一种思路
这种思路会很容易理解,但是效率并不高,我们直接走流程:对于动态规划问题,首先要明白有哪些「状态」,有哪些「选择」。
具体到这个问题,对于每次敲击按键,有哪些「选择」是很明显的:4 种,就是题目中提到的四个按键,分别是 A、C-A、C-C、C-V(Ctrl 简写为 C)。
接下来,思考一下对于这个问题有哪些「状态」?或者换句话说,我们需要知道什么信息,才能将原问题分解为规模更小的子问题?
你看我这样定义三个状态行不行:第一个状态是剩余的按键次数,用 n 表示;第二个状态是当前屏幕上字符 A 的数量,用 a_num 表示;第三个状态是剪切板中字符 A 的数量,用 copy 表示。
如此定义「状态」,就可以知道 base case:当剩余次数 n 为 0 时,a_num 就是我们想要的答案。
结合刚才说的 4 种「选择」,我们可以把这几种选择通过状态转移表示出来:
dp(n - 1, a_num + 1, copy), # A
解释:按下 A 键,屏幕上加一个字符
同时消耗 1 个操作数
dp(n - 1, a_num + copy, copy), # C-V
解释:按下 C-V 粘贴,剪切板中的字符加入屏幕
同时消耗 1 个操作数
dp(n - 2, a_num, a_num) # C-A C-C
解释:全选和复制必然是联合使用的,
剪切板中 A 的数量变为屏幕上 A 的数量
同时消耗 2 个操作数
这样可以看到问题的规模 n 在不断减小,肯定可以到达 n = 0 的 base case,所以这个思路是正确的:
int maxA(int n) {
// 对于 (n, a_num, copy) 这个状态,
// 屏幕上能最终最多能有 dp(n, a_num, copy) 个 A
map<tuple<int,int,int>, int> memo;
// 定义 dp 函数
function<int(int,int,int)> dp = [&](int n, int a_num, int copy) -> int {
// base case
if(n <= 0) return a_num;
auto key = make_tuple(n, a_num, copy);
if(memo.count(key)) return memo[key];
// 几种选择全试一遍,选择最大的结果
memo[key] = max({dp(n-1, a_num + 1, copy), dp(n-1, a_num + copy, copy), dp(n-2, a_num, a_num + copy)});
return memo[key];
};
// 可以按 N 次按键,屏幕和剪切板里都还没有 A
return dp(n, 0, 0);
}
我们尝试分析一下这个算法的时间复杂度,就会发现不容易分析。我们可以把这个 dp 函数写成 dp 数组:
dp[n][a_num][copy]
# 状态的总数(时空复杂度)就是这个三维数组的体积
我们知道变量 n 最多为 N,但是 a_num 和 copy 最多为多少我们很难计算,复杂度起码也有 O(N^3) 吧。所以这个算法并不好,复杂度太高,且已经无法优化了。
这也就说明,我们这样定义「状态」是不太优秀的,下面我们换一种定义 dp 的思路。
第二种思路
这种思路稍微有点复杂,但是效率高。继续走流程,「选择」还是那 4 个,但是这次我们只定义一个「状态」,也就是剩余的敲击次数 n。
这个算法基于这样一个事实,最优按键序列一定只有两种情况:
要么一直按 A:A,A,…A(当 N 比较小时)。
要么是这么一个形式:A,A,…C-A,C-C,C-V,C-V,…C-V(当 N 比较大时)。
因为字符数量少(N 比较小)时,C-A C-C C-V 这一套操作的代价相对比较高,可能不如一个个按 A;而当 N 比较大时,后期 C-V 的收获肯定很大。这种情况下整个操作序列大致是:开头连按几个 A,然后 C-A C-C 组合再接若干 C-V,然后再 C-A C-C 接着若干 C-V,循环下去。
换句话说,最后一次按键要么是 A 要么是 C-V。明确了这一点,可以通过这两种情况来设计算法:
int[] dp = new int[N + 1];
// 定义:dp[i] 表示 i 次操作后最多能显示多少个 A
for (int i = 0; i <= N; i++)
dp[i] = max(
这次按 A 键,
这次按 C-V
)
对于「按 A 键」这种情况,就是状态 i - 1 的屏幕上新增了一个 A 而已,很容易得到结果:
// 按 A 键,就比上次多一个 A 而已
dp[i] = dp[i - 1] + 1;
但是,如果要按 C-V,还要考虑之前是在哪里 C-A C-C 的。
刚才说了,最优的操作序列一定是 C-A C-C 接着若干 C-V,所以我们用一个变量 j 作为若干 C-V 的起点。那么 j 之前的 2 个操作就应该是 C-A C-C 了:
int maxA(int N) {
vector<int> dp(N + 1);
dp[0] = 0;
for (int i = 1; i <= N; i++) {
// 按 A 键
dp[i] = dp[i - 1] + 1;
for (int j = 2; j < i; j++) {
// 全选 & 复制 dp[j-2],连续粘贴 i - j 次
// 屏幕上共 dp[j - 2] * (i - j + 1) 个 A
dp[i] = max(dp[i], dp[j - 2] * (i - j + 1));
}
}
// N 次按键之后最多有几个 A?
return dp[N];
}
其中 j 变量减 2 是给 C-A C-C 留下操作数,看个图就明白了:

这样,此算法就完成了,时间复杂度 O(N^2),空间复杂度 O(N),这种解法应该是比较高效的了。
总结
动态规划难就难在寻找状态转移,不同的定义可以产生不同的状态转移逻辑,虽然最后都能得到正确的结果,但是效率可能有巨大的差异。
回顾第一种解法,重叠子问题已经消除了,但是效率还是低,到底低在哪里呢?抽象出递归框架:
def dp(n, a_num, copy):
dp(n - 1, a_num + 1, copy), # A
dp(n - 1, a_num + copy, copy), # C-V
dp(n - 2, a_num, a_num) # C-A C-C
看这个穷举逻辑,是有可能出现这样的操作序列 C-A C-C,C-A C-C... 或者 C-V,C-V,...。然这种操作序列的结果不是最优的,但是我们并没有想办法规避这些情况的发生,从而增加了很多没必要的子问题计算。
回顾第二种解法,我们稍加思考就能想到,最优的序列应该是这种形式:A,A..C-A,C-C,C-V,C-V..C-A,C-C,C-V..。
根据这个事实,我们重新定义了状态,重新寻找了状态转移,从逻辑上减少了无效的子问题个数,从而提高了算法的效率。
团灭LeetCode股票
这 6 道题目是有共性的,我们只需要抽出来力扣第 188 题「买卖股票的最佳时机 IV」进行研究,因为这道题是最泛化的形式,其他的问题都是这个形式的简化,看下题目:
题目
给你一个整数数组 prices 和一个整数 k ,其中 prices[i] 是某支给定的股票在第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 k 笔交易。也就是说,你最多可以买 k 次,卖 k 次。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入:k = 2, prices = [2,4,1]
输出:2
解释:在第 1 天 (股票价格 = 2) 的时候买入,在第 2 天 (股票价格 = 4) 的时候卖出,这笔交易所能获得利润 = 4-2 = 2 。
示例 2:
输入:k = 2, prices = [3,2,6,5,0,3]
输出:7
解释:在第 2 天 (股票价格 = 2) 的时候买入,在第 3 天 (股票价格 = 6) 的时候卖出, 这笔交易所能获得利润 = 6-2 = 4 。
随后,在第 5 天 (股票价格 = 0) 的时候买入,在第 6 天 (股票价格 = 3) 的时候卖出, 这笔交易所能获得利润 = 3-0 = 3 。
提示:
1 <= k <= 1001 <= prices.length <= 10000 <= prices[i] <= 1000
第一题是只进行一次交易,相当于 k = 1;第二题是不限交易次数,相当于 k = +infinity(正无穷);第三题是只进行 2 次交易,相当于 k = 2;剩下两道也是不限次数,但是加了交易「冷冻期」和「手续费」的额外条件,其实就是第二题的变种,都很容易处理。
穷举框架
动态规划算法本质上就是穷举「状态」,然后在「选择」中选择最优解。
那么对于这道题,我们具体到每一天,看看总共有几种可能的「状态」,再找出每个「状态」对应的「选择」。我们要穷举所有「状态」,穷举的目的是根据对应的「选择」更新状态。听起来抽象,你只要记住「状态」和「选择」两个词就行,下面实操一下就很容易明白了。
for 状态1 in 状态1的所有取值:
for 状态2 in 状态2的所有取值:
for ...
dp[状态1][状态2][...] = 择优(选择1,选择2...)
比如说这个问题,每天都有三种「选择」:买入、卖出、无操作,我们用 buy, sell, rest 表示这三种选择。
但问题是,并不是每天都可以任意选择这三种选择的,因为 sell 必须在 buy 之后,buy 必须在 sell 之后。那么 rest 操作还应该分两种状态,一种是 buy 之后的 rest(持有了股票),一种是 sell 之后的 rest(没有持有股票)。而且别忘了,我们还有交易次数 k 的限制,就是说你 buy 还只能在 k > 0 的前提下操作。
本文会频繁使用「交易」这个词,我们把一次买入和一次卖出定义为一次「交易」。
很复杂对吧,不要怕,我们现在的目的只是穷举,你有再多的状态,老夫要做的就是一把梭全部列举出来。
这个问题的「状态」有三个,第一个是天数,第二个是允许交易的最大次数,第三个是当前的持有状态(即之前说的 rest 的状态,我们不妨用 1 表示持有,0 表示没有持有)。然后我们用一个三维数组就可以装下这几种状态的全部组合:
dp[i][k][0 or 1]
0 <= i <= n - 1, 1 <= k <= K
n 为天数,大 K 为交易数的上限,0 和 1 代表是否持有股票。
此问题共 n × K × 2 种状态,全部穷举就能搞定。
for 0 <= i < n:
for 1 <= k <= K:
for s in {0, 1}:
dp[i][k][s] = max(buy, sell, rest)
而且我们可以用自然语言描述出每一个状态的含义,比如说 dp[3][2][1] 的含义就是:今天是第三天,我现在手上持有着股票,至今最多进行 2 次交易。再比如 dp[2][3][0] 的含义:今天是第二天,我现在手上没有持有股票,至今最多进行 3 次交易。很容易理解,对吧?
我们想求的最终答案是 dp[n - 1][K][0],即最后一天,最多允许 K 次交易,最多获得多少利润。
读者可能问为什么不是 dp[n - 1][K][1]?因为 dp[n - 1][K][1] 代表到最后一天手上还持有股票,dp[n - 1][K][0] 表示最后一天手上的股票已经卖出去了,很显然后者得到的利润一定大于前者。
记住如何解释「状态」,一旦你觉得哪里不好理解,把它翻译成自然语言就容易理解了。
状态转移框架
现在,我们完成了「状态」的穷举,我们开始思考每种「状态」有哪些「选择」,应该如何更新「状态」。
只看「持有状态」,可以画个状态转移图:
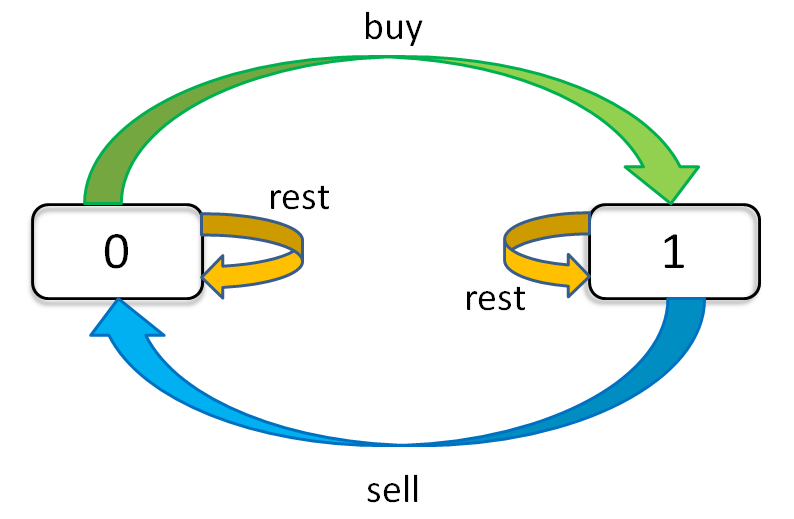
通过这个图可以很清楚地看到,每种状态(0 和 1)是如何转移而来的。根据这个图,我们来写一下状态转移方程:
dp[i][k][0] = max(dp[i-1][k][0], dp[i-1][k][1] + prices[i])
= max( 今天选择 rest, 今天选择 sell )
解释:今天我没有持有股票,有两种可能,我从这两种可能中求最大利润:
1、我昨天就没有持有,且截至昨天最大交易次数限制为 k;然后我今天选择 rest,所以我今天还是没有持有,最大交易次数限制依然为 k。
2、我昨天持有股票,且截至昨天最大交易次数限制为 k;但是今天我 sell 了,所以我今天没有持有股票了,最大交易次数限制依然为 k。
dp[i][k][1] = max(dp[i-1][k][1], dp[i-1][k-1][0] - prices[i])
= max( 今天选择 rest, 今天选择 buy )
解释:今天我持有着股票,最大交易次数限制为 k,那么对于昨天来说,有两种可能,我从这两种可能中求最大利润:
1、我昨天就持有着股票,且截至昨天最大交易次数限制为 k;然后今天选择 rest,所以我今天还持有着股票,最大交易次数限制依然为 k。
2、我昨天本没有持有,且截至昨天最大交易次数限制为 k - 1;但今天我选择 buy,所以今天我就持有股票了,最大交易次数限制为 k。
这里着重提醒一下,时刻牢记「状态」的定义,状态
k的定义并不是「已进行的交易次数」,而是「最大交易次数的上限限制」。如果确定今天进行一次交易,且要保证截至今天最大交易次数上限为k,那么昨天的最大交易次数上限必须是k - 1。举个具体的例子,比方说要求你的银行卡里今天至少有 100 块钱,且你确定你今天可以赚 10 块钱,那么你就要保证昨天的银行卡要至少剩下 90 块钱。
这个解释应该很清楚了,如果 buy,就要从利润中减去 prices[i],如果 sell,就要给利润增加 prices[i]。今天的最大利润就是这两种可能选择中较大的那个。
注意 k 的限制,在选择 buy 的时候相当于开启了一次交易,那么对于昨天来说,交易次数的上限 k 应该减小 1。
这里补充修正一点,以前我以为在
sell的时候给k减小 1 和在buy的时候给k减小 1 是等效的,但细心的读者向我提出质疑,经过深入思考我发现前者确实是错误的,因为交易是从buy开始,如果buy的选择不改变交易次数k的话,会出现交易次数超出限制的的错误。
现在,我们已经完成了动态规划中最困难的一步:状态转移方程。如果之前的内容你都可以理解,那么你已经可以秒杀所有问题了,只要套这个框架就行了。不过还差最后一点点,就是定义 base case,即最简单的情况。
dp[-1][...][0] = 0
解释:因为 i 是从 0 开始的,所以 i = -1 意味着还没有开始,这时候的利润当然是 0。
dp[-1][...][1] = -infinity
解释:还没开始的时候,是不可能持有股票的。
因为我们的算法要求一个最大值,所以初始值设为一个最小值,方便取最大值。
dp[...][0][0] = 0
解释:因为 k 是从 1 开始的,所以 k = 0 意味着根本不允许交易,这时候利润当然是 0。
dp[...][0][1] = -infinity
解释:不允许交易的情况下,是不可能持有股票的。
因为我们的算法要求一个最大值,所以初始值设为一个最小值,方便取最大值。
把上面的状态转移方程总结一下:
base case:
dp[-1][...][0] = dp[...][0][0] = 0
dp[-1][...][1] = dp[...][0][1] = -infinity
状态转移方程:
dp[i][k][0] = max(dp[i-1][k][0], dp[i-1][k][1] + prices[i])
dp[i][k][1] = max(dp[i-1][k][1], dp[i-1][k-1][0] - prices[i])
读者可能会问,这个数组索引是 -1 怎么编程表示出来呢,负无穷怎么表示呢?这都是细节问题,有很多方法实现。现在完整的框架已经完成,下面开始具体化。
团灭股票
第一题:相当于 k = 1 的情况
题目
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
示例 1:
输入:[7,1,5,3,6,4]
输出:5
解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。
示例 2:
输入:prices = [7,6,4,3,1]
输出:0
解释:在这种情况下, 没有交易完成, 所以最大利润为 0。
提示:
1 <= prices.length <= 1050 <= prices[i] <= 104
解决
直接套状态转移方程,根据 base case,可以做一些化简:
dp[i][1][0] = max(dp[i-1][1][0], dp[i-1][1][1] + prices[i])
dp[i][1][1] = max(dp[i-1][1][1], dp[i-1][0][0] - prices[i])
= max(dp[i-1][1][1], -prices[i])
解释:k = 0 的 base case,所以 dp[i-1][0][0] = 0。
现在发现 k 都是 1,不会改变,即 k 对状态转移已经没有影响了。
可以进行进一步化简去掉所有 k:
dp[i][0] = max(dp[i-1][0], dp[i-1][1] + prices[i])
dp[i][1] = max(dp[i-1][1], -prices[i])
int n = prices.size();
vector<vector<int>> dp(n, vector<int>(2));
dp[0][0] = 0;
dp[0][1] = -prices[0];
for (int i = 1; i < n; ++i) {
dp[i][0] = max(dp[i-1][0], dp[i-1][1] + prices[i]);
dp[i][1] = max(dp[i-1][1], -prices[i]);
}
return dp[n-1][0];
显然 i = 0 时 i - 1 是不合法的索引,这是因为我们没有对 i 的 base case 进行处理,可以这样给一个特化处理:
if (i - 1 == -1) {
dp[i][0] = 0;
// 根据状态转移方程可得:
// dp[i][0]
// = max(dp[-1][0], dp[-1][1] + prices[i])
// = max(0, -infinity + prices[i]) = 0
dp[i][1] = -prices[i];
// 根据状态转移方程可得:
// dp[i][1]
// = max(dp[-1][1], dp[-1][0] - prices[i])
// = max(-infinity, 0 - prices[i])
// = -prices[i]
continue;
}
第一题就解决了,但是这样处理 base case 很麻烦,而且注意一下状态转移方程,新状态只和相邻的一个状态有关,不需要用整个 dp 数组,只需要一个变量储存相邻的那个状态就足够了,这样可以把空间复杂度降到 O(1):
// 空间复杂度优化版本
int maxProfit_k_1(vector<int>& prices) {
int n = prices.size();
// base case: dp[-1][0] = 0, dp[-1][1] = -infinity
int dp_i_0 = 0, dp_i_1 = INT_MIN;
for (int i = 0; i < n; i++) {
// dp[i][0] = max(dp[i-1][0], dp[i-1][1] + prices[i])
dp_i_0 = max(dp_i_0, dp_i_1 + prices[i]);
// dp[i][1] = max(dp[i-1][1], -prices[i])
dp_i_1 = max(dp_i_1, -prices[i]);
}
return dp_i_0;
第二题:k 为正无穷的情况
题目
给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。
在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。
返回 你能获得的 最大 利润 。
示例 1:
输入:prices = [7,1,5,3,6,4]
输出:7
解释:在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5 - 1 = 4 。
随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6 - 3 = 3 。
总利润为 4 + 3 = 7 。
示例 2:
输入:prices = [1,2,3,4,5]
输出:4
解释:在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5 - 1 = 4 。
总利润为 4 。
示例 3:
输入:prices = [7,6,4,3,1]
输出:0
解释:在这种情况下, 交易无法获得正利润,所以不参与交易可以获得最大利润,最大利润为 0 。
提示:
1 <= prices.length <= 3 * 1040 <= prices[i] <= 104
解决
题目还专门强调可以在同一天出售,但我觉得这个条件纯属多余,如果当天买当天卖,那利润当然就是 0,这不是和没有进行交易是一样的吗?这道题的特点在于没有给出交易总数 k 的限制,也就相当于 k 为正无穷。
如果 k 为正无穷,那么就可以认为 k 和 k - 1 是一样的。可以这样改写框架:
dp[i][k][0] = max(dp[i-1][k][0], dp[i-1][k][1] + prices[i])
dp[i][k][1] = max(dp[i-1][k][1], dp[i-1][k-1][0] - prices[i])
= max(dp[i-1][k][1], dp[i-1][k][0] - prices[i])
我们发现数组中的 k 已经不会改变了,也就是说不需要记录 k 这个状态了:
dp[i][0] = max(dp[i-1][0], dp[i-1][1] + prices[i])
dp[i][1] = max(dp[i-1][1], dp[i-1][0] - prices[i])
直接翻译成代码:
// 原始版本
int maxProfit_k_inf(vector<int>& prices) {
int n = prices.size();
vector<vector<int>> dp(n, vector<int>(2, 0));
for (int i = 0; i < n; i++) {
if (i - 1 == -1) {
// base case
dp[i][0] = 0;
dp[i][1] = -prices[i];
continue;
}
dp[i][0] = max(dp[i-1][0], dp[i-1][1] + prices[i]);
dp[i][1] = max(dp[i-1][1], dp[i-1][0] - prices[i]);
}
return dp[n - 1][0];
}
// 空间复杂度优化版本
int maxProfit_k_inf(vector<int>& prices) {
int n = prices.size();
int dp_i_0 = 0, dp_i_1 = INT_MIN;
for (int i = 0; i < n; i++) {
int temp = dp_i_0;
dp_i_0 = max(dp_i_0, dp_i_1 + prices[i]);
dp_i_1 = max(dp_i_1, temp - prices[i]);
}
return dp_i_0;
}
第三题: k 为正无穷,但含有交易冷冻期的情况
题目
给定一个整数数组prices,其中第 prices[i] 表示第 *i* 天的股票价格 。
设计一个算法计算出最大利润。在满足以下约束条件下,你可以尽可能地完成更多的交易(多次买卖一支股票):
- 卖出股票后,你无法在第二天买入股票 (即冷冻期为 1 天)。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入: prices = [1,2,3,0,2]
输出: 3
解释: 对应的交易状态为: [买入, 卖出, 冷冻期, 买入, 卖出]
示例 2:
输入: prices = [1]
输出: 0
提示:
1 <= prices.length <= 50000 <= prices[i] <= 1000
解决
和上一道题一样的,只不过每次 sell 之后要等一天才能继续交易,只要把这个特点融入上一题的状态转移方程即可:
dp[i][0] = max(dp[i-1][0], dp[i-1][1] + prices[i])
dp[i][1] = max(dp[i-1][1], dp[i-2][0] - prices[i])
解释:第 i 天选择 buy 的时候,要从 i-2 的状态转移,而不是 i-1 。
// 原始版本
int maxProfit_with_cool(vector<int>& prices) {
int n = prices.size();
vector<vector<int>> dp(n, vector<int>(2));
for (int i = 0; i < n; i++) {
if (i - 1 == -1) {
// base case 1
dp[i][0] = 0;
dp[i][1] = -prices[i];
continue;
}
if (i - 2 == -1) {
// base case 2
dp[i][0] = max(dp[i-1][0], dp[i-1][1] + prices[i]);
// i - 2 小于 0 时根据状态转移方程推出对应 base case
dp[i][1] = max(dp[i-1][1], -prices[i]);
// dp[i][1]
// = max(dp[i-1][1], dp[-1][0] - prices[i])
// = max(dp[i-1][1], 0 - prices[i])
// = max(dp[i-1][1], -prices[i])
continue;
}
dp[i][0] = max(dp[i-1][0], dp[i-1][1] + prices[i]);
dp[i][1] = max(dp[i-1][1], dp[i-2][0] - prices[i]);
}
return dp[n - 1][0];
}
// 空间复杂度优化版本
int maxProfit_with_cool(vector<int>& prices) {
int n = prices.size();
int dp_i_0 = 0, dp_i_1 = INT_MIN;
int dp_pre_0 = 0; // 代表 dp[i-2][0]
for (int i = 0; i < n; i++) {
int temp = dp_i_0;
dp_i_0 = max(dp_i_0, dp_i_1 + prices[i]);
dp_i_1 = max(dp_i_1, dp_pre_0 - prices[i]);
dp_pre_0 = temp;
}
return dp_i_0;
}
第四题: k 为正无穷且考虑交易手续费的情况
题目
给定一个整数数组 prices,其中 prices[i]表示第 i 天的股票价格 ;整数 fee 代表了交易股票的手续费用。
你可以无限次地完成交易,但是你每笔交易都需要付手续费。如果你已经购买了一个股票,在卖出它之前你就不能再继续购买股票了。
返回获得利润的最大值。
注意:这里的一笔交易指买入持有并卖出股票的整个过程,每笔交易你只需要为支付一次手续费。
示例 1:
输入:prices = [1, 3, 2, 8, 4, 9], fee = 2
输出:8
解释:能够达到的最大利润:
在此处买入 prices[0] = 1
在此处卖出 prices[3] = 8
在此处买入 prices[4] = 4
在此处卖出 prices[5] = 9
总利润: ((8 - 1) - 2) + ((9 - 4) - 2) = 8
示例 2:
输入:prices = [1,3,7,5,10,3], fee = 3
输出:6
提示:
1 <= prices.length <= 5 * 1041 <= prices[i] < 5 * 1040 <= fee < 5 * 104
解决
每次交易要支付手续费,只要把手续费从利润中减去即可,改写方程:
dp[i][0] = max(dp[i-1][0], dp[i-1][1] + prices[i])
dp[i][1] = max(dp[i-1][1], dp[i-1][0] - prices[i] - fee)
解释:相当于买入股票的价格升高了。
在第一个式子里减也是一样的,相当于卖出股票的价格减小了。
如果直接把
fee放在第一个式子里减,会有一些测试用例无法通过,错误原因是整型溢出而不是思路问题。一种解决方案是把代码中的int类型都改成long类型,避免int的整型溢出。
// 原始版本
int maxProfit_with_fee(vector<int>& prices, int fee) {
int n = prices.size();
vector<vector<int>> dp(n, vector<int>(2));
for (int i = 0; i < n; i++) {
if (i - 1 == -1) {
// base case
dp[i][0] = 0;
dp[i][1] = -prices[i] - fee;
// dp[i][1]
// = max(dp[i - 1][1], dp[i - 1][0] - prices[i] - fee)
// = max(dp[-1][1], dp[-1][0] - prices[i] - fee)
// = max(-inf, 0 - prices[i] - fee)
// = -prices[i] - fee
continue;
}
dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] + prices[i]);
dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] - prices[i] - fee);
}
return dp[n - 1][0];
}
// 空间复杂度优化版本
int maxProfit_with_fee(vector<int>& prices, int fee) {
int n = prices.size();
int dp_i_0 = 0, dp_i_1 = INT_MIN;
for (int i = 0; i < n; i++) {
int temp = dp_i_0;
dp_i_0 = max(dp_i_0, dp_i_1 + prices[i]);
dp_i_1 = max(dp_i_1, temp - prices[i] - fee);
}
return dp_i_0;
}
第五题:k = 2 的情况
题目
给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔 交易。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入:prices = [3,3,5,0,0,3,1,4]
输出:6
解释:在第 4 天(股票价格 = 0)的时候买入,在第 6 天(股票价格 = 3)的时候卖出,这笔交易所能获得利润 = 3-0 = 3 。
随后,在第 7 天(股票价格 = 1)的时候买入,在第 8 天 (股票价格 = 4)的时候卖出,这笔交易所能获得利润 = 4-1 = 3 。
示例 2:
输入:prices = [1,2,3,4,5]
输出:4
解释:在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。
因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。
示例 3:
输入:prices = [7,6,4,3,1]
输出:0
解释:在这个情况下, 没有交易完成, 所以最大利润为 0。
示例 4:
输入:prices = [1]
输出:0
提示:
1 <= prices.length <= 1050 <= prices[i] <= 105
解决
k = 2 和前面题目的情况稍微不同,因为上面的情况都和 k 的关系不太大:要么 k 是正无穷,状态转移和 k 没关系了;要么 k = 1,跟 k = 0 这个 base case 挨得近,最后也没有存在感。
这道题 k = 2 和后面要讲的 k 是任意正整数的情况中,对 k 的处理就凸显出来了,我们直接写代码,边写边分析原因。
原始的状态转移方程,没有可化简的地方
dp[i][k][0] = max(dp[i-1][k][0], dp[i-1][k][1] + prices[i])
dp[i][k][1] = max(dp[i-1][k][1], dp[i-1][k-1][0] - prices[i])
按照之前的代码,我们可能想当然这样写代码(错误的):
int k = 2;
vector<vector<vector<int>>> dp(n, vector<vector<int>>(k + 1, vector<int>(2)));
for (int i = 0; i < n; i++) {
if (i - 1 == -1) {
// 处理 base case
dp[i][k][0] = 0;
dp[i][k][1] = -prices[i];
continue;
}
dp[i][k][0] = max(dp[i-1][k][0], dp[i-1][k][1] + prices[i]);
dp[i][k][1] = max(dp[i-1][k][1], dp[i-1][k-1][0] - prices[i]);
}
return dp[n - 1][k][0];
为什么错误?我这不是照着状态转移方程写的吗?
还记得前面总结的「穷举框架」吗?就是说我们必须穷举所有状态。其实我们之前的解法,都在穷举所有状态,只是之前的题目中 k 都被化简掉了。
当 k = 2 时,由于没有消掉 k 的影响,所以必须要对 k 进行穷举:
// 原始版本
int maxProfit_k_2(vector<int>& prices) {
int max_k = 2, n = prices.size();
vector<vector<vector<int>>> dp(n, vector<vector<int>>(max_k + 1, vector<int>(2)));
for (int i = 0; i < n; i++) {
for (int k = max_k; k >= 1; k--) {
if (i - 1 == -1) {
// 处理 base case
dp[i][k][0] = 0;
dp[i][k][1] = -prices[i];
continue;
}
dp[i][k][0] = max(dp[i-1][k][0], dp[i-1][k][1] + prices[i]);
dp[i][k][1] = max(dp[i-1][k][1], dp[i-1][k-1][0] - prices[i]);
}
}
// 穷举了 n × max_k × 2 个状态,正确。
return dp[n - 1][max_k][0];
}
这里肯定会有读者疑惑,
k的 base case 是 0,按理说应该从k = 1, k++这样穷举状态k才对?而且如果你真的这样从小到大遍历k,提交发现也是可以的。
dp 数组的遍历顺序是怎么确定的,主要是根据 base case,以 base case 为起点,逐步向结果靠近。
但为什么我从大到小遍历 k 也可以正确提交呢?因为你注意看,dp[i][k][..] 不会依赖 dp[i][k - 1][..],而是依赖 dp[i - 1][k - 1][..],而 dp[i - 1][..][..],都是已经计算出来的,所以不管你是 k = max_k, k--,还是 k = 1, k++,都是可以得出正确答案的。
那为什么我使用 k = max_k, k-- 的方式呢?因为这样符合语义:
你买股票,初始的「状态」是什么?应该是从第 0 天开始,而且还没有进行过买卖,所以最大交易次数限制 k 应该是 max_k;而随着「状态」的推移,你会进行交易,那么交易次数上限 k 应该不断减少,这样一想,k = max_k, k-- 的方式是比较合乎实际场景的。
当然,这里 k 取值范围比较小,所以也可以不用 for 循环,直接把 k = 1 和 2 的情况全部列举出来也可以:
// 状态转移方程:
// dp[i][2][0] = max(dp[i-1][2][0], dp[i-1][2][1] + prices[i])
// dp[i][2][1] = max(dp[i-1][2][1], dp[i-1][1][0] - prices[i])
// dp[i][1][0] = max(dp[i-1][1][0], dp[i-1][1][1] + prices[i])
// dp[i][1][1] = max(dp[i-1][1][1], -prices[i])
// 空间复杂度优化版本
class Solution {
public:
int maxProfit_k_2(vector<int>& prices) {
// base case
int dp_i10 = 0, dp_i11 = INT_MIN;
int dp_i20 = 0, dp_i21 = INT_MIN;
for (int price : prices) {
dp_i20 = max(dp_i20, dp_i21 + price);
dp_i21 = max(dp_i21, dp_i10 - price);
dp_i10 = max(dp_i10, dp_i11 + price);
dp_i11 = max(dp_i11, -price);
}
return dp_i20;
}
};
第六题:k 可以是题目给定的任何数的情况
题目
给你一个整数数组 prices 和一个整数 k ,其中 prices[i] 是某支给定的股票在第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 k 笔交易。也就是说,你最多可以买 k 次,卖 k 次。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入:k = 2, prices = [2,4,1]
输出:2
解释:在第 1 天 (股票价格 = 2) 的时候买入,在第 2 天 (股票价格 = 4) 的时候卖出,这笔交易所能获得利润 = 4-2 = 2 。
示例 2:
输入:k = 2, prices = [3,2,6,5,0,3]
输出:7
解释:在第 2 天 (股票价格 = 2) 的时候买入,在第 3 天 (股票价格 = 6) 的时候卖出, 这笔交易所能获得利润 = 6-2 = 4 。
随后,在第 5 天 (股票价格 = 0) 的时候买入,在第 6 天 (股票价格 = 3) 的时候卖出, 这笔交易所能获得利润 = 3-0 = 3 。
提示:
1 <= k <= 1001 <= prices.length <= 10000 <= prices[i] <= 1000
解决
有了上一题 k = 2 的铺垫,这题应该和上一题的第一个解法没啥区别,你把上一题的 k = 2 换成题目输入的 k 就行了。
但试一下发现会出一个内存超限的错误,原来是传入的 k 值会非常大,dp 数组太大了。那么现在想想,交易次数 k 最多有多大呢?
一次交易由买入和卖出构成,至少需要两天。所以说有效的限制 k 应该不超过 n/2,如果超过,就没有约束作用了,相当于 k 没有限制的情况,而这种情况是之前解决过的。
所以我们可以直接把之前的代码重用:
int maxProfit_k_any(int max_k, vector<int>& prices) {
int n = prices.size();
if (n <= 0) {
return 0;
}
if (max_k > n / 2) {
// 复用之前交易次数 k 没有限制的情况
return maxProfit_k_inf(prices);
}
// base case:
// dp[-1][...][0] = dp[...][0][0] = 0
// dp[-1][...][1] = dp[...][0][1] = -infinity
vector<vector<vector<int>>> dp(n, vector<vector<int>>(max_k + 1, vector<int>(2)));
// k = 0 时的 base case
for (int i = 0; i < n; i++) {
dp[i][0][1] = INT_MIN;
dp[i][0][0] = 0;
}
for (int i = 0; i < n; i++){
for (int k = max_k; k >= 1; k--) {
if (i - 1 == -1) {
// 处理 i = -1 时的 base case
dp[i][k][0] = 0;
dp[i][k][1] = -prices[i];
continue;
}
dp[i][k][0] = max(dp[i-1][k][0], dp[i-1][k][1] + prices[i]);
dp[i][k][1] = max(dp[i-1][k][1], dp[i-1][k-1][0] - prices[i]);
}
}
return dp[n - 1][max_k][0];
}
万法归一
实现如下函数:
int maxProfit_all_in_one(int max_k, int[] prices, int cooldown, int fee);
输入股票价格数组 prices,你最多进行 max_k 次交易,每次交易需要额外消耗 fee 的手续费,而且每次交易之后需要经过 cooldown 天的冷冻期才能进行下一次交易,请你计算并返回可以获得的最大利润。
很容易发现这道题目就是之前我们探讨的几种情况的组合体嘛。
所以,我们只要把之前实现的几种代码掺和到一块,在 base case 和状态转移方程中同时加上 cooldown 和 fee 的约束就行了:
// 同时考虑交易次数的限制、冷冻期和手续费
int maxProfit_all_in_one(int max_k, vector<int>& prices, int cooldown, int fee) {
int n = prices.size();
if (n <= 0) {
return 0;
}
if (max_k > n / 2) {
// 交易次数 k 没有限制的情况
return maxProfit_k_inf(prices, cooldown, fee);
}
vector<vector<vector<int>>> dp(n, vector<vector<int>>(max_k + 1, vector<int>(2)));
// k = 0 时的 base case
for (int i = 0; i < n; i++) {
dp[i][0][1] = INT_MIN;
dp[i][0][0] = 0;
}
for (int i = 0; i < n; i++) {
for (int k = max_k; k >= 1; k--) {
if (i - 1 == -1) {
// base case 1
dp[i][k][0] = 0;
dp[i][k][1] = -prices[i] - fee;
continue;
}
// 包含 cooldown 的 base case
if (i - cooldown - 1 < 0) {
// base case 2
dp[i][k][0] = max(dp[i-1][k][0], dp[i-1][k][1] + prices[i]);
// 别忘了减 fee
dp[i][k][1] = max(dp[i-1][k][1], -prices[i] - fee);
continue;
}
dp[i][k][0] = max(dp[i-1][k][0], dp[i-1][k][1] + prices[i]);
// 同时考虑 cooldown 和 fee
dp[i][k][1] = max(dp[i-1][k][1], dp[i-cooldown-1][k-1][0] - prices[i] - fee);
}
}
return dp[n - 1][max_k][0];
}
// k 无限制,包含手续费和冷冻期
int maxProfit_k_inf(vector<int>& prices, int cooldown, int fee) {
int n = prices.size();
vector<vector<int>> dp(n, vector<int>(2));
for (int i = 0; i < n; i++) {
if (i - 1 == -1) {
// base case 1
dp[i][0] = 0;
dp[i][1] = -prices[i] - fee;
continue;
}
// 包含 cooldown 的 base case
if (i - cooldown - 1 < 0) {
// base case 2
dp[i][0] = max(dp[i-1][0], dp[i-1][1] + prices[i]);
// 别忘了减 fee
dp[i][1] = max(dp[i-1][1], -prices[i] - fee);
continue;
}
dp[i][0] = max(dp[i-1][0], dp[i-1][1] + prices[i]);
// 同时考虑 cooldown 和 fee
dp[i][1] = max(dp[i-1][1], dp[i-cooldown-1][0] - prices[i] - fee);
}
return dp[n - 1][0];
}
最后总结一下吧,本文讲了如何通过状态转移的方法解决复杂的问题,用一个状态转移方程秒杀了 6 道股票买卖问题。
关键就在于列举出所有可能的「状态」,然后想想怎么穷举更新这些「状态」。一般用一个多维 dp 数组储存这些状态,从 base case 开始向后推进,推进到最后的状态,就是我们想要的答案。想想这个过程,你是不是有点理解「动态规划」这个名词的意义了呢?
贪心类型问题
老司机加油算法
题目
在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
给定两个整数数组 gas 和 cost ,如果你可以按顺序绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1 。如果存在解,则 保证 它是 唯一 的。
示例 1:
输入: gas = [1,2,3,4,5], cost = [3,4,5,1,2]
输出: 3
解释:
从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油
开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油
开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油
开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油
开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油
开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。
因此,3 可为起始索引。
示例 2:
输入: gas = [2,3,4], cost = [3,4,3]
输出: -1
解释:
你不能从 0 号或 1 号加油站出发,因为没有足够的汽油可以让你行驶到下一个加油站。
我们从 2 号加油站出发,可以获得 4 升汽油。 此时油箱有 = 0 + 4 = 4 升汽油
开往 0 号加油站,此时油箱有 4 - 3 + 2 = 3 升汽油
开往 1 号加油站,此时油箱有 3 - 3 + 3 = 3 升汽油
你无法返回 2 号加油站,因为返程需要消耗 4 升汽油,但是你的油箱只有 3 升汽油。
因此,无论怎样,你都不可能绕环路行驶一周。
提示:
gas.length == ncost.length == n1 <= n <= 1050 <= gas[i], cost[i] <= 104
思路
题目应该不难理解,就是每到达一个站点 i,可以加 gas[i] 升油,但离开站点 i 需要消耗 cost[i] 升油,问你从哪个站点出发,可以兜一圈回来。
要说暴力解法,肯定很容易想到,用一个 for 循环遍历所有站点,假设为起点,然后再套一层 for 循环,判断一下是否能够转一圈回到起点:
int n = gas.length;
for (int start = 0; start < n; start++) {
for (int step = 0; step < n; step++) {
int i = (start + step) % n;
tank += gas[i];
tank -= cost[i];
// 判断油箱中的油是否耗尽
}
}
很明显时间复杂度是 O(N^2),这么简单粗暴的解法一定不是最优的,我们试图分析一下是否有优化的余地。
暴力解法是否有重复计算的部分?是否可以抽象出「状态」,是否对同一个「状态」重复计算了多次?
前文 动态规划详解 说过,变化的量就是「状态」。那么观察这个暴力穷举的过程,变化的量有两个,分别是「起点」和「当前油箱的油量」,但这两个状态的组合肯定有不下 O(N^2) 种,显然没有任何优化的空间。
所以说这道题肯定不是通过简单的剪枝来优化暴力解法的效率,而是需要我们发现一些隐藏较深的规律,从而减少一些冗余的计算。
图像解法
汽车进入站点 i 可以加 gas[i] 的油(图中绿色数字),离开站点会损耗 cost[i] 的油(图中红色数字),那么可以把站点和与其相连的路看做一个整体,将 gas[i] - cost[i] 作为经过站点 i 的油量变化值(图中橙色数字):
这样,题目描述的场景就被抽象成了一个环形数组,数组中的第 i 个元素就是 gas[i] - cost[i]。
有了这个环形数组,我们需要判断这个环形数组中是否能够找到一个起点 start,使得从这个起点开始的累加和一直大于等于 0。
如何判断是否存在这样一个起点 start?又如何计算这个起点 start 的值呢?
我们不妨就把 0 作为起点,计算累加和的代码非常简单:
int n = gas.length, sum = 0;
for (int i = 0; i < n; i++) {
// 计算累加和
sum += gas[i] - cost[i];
}
上述代码的 sum 就相当于是油箱中油量的变化,比如给你输入这组测试用例:
gas = [4,3,1,2,7,4]
cost = [1,2,7,3,2,5]
sum 的变化过程就是这样的:

那么你是否能根据这幅图,判断把哪一个加油站作为起点呢?
显然,将 0 作为起点肯定是不行的,因为 sum 在变化的过程中小于 0 了,不符合我们「累加和一直大于等于 0」的要求。
那如果 0 不能作为起点,谁可以作为起点呢?
看图说话,图像的最低点最有可能可以作为起点:
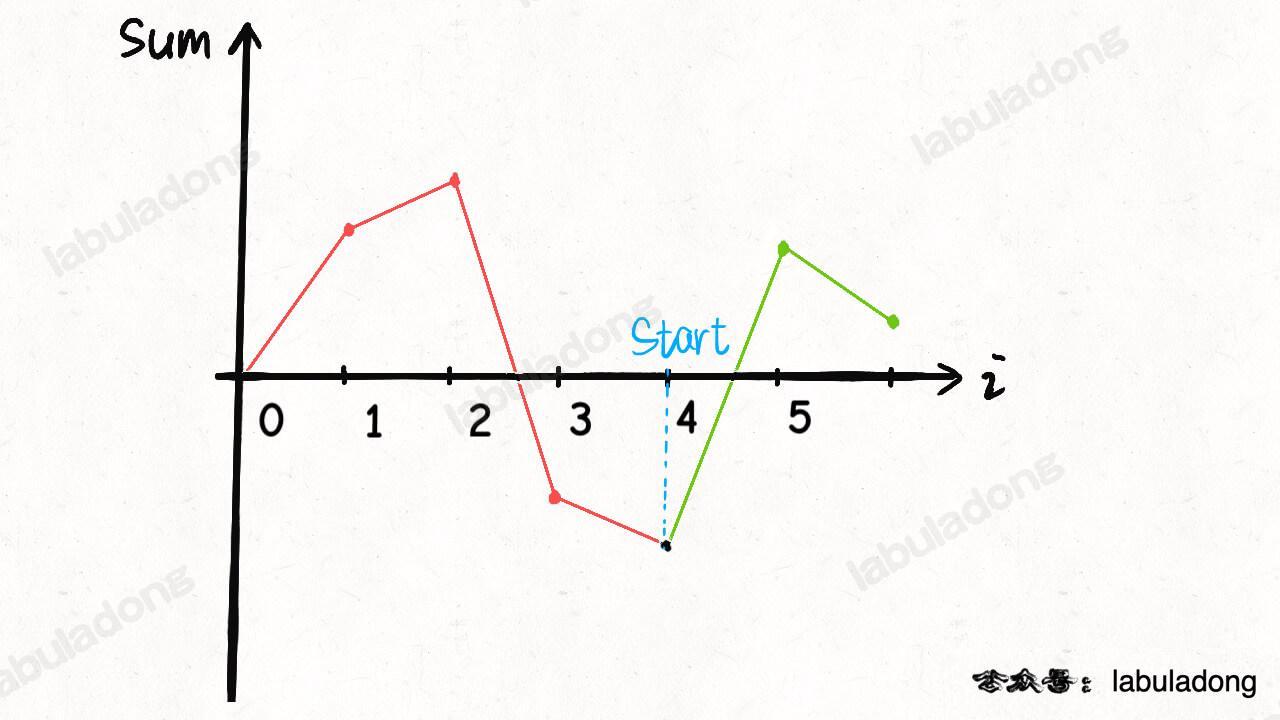
如果把这个「最低点」作为起点,就是说将这个点作为坐标轴原点,就相当于把图像「最大限度」向上平移了。
再加上这个数组是环形数组,最低点左侧的图像可以接到图像的最右侧:
这样,整个图像都保持在 x 轴以上,所以这个最低点 4,就是题目要求我们找的起点。
不过,经过平移后图像一定全部在 x 轴以上吗?不一定,因为还有无解的情况:
如果 sum(gas[...]) < sum(cost[...]),总油量小于总的消耗,那肯定是没办法环游所有站点的。
综上,我们就可以写出代码:
class Solution {
public:
int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {
int n = gas.size();
// 相当于图像中的坐标点和最低点
int sum = 0, minSum = 0;
int start = 0;
for (int i = 0; i < n; i++) {
sum += gas[i] - cost[i];
if (sum < minSum) {
// 经过第 i 个站点后,使 sum 到达新低
// 所以站点 i + 1 就是最低点(起点)
start = i + 1;
minSum = sum;
}
}
if (sum < 0) {
// 总油量小于总的消耗,无解
return -1;
}
// 环形数组特性
return start == n ? 0 : start;
}
};
以上是观察函数图像得出的解法,时间复杂度为 O(N),比暴力解法的效率高很多。
贪心算法
用贪心思路解决这道题的关键在于以下这个结论:
如果选择站点 i 作为起点「恰好」无法走到站点 j,那么 i 和 j 中间的任意站点 k 都不可能作为起点。
比如说,如果从站点 1 出发,走到站点 5 时油箱中的油量「恰好」减到了负数,那么说明站点 1「恰好」无法到达站点 5;那么你从站点 2,3,4 任意一个站点出发都无法到达 5,因为到达站点 5 时油箱的油量也必然被减到负数。
如何证明这个结论?
假设 tank 记录当前油箱中的油量,如果从站点 i 出发(tank = 0),走到 j 时恰好出现 tank < 0 的情况,那说明走到 i, j 之间的任意站点 k 时都满足 tank > 0,对吧。
如果把 k 作为起点的话,相当于在站点 k 时 tank = 0,那走到 j 时必然有 tank < 0,也就是说 k 肯定不能是起点。
拜托,从 i 出发走到 k 好歹 tank > 0,都无法达到 j,现在你还让 tank = 0 了,那更不可能走到 j 了对吧。
综上,这个结论就被证明了。
回想一下我们开头说的暴力解法是怎么做的?
如果我发现从 i 出发无法走到 j,那么显然 i 不可能是起点。
现在,我们发现了一个新规律,可以推导出什么?
如果我发现从 i 出发无法走到 j,那么 i 以及 i, j 之间的所有站点都不可能作为起点。
看到冗余计算了吗?看到优化的点了吗?
这就是贪心思路的本质,如果找不到重复计算,那就通过问题中一些隐藏较深的规律,来减少冗余计算。
根据这个结论,就可以写出如下代码:
class Solution {
public:
int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {
int n = gas.size();
int sum = 0;
for (int i = 0; i < n; i++) {
sum += gas[i] - cost[i];
}
if (sum < 0) {
// 总油量小于总的消耗,无解
return -1;
}
// 记录油箱中的油量
int tank = 0;
// 记录起点
int start = 0;
for (int i = 0; i < n; i++) {
tank += gas[i] - cost[i];
if (tank < 0) {
// 无法从 start 到达 i + 1
// 所以站点 i + 1 应该是起点
tank = 0;
start = i + 1;
}
}
return start == n ? 0 : start;
}
};
这个解法的时间复杂度也是 O(N),和之前图像法的解题思路有所不同,但代码非常类似。
其实,你可以把这个解法的思路结合图像来思考,可以发现它们本质上是一样的,只是理解方式不同而已。
对于这种贪心算法,没有特别套路化的思维框架,主要还是靠多做题多思考,将题目的场景进行抽象的联想,找出隐藏其中的规律,从而减少计算量,进行效率优化。