DFS算法的若干疑难点
回溯算法和DFS算法有何区别
回溯算法框架
void backtrack(...) {
if (到达叶子节点) {
return;
}
for (int i = 0, i < n; i++) {
// 做选择
...
backtrack(...)
// 撤销选择
...
}
}
// 关注树枝
DFS算法框架
void dfs(...) {
if (到达叶子节点) {
return;
}
// 做选择
...
for (int i = 0, i < n; i++) {
dfs(...)
}
// 撤销选择
...
}
// 关注节点
我们以多叉树的遍历为例子
// 回溯算法
void backtrack(Node root) {
if (root == null) {
return;
}
for (Node child : root->children) {
// 做选择
printf("我在 %s 和 %s 中间的树枝上做选择", root, child);
backtrack(child);
// 撤销选择
printf("我在 %s 和 %s 中间的树枝上撤销选择", root, child);
}
}
// DFS算法
void backtrack(Node root) {
if (root == null) {
return;
}
for (Node child : root->children) {
// 做选择
printf("我在 %s 和 %s 中间的树枝上做选择", root, child);
backtrack(child);
// 撤销选择
printf("我在 %s 和 %s 中间的树枝上撤销选择", root, child);
}
}
所以你说它俩有啥本质区别么?其实没有。无非就是按照题目的需求,我们灵活运用罢了。
那么对于排列组合这种经典问题,它们的关注点显然就是在树枝上的.

图中的数字,为啥画在树枝上而不是节点上?因为你在穷举排列组合的时候,就是在树枝位置做选择(往 track 里面添加的元素),节点中反映的是你此次选择的结果(track 的状态).
backtrack/dfs/traverse函数可以有返回值吗?
理论上你随意,但是我强烈建议,对于
backtrack/dfs/traverse函数,就作为单纯的遍历函数,请保持 void 类型,不要给它们带返回值。给这种遍历函数加返回值是为了提前终止递归,但有更清晰的方法做到这一点。
递归算法主要有两种思维模式,一种是「遍历」的思维,一种是「分解问题」的思维。
分解问题的思维模式大概率是有返回值的,因为要根据子问题的结果来计算当前问题的结果。这种函数的名字我们一般也要取得有意义,比如 int maxDepth(TreeNode root),一眼就能看出来这个函数的返回值是什么含义。
而遍历的思维模式,我们习惯上就会创建一个名为 backtrack/dfs/traverse 的函数,它本身只起到遍历多叉树的作用,简单明了。如果再搅合进去一个返回值,意思是你这个函数有特殊的定义?那么请问你的思路到底是遍历还是分解问题?功力不到位的话,很容易把自己绕进去,写着写着自己都不知道这个返回值该咋用了。
当题目只让你寻找一个合法答案时,建议保持遍历函数的 void 类型,用外部变量来控制递归的终止。
base case和剪枝应该写在哪里
把能提到函数开头的判断逻辑都提到函数开头,因为递归部分是填写前中后序代码的位置,尽量不要和 base case 的逻辑混到一起,否则容易混乱。
void traverse(TreeNode root) {
// base case
if (root == null) {
return;
}
// 前序位置
traverse(root.left);
// 中序位置
traverse(root.right);
// 后序位置
}
书写回溯算法的时候,会习惯把剪枝逻辑放在递归之前,类似这样:
void backtrack(...) {
// base case
if (到达叶子节点) {
return;
}
for (int i = 0, i < n; i++) {
// 剪枝逻辑
if (第 i 个选择不满足条件) {
continue;
}
// 做选择
...
backtrack(...)
// 撤销选择
...
}
}
回溯算法最佳实践:解数独
算法的核心思路非常非常的简单,就是对每一个空着的格子穷举 1 到 9,如果遇到不合法的数字(在同一行或同一列或同一个 3×3 的区域中存在相同的数字)则跳过,如果找到一个合法的数字,则继续穷举下一个空格子。
对于数独游戏,也许我们还会有另一个误区:就是下意识地认为如果给定的数字越少那么这个局面的难度就越大。
这个结论对人来说应该没毛病,但对于计算机而言,给的数字越少,反而穷举的步数就越少,得到答案的速度越快,至于为什么,我们后面探讨代码实现的时候会讲。
代码实现
题目
输入是一个9x9的棋盘,空白格子用点号字符 . 表示,算法需要在原地修改棋盘,将空白格子填上数字,得到一个可行解。
至于数独的要求,每行,每列以及每一个 3×3 的小方格都不能有相同的数字出现。
思路
求解数独的思路很简单粗暴,就是对每一个格子所有可能的数字进行穷举。对于每个位置,应该如何穷举,有几个选择呢?
很简单啊,从 1 到 9 就是选择,全部试一遍不就行了:
void backtrack(char board[9][9], int i, int j) {
int m = 9, n = 9;
for (char ch = '1'; ch <= '9'; ch++) {
// 做选择
board[i][j] = ch;
// 继续穷举下一个
backtrack(board, i, j + 1);
// 撤销选择
board[i][j] = '.';
}
}
再继续细化,并不是 1 到 9 都可以取到的,有的数字不是不满足数独的合法条件吗?而且现在只是给 j 加一,那如果 j 加到最后一列了,怎么办?
很简单,当 j 到达超过每一行的最后一个索引时,转为增加 i 开始穷举下一行,并且在穷举之前添加一个判断,跳过不满足条件的数字:
class Solution {
public:
void backtrack(vector<vector<char>>& board, int i, int j) {
int m = 9, n = 9;
if (j == n) {
// 穷举到最后一列的话就换到下一行重新开始。
backtrack(board, i + 1, 0);
return;
}
// 如果该位置是预设的数字,不用我们操心
if (board[i][j] != '.') {
backtrack(board, i, j + 1);
return;
}
for (char ch = '1'; ch <= '9'; ch++) {
// 如果遇到不合法的数字,就跳过
if (!isValid(board, i, j, ch))
continue;
board[i][j] = ch;
backtrack(board, i, j + 1);
board[i][j] = '.';
}
}
// 判断 board[i][j] 是否可以填入 n
bool isValid(vector<vector<char>>& board, int r, int c, char n) {
for (int i = 0; i < 9; i++) {
// 判断行是否存在重复
if (board[r][i] == n) return false;
// 判断列是否存在重复
if (board[i][c] == n) return false;
// 判断 3 x 3 方框是否存在重复
if (board[(r/3)*3 + i/3][(c/3)*3 + i%3] == n)
return false;
}
return true;
}
};
还剩最后一个问题:这个算法没有 base case,永远不会停止递归。这个好办,什么时候结束递归?显然 r == m 的时候就说明穷举完了最后一行,完成了所有的穷举,就是 base case。
另外,前文也提到过,为了减少复杂度,我们可以让 backtrack 函数返回值为 boolean,如果找到一个可行解就返回 true,这样就可以阻止后续的递归。只找一个可行解,也是题目的本意。
class Solution {
public:
bool backtrack(vector<vector<char>>& board, int i, int j) {
int m = 9, n = 9;
if (j == n) {
// 穷举到最后一列的话就换到下一行重新开始。
return backtrack(board, i + 1, 0);
}
if (i == m) {
// 找到一个可行解,触发 base case
return true;
}
if (board[i][j] != '.') {
// 如果有预设数字,不用我们穷举
return backtrack(board, i, j + 1);
}
for (char ch = '1'; ch <= '9'; ch++) {
// 如果遇到不合法的数字,就跳过
if (!isValid(board, i, j, ch))
continue;
board[i][j] = ch;
// 如果找到一个可行解,立即结束
if (backtrack(board, i, j + 1)) {
return true;
}
board[i][j] = '.';
}
// 穷举完 1~9,依然没有找到可行解,此路不通
return false;
}
bool isValid(vector<vector<char>>& board, int r, int c, char n) {
// 见上文
}
};
现在可以回答一下之前的问题,为什么有时候算法执行的次数多,有时候少?为什么对于计算机而言,确定的数字越少,反而算出答案的速度越快?
我们已经实现了一遍算法,掌握了其原理,回溯就是从 1 开始对每个格子穷举,最后只要试出一个可行解,就会立即停止后续的递归穷举。所以暴力试出答案的次数和随机生成的棋盘关系很大,这个是说不准的。
那么你可能问,既然运行次数说不准,那么这个算法的时间复杂度是多少呢?
对于这种时间复杂度的计算,我们只能给出一个最坏情况,也就是 O(9^M),其中 M 是棋盘中空着的格子数量。你想嘛,对每个空格子穷举 9 个数,结果就是指数级的。
这个复杂度非常高,但稍作思考就能发现,实际上我们并没有真的对每个空格都穷举 9 次,有的数字会跳过,有的数字根本就没有穷举,因为当我们找到一个可行解的时候就立即结束了,后续的递归都没有展开。
这个 O(9^M) 的复杂度实际上是完全穷举,或者说是找到所有可行解的时间复杂度。
如果给定的数字越少,相当于给出的约束条件越少,对于计算机这种穷举策略来说,是更容易进行下去,而不容易走回头路进行回溯的,所以说如果仅仅找出一个可行解,这种情况下穷举的速度反而比较快。
回溯算法实践:括号生成
括号问题可以简单分成两类,一类是的 括号的合法性判断 ,一类是 合法括号 的生成。对于括号合法性的判断,主要是借助「栈」这种数据结构,而对于括号的生成,一般都要利用 [回溯算法] 进行暴力穷举。
题目
请你写一个算法,输入是一个正整数 n,输出是 n 对括号的所有合法组合,函数签名如下:
比如说,输入 n=3,输出为如下 5 个字符串:
"((()))",
"(()())",
"(())()",
"()(())",
"()()()"
思路
有关括号问题,你只要记住以下性质,思路就很容易想出来:
- 一个「合法」括号组合的左括号数量一定等于右括号数量,这个很好理解。
- 对于一个「合法」的括号字符串组合
p,必然对于任何0 <= i < len(p)都有:子串p[0..i]中左括号的数量都大于或等于右括号的数量。
稍微想一下,其实很容易理解,因为从左往右算的话,肯定是左括号多嘛,到最后左右括号数量相等,说明这个括号组合是合法的。反之,比如这个括号组合 ))((,前几个子串都是右括号多于左括号,显然不是合法的括号组合。
回溯思路
算法输入一个整数 n,让你计算 n 对儿括号能组成几种合法的括号组合,可以改写成如下问题:
现在有 2n 个位置,每个位置可以放置字符 ( 或者 ),组成的所有括号组合中,有多少个是合法的?
这个命题和题目的意思完全是一样的对吧,那么我们先想想如何得到全部 2^(2n) 种组合,然后再根据我们刚才总结出的合法括号组合的性质筛选出合法的组合,不就完事儿了?
#include <string>
#include <vector>
#include <iostream>
std::vector<std::string> track;
void print(const std::vector<std::string>& v) {
for (const std::string& s : v) {
std::cout << s;
}
std::cout << std::endl;
}
void backtrack(int n, int i) {
// i 代表当前的位置,共 2n 个位置
// 穷举到最后一个位置了,得到一个长度为 2n 组合
if (i == 2 * n) {
print(track);
return;
}
// 对于每个位置可以是左括号或者右括号两种选择
for (std::string choice : {"(", ")"}) {
track.push_back(choice); // 做选择
// 穷举下一个位置
backtrack(n, i + 1);
track.pop_back(); // 撤销选择
}
}
那么,现在能够打印所有括号组合了,如何从它们中筛选出合法的括号组合呢?很简单,加几个条件进行「剪枝」就行了。
对于 2n 个位置,必然有 n 个左括号,n 个右括号,所以我们不是简单的记录穷举位置 i,而是用 left 记录还可以使用多少个左括号,用 right 记录还可以使用多少个右括号,这样就可以通过刚才总结的合法括号规律进行筛选了:
class Solution {
private:
// 回溯过程中的路径
string track = "";
// 记录所有合法的括号组合
vector<string> res;
public:
vector<string> generateParenthesis(int n) {
if (n == 0) return res;
// 可用的左括号和右括号数量初始化为 n
backtrack(n, n);
return res;
}
// 可用的左括号数量为 left 个,可用的右括号数量为 right 个
void backtrack(int left, int right) {
// 若左括号剩下的多,说明不合法
if (right < left) return;
// 数量小于 0 肯定是不合法的
if (left < 0 || right < 0) return;
// 当所有括号都恰好用完时,得到一个合法的括号组合
if (left == 0 && right == 0) {
res.push_back(track);
return;
}
// 做选择,尝试放一个左括号
track.push_back('(');
backtrack(left - 1, right);
// 撤消选择
track.pop_back();
// 做选择,尝试放一个右括号
track.push_back(')');
backtrack(left, right - 1);
// 撤销选择
track.pop_back();
}
};
这样,我们的算法就完成了,算法的复杂度是多少呢?这个比较难分析,对于递归相关的算法,时间复杂度这样计算(递归次数)*(递归函数本身的时间复杂度)。
backtrack 就是我们的递归函数,其中没有任何 for 循环代码,所以递归函数本身的时间复杂度是 O(1),但关键是这个函数的递归次数是多少?换句话说,给定一个 n,backtrack 函数递归被调用了多少次?
我们前面怎么分析动态规划算法的递归次数的?主要是看「状态」的个数对吧。
所以说这里也可以用「状态」这个概念,对于 backtrack 函数,状态有三个,分别是 left, right, track,这三个变量的所有组合个数就是 backtrack 函数的状态个数(调用次数)。
left 和 right 的组合好办,他俩取值就是 0~n 嘛,组合起来也就 n^2 种而已;这个 track 的长度虽然取在 0~2n,但对于每一个长度,它还有指数级的括号组合,这个是不好算的。
说了这么多,就是想让大家知道这个算法的复杂度是指数级,而且不好算,这里就不具体展开了,是 4^n / sqrt(n)
回溯算法实践:集合划分
题目
给你输入一个数组 nums 和一个正整数 k,请你判断 nums 是否能够被平分为元素和相同的 k 个子集。
思路
回到正题,这道算法题让我们求子集划分,子集问题和排列组合问题有所区别,但我们可以借鉴「球盒模型」的抽象,用两种不同的视角来解决这道子集划分问题。
把装有 n 个数字的数组 nums 分成 k 个和相同的集合,你可以想象将 n 个数字分配到 k 个「桶」里,最后这 k 个「桶」里的数字之和要相同。
视角一,如果我们切换到这 n 个数字的视角,每个数字都要选择进入到 k 个桶中的某一个。

视角二,如果我们切换到这 k 个桶的视角,对于每个桶,都要遍历 nums 中的 n 个数字,然后选择是否将当前遍历到的数字装进自己这个桶里。
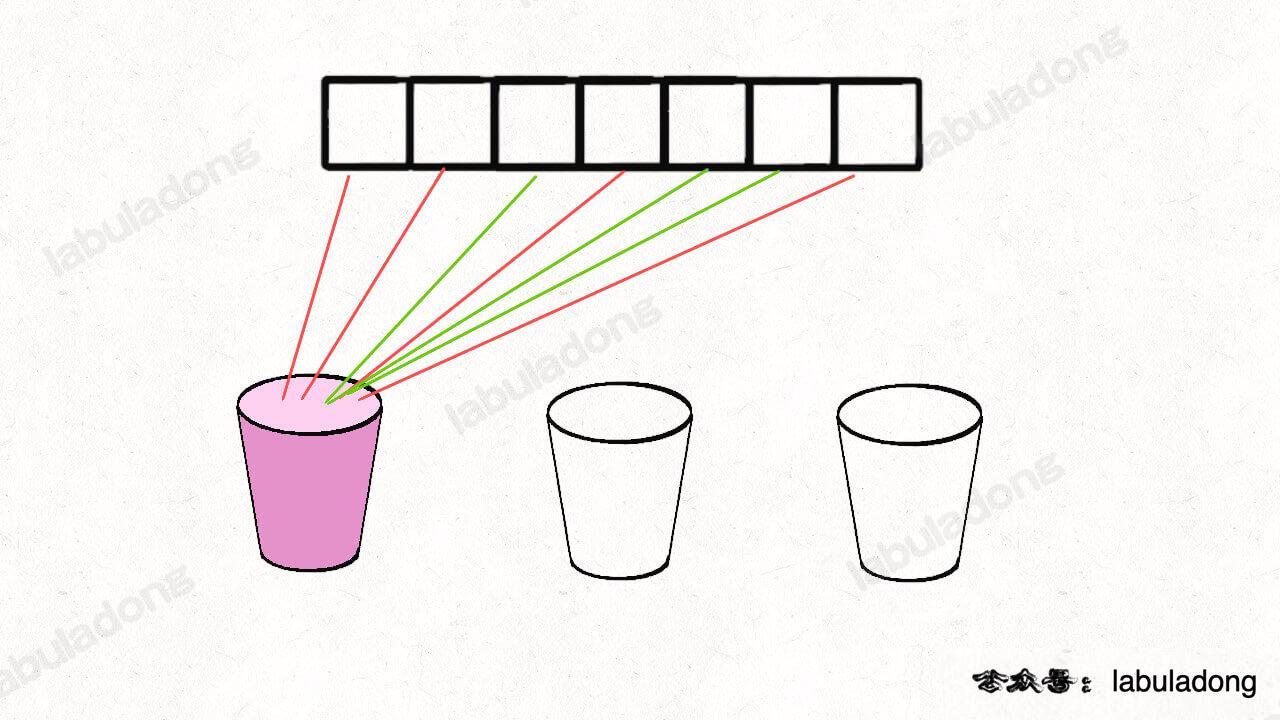
用不同的视角进行穷举,虽然结果相同,但是解法代码的逻辑不同,具体的代码实现也不同,可能产生不同的时间、空间复杂度。我们需要选择复杂度更低的解法。
以数字的视角
以数字的视角,选择 k 个桶
// for 循环形式
// k 个桶(集合),记录每个桶装的数字之和
int bucket[k] = {0};
// 穷举 nums 中的每个数字
for(int index = 0; index < nums.size(); index++) {
// 穷举每个桶
for(int i = 0; i < k; i++) {
// nums[index] 选择是否要进入第 i 个桶
// ...
}
}
// 递归形式
// k 个桶(集合),记录每个桶装的数字之和
int bucket[k];
// 穷举 nums 中的每个数字
void backtrack(int nums[], int index) {
// base case
if (index == sizeof(nums)/sizeof(nums[0])) {
return;
}
// 穷举每个桶
for (int i = 0; i < sizeof(bucket)/sizeof(bucket[0]); i++) {
// 选择装进第 i 个桶
bucket[i] += nums[index];
// 递归穷举下一个数字的选择
backtrack(nums, index + 1);
// 撤销选择
bucket[i] -= nums[index];
}
}
完整代码
class Solution {
public:
bool canPartitionKSubsets(vector<int>& nums, int k) {
// 排除一些基本情况
if (k > nums.size()) return false;
int sum = 0;
for (int v : nums) sum += v;
if (sum % k != 0) return false;
// k 个桶(集合),记录每个桶装的数字之和
vector<int> bucket(k, 0);
// 理论上每个桶(集合)中数字的和
int target = sum / k;
// 穷举,看看 nums 是否能划分成 k 个和为 target 的子集
return backtrack(nums, 0, bucket, target);
}
// 递归穷举 nums 中的每个数字
bool backtrack(vector<int>& nums, int index, vector<int>& bucket, int target) {
if (index == nums.size()) {
// 检查所有桶的数字之和是否都是 target
for (int i = 0; i < bucket.size(); i++) {
if (bucket[i] != target) {
return false;
}
}
// nums 成功平分成 k 个子集
return true;
}
// 穷举 nums[index] 可能装入的桶
for (int i = 0; i < bucket.size(); i++) {
// 剪枝,桶装装满了
if (bucket[i] + nums[index] > target) {
continue;
}
// 将 nums[index] 装入 bucket[i]
bucket[i] += nums[index];
// 递归穷举下一个数字的选择
if (backtrack(nums, index + 1, bucket, target)) {
return true;
}
// 撤销选择
bucket[i] -= nums[index];
}
// nums[index] 装入哪个桶都不行
return false;
}
};
其实我们可以再做一个优化。
如果我们让尽可能多的情况命中剪枝的那个 if 分支,就可以减少递归调用的次数,一定程度上减少时间复杂度。
如何尽可能多的命中这个 if 分支呢?要知道我们的 index 参数是从 0 开始递增的,也就是递归地从 0 开始遍历 nums 数组。
如果我们提前对 nums 数组排序,把大的数字排在前面,那么大的数字会先被分配到 bucket 中,对于之后的数字,bucket[i] + nums[index] 会更大,更容易触发剪枝的 if 条件。
所以可以在之前的代码中再添加一些代码:
bool canPartitionKSubsets(vector<int>& nums, int k) {
// 其他代码不变
// ...
/* 降序排序 nums 数组 */
sort(nums.begin(), nums.end(), greater<int>());
/*******************/
return backtrack(nums, 0, bucket, target);
}
这个解法可以得到正确答案,但耗时比较多,已经无法通过所有测试用例了,接下来看看另一种视角的解法。
以桶的视角
以桶的视角进行穷举,每个桶需要遍历 nums 中的所有数字,决定是否把当前数字装进桶中;当装满一个桶之后,还要装下一个桶,直到所有桶都装满为止。
// 装满所有桶为止
while (k > 0) {
// 记录当前桶中的数字之和
int bucket = 0;
for (int i = 0; i < nums.size(); i++) {
// 决定是否将 nums[i] 放入当前桶中
if (canAdd(bucket, nums[i])) {
bucket += nums[i];
}
if (bucket == target) {
// 装满了一个桶,装下一个桶
k--;
break;
}
}
}
那么我们也可以把这个 while 循环改写成递归函数,不过比刚才略微复杂一些,首先写一个 backtrack 递归函数出来:
bool backtrack(int k, int bucket, int nums[], int start, bool used[], int target);
这个 backtrack 函数的参数可以这样解释:
现在 k 号桶正在思考是否应该把 nums[start] 这个元素装进来;目前 k 号桶里面已经装的数字之和为 bucket;used 标志某一个元素是否已经被装到桶中;target 是每个桶需要达成的目标和。
根据这个函数定义,可以这样调用 backtrack 函数:
// 递归 + 回溯算法
bool backtrack(int k, int index, vector<int>& nums, int curSum, vector<bool>& used, int target) {
if (k == 0) return true; // 成功地找到 k 个子集
if (curSum == target) { // 当前子集的和达到目标
return backtrack(k - 1, 0, nums, 0, used, target); // 去寻找下一个子集
}
// 从 index 开始遍历 nums 数组,寻找满足条件的下一个数
for (int i = index; i < nums.size(); i++) {
if (used[i]) continue; // 如果已经被使用,则跳过此数
if (curSum + nums[i] > target) continue; // 如果加入此数超出当前承载能力,则跳过此数
used[i] = true; // 标记此数已经被使用
if (backtrack(k, i + 1, nums, curSum + nums[i], used, target)) return true; // 递归查找下一个数
used[i] = false; // 如果当前使用的方案不能达到要求,则回退操作
}
return false;
}
bool canPartitionKSubsets(vector<int>& nums, int k) {
if (k > nums.size()) return false; // 排除基本情况
int sum = accumulate(nums.begin(), nums.end(), 0); // 计算数组 nums 的总和
if (sum % k != 0) return false; // 如果无法整除,则不能分割成 k 个子集
vector<bool> used(nums.size(), false); // 标记数组 nums 中的数字是否已经被使用
int target = sum / k; // 计算每个子集的目标和
return backtrack(k, 0, nums, 0, used, target);
}
实现 backtrack 函数的逻辑之前,再重复一遍,从桶的视角:
1、需要遍历 nums 中所有数字,决定哪些数字需要装到当前桶中。
2、如果当前桶装满了(桶内数字和达到 target),则让下一个桶开始执行第 1 步。
下面的代码就实现了这个逻辑:
bool backtrack(int k, int bucket,
vector<int>& nums, int start, vector<bool>& used, int target) {
// base case
if (k == 0) {
// 所有桶都被装满了,而且 nums 一定全部用完了
// 因为 target == sum / k
return true;
}
if (bucket == target) {
// 装满了当前桶,递归穷举下一个桶的选择
// 让下一个桶从 nums[0] 开始选数字
return backtrack(k - 1, 0 ,nums, 0, used, target);
}
// 从 start 开始向后探查有效的 nums[i] 装入当前桶
for (int i = start; i < nums.size(); i++) {
// 剪枝
if (used[i]) {
// nums[i] 已经被装入别的桶中
continue;
}
if (nums[i] + bucket > target) {
// 当前桶装不下 nums[i]
continue;
}
// 做选择,将 nums[i] 装入当前桶中
used[i] = true;
bucket += nums[i];
// 递归穷举下一个数字是否装入当前桶
if (backtrack(k, bucket, nums, i + 1, used, target)) {
return true;
}
// 撤销选择
used[i] = false;
bucket -= nums[i];
}
// 穷举了所有数字,都无法装满当前桶
return false;
}
这段代码是可以得出正确答案的,但是效率很低,我们可以思考一下是否还有优化的空间。
首先,在这个解法中每个桶都可以认为是没有差异的,但是我们的回溯算法却会对它们区别对待,这里就会出现重复计算的情况。
什么意思呢?我们的回溯算法,说到底就是穷举所有可能的组合,然后看是否能找出和为 target 的 k 个桶(子集)。
那么,比如下面这种情况,target = 5,算法会在第一个桶里面装 1, 4:

现在第一个桶装满了,就开始装第二个桶,算法会装入 2, 3:
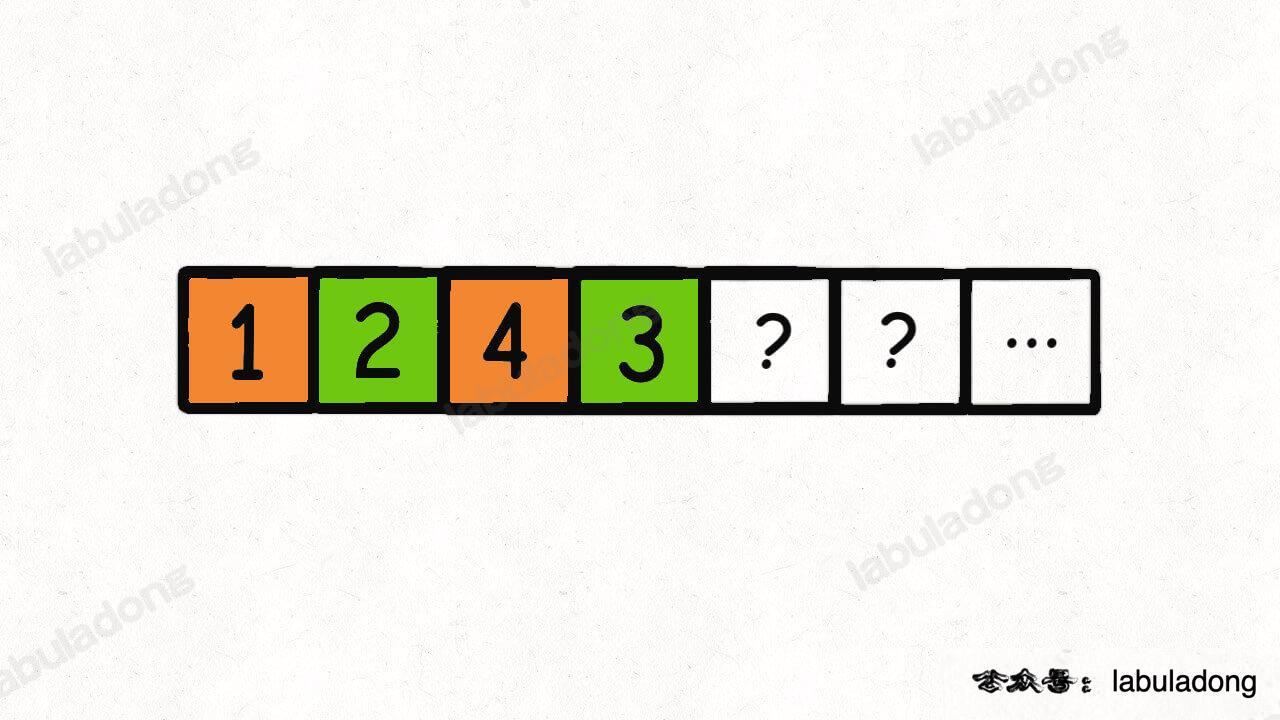
然后以此类推,对后面的元素进行穷举,凑出若干个和为 5 的桶(子集)。
但问题是,如果最后发现无法凑出和为 target 的 k 个子集,算法会怎么做?
回溯算法会回溯到第一个桶,重新开始穷举,现在它知道第一个桶里装 1, 4 是不可行的,它会尝试把 2, 3 装到第一个桶里:

现在第一个桶装满了,就开始装第二个桶,算法会装入 1, 4:
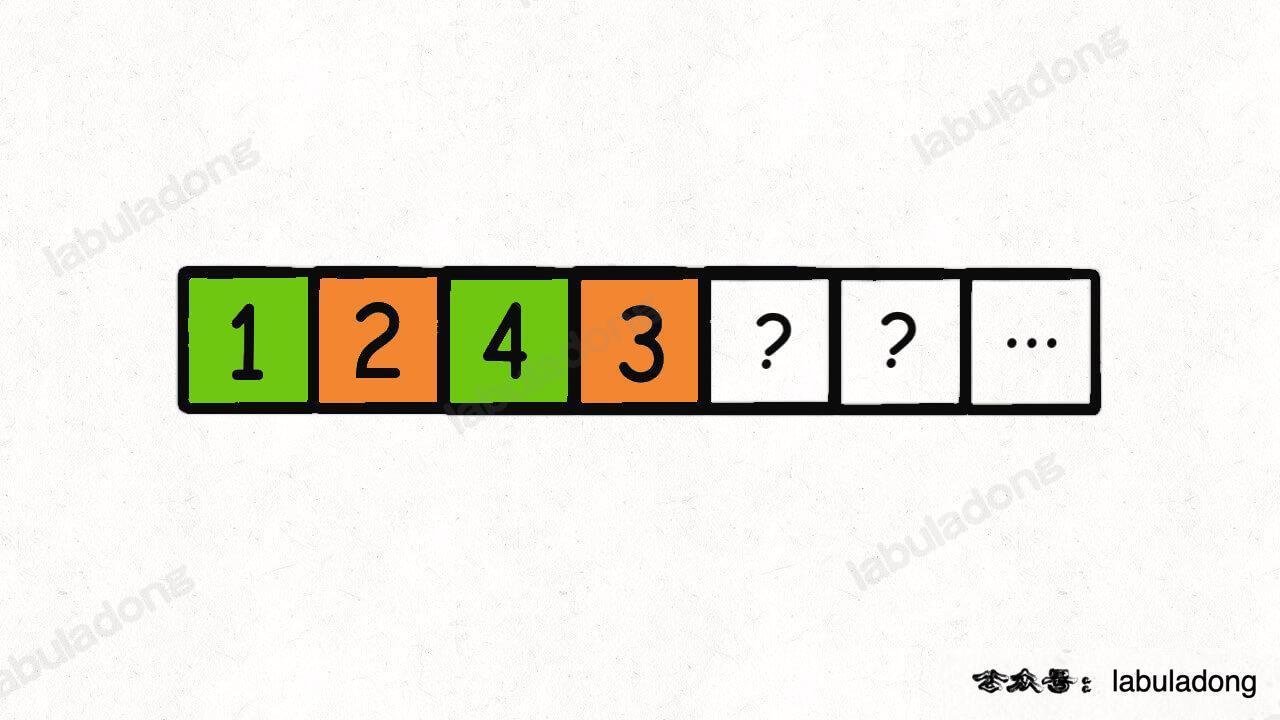
好,到这里你应该看出来问题了,这种情况其实和之前的那种情况是一样的。也就是说,到这里你其实已经知道不需要再穷举了,必然凑不出来和为 target 的 k 个子集。
但我们的算法还是会傻乎乎地继续穷举,因为在她看来,第一个桶和第二个桶里面装的元素不一样,那这就是两种不一样的情况呀。
那么我们怎么让算法的智商提高,识别出这种情况,避免冗余计算呢?
你注意这两种情况的 used 数组肯定长得一样,所以 used 数组可以认为是回溯过程中的「状态」。
所以,我们可以用一个 memo 备忘录,在装满一个桶时记录当前 used 的状态,如果当前 used 的状态是曾经出现过的,那就不用再继续穷举,从而起到剪枝避免冗余计算的作用。
有读者肯定会问,used 是一个布尔数组,怎么作为键进行存储呢?这其实是小问题,比如我们可以把数组转化成字符串,这样就可以作为哈希表的键进行存储了。
看下代码实现,只要稍微改一下 backtrack 函数即可:
// 备忘录,存储 used 数组的状态
std::unordered_map<std::string, bool> memo;
bool backtrack(int k, int bucket, std::vector<int>& nums, int start, std::vector<bool>& used, int target) {
// base case
if (k == 0) {
return true;
}
// 将 used 的状态转化成形如 [true, false, ...] 的字符串
// 便于存入 unordered_map
std::string state = "";
for(auto val: used) // convert vector to string
state += (val) ? "true," : "false,";
if (bucket == target) {
// 装满了当前桶,递归穷举下一个桶的选择
bool res = backtrack(k - 1, 0, nums, 0, used, target);
// 将当前状态和结果存入备忘录
memo[state] = res;
return res;
}
if (memo.count(state)) {
// 如果当前状态曾今计算过,就直接返回,不要再递归穷举了
return memo[state];
}
// 其他逻辑不变...
}
这样提交解法,发现执行效率依然比较低,这次不是因为算法逻辑上的冗余计算,而是代码实现上的问题。
因为每次递归都要把 used 数组转化成字符串,这对于编程语言来说也是一个不小的消耗,所以我们还可以进一步优化。
注意题目给的数据规模 nums.length <= 16,也就是说 used 数组最多也不会超过 16,那么我们完全可以用「位图」的技巧,用一个 int 类型的 used 变量来替代 used 数组。
具体来说,我们可以用整数 used 的第 i 位((used >> i) & 1)的 1/0 来表示 used[i] 的 true/false。
这样一来,不仅节约了空间,而且整数 used 也可以直接作为键存入 HashMap,省去数组转字符串的消耗。
看下最终的解法代码:
class Solution {
public:
unordered_map<int, bool> memo; //备忘录
bool backtrack(int k, int bucket, vector<int>& nums, int start, int used, int target) {
if (k == 0) {
// 所有桶都被装满了,而且 nums 一定全部用完了
return true;
}
if (bucket == target) {
// 装满了当前桶,递归穷举下一个桶的选择
// 让下一个桶从 nums[0] 开始选数字
bool res = backtrack(k - 1, 0, nums, 0, used, target);
// 缓存结果
memo[used] = res;
return res;
}
if (memo.count(used)) {
// 避免冗余计算
return memo[used];
}
for (int i = start; i < nums.size(); i++) {
// 剪枝
if ((used >> i) & 1 == 1) { // 判断第 i 位是否是 1
// nums[i] 已经被装入别的桶中
continue;
}
if (nums[i] + bucket > target) {
// 装不下,剪枝
continue;
}
// 做选择
used |= 1 << i; // 将第 i 位置为 1
bucket += nums[i];
// 递归穷举下一个数字是否装入当前桶
if (backtrack(k, bucket, nums, i + 1, used, target)) {
return true;
}
// 撤销选择
used ^= 1 << i; // 使用异或运算将第 i 位恢复 0
bucket -= nums[i];
}
return false;
}
bool canPartitionKSubsets(vector<int>& nums, int k) {
// 排除一些基本情况
if (k > nums.size()) return false;
int sum = 0;
for (int v : nums) sum += v;
if (sum % k != 0) {
// 不能整除,提前退出
return false;
}
int used = 0; // 使用位图技巧,记录每个元素是否被选择过
int target = sum / k;
// k 号桶初始什么都没装,从 nums[0] 开始做选择
return backtrack(k, 0, nums, 0, used, target);
}
};
总结
我们来分析一下这两个算法的时间复杂度,假设 nums 中的元素个数为 n。
先说第一个解法,也就是从数字的角度进行穷举,n 个数字,每个数字有 k 个桶可供选择,所以组合出的结果个数为 k^n,时间复杂度也就是 O(k^n)。
第二个解法,每个桶要遍历 n 个数字,对每个数字有「装入」或「不装入」两种选择,所以组合的结果有 2^n 种;而我们有 k 个桶,所以总的时间复杂度为 O(k*2^n)。
当然,这是对最坏复杂度上界的粗略估算,实际的复杂度肯定要好很多,毕竟我们添加了这么多剪枝逻辑。不过,从复杂度的上界已经可以看出第一种思路要慢很多了。
所以,谁说回溯算法没有技巧性的?虽然回溯算法就是暴力穷举,但穷举也分聪明的穷举方式和低效的穷举方式,关键看你以谁的「视角」进行穷举。
通俗来说,我们应该尽量「少量多次」,就是说宁可多做几次选择(乘法关系),也不要给太大的选择空间(指数关系);做 n 次「k 选一」仅重复一次(O(k^n)),比 n 次「二选一」重复 k 次(O(k*2^n))效率低很多。
好了,这道题我们从两种视角进行穷举,虽然代码量看起来多,但核心逻辑都是类似的,相信你通过本文能够更深刻地理解回溯算法。
BFS解决各种智力题
题目
给你一个 2x3 的滑动拼图,用一个 2x3 的数组 board 表示。拼图中有数字 0~5 六个数,其中数字 0 就表示那个空着的格子,你可以移动其中的数字,当 board 变为 [[1,2,3],[4,5,0]] 时,赢得游戏。
请你写一个算法,计算赢得游戏需要的最少移动次数,如果不能赢得游戏,返回 -1。
比如说输入的二维数组 board = [[4,1,2],[5,0,3]],算法应该返回 5:
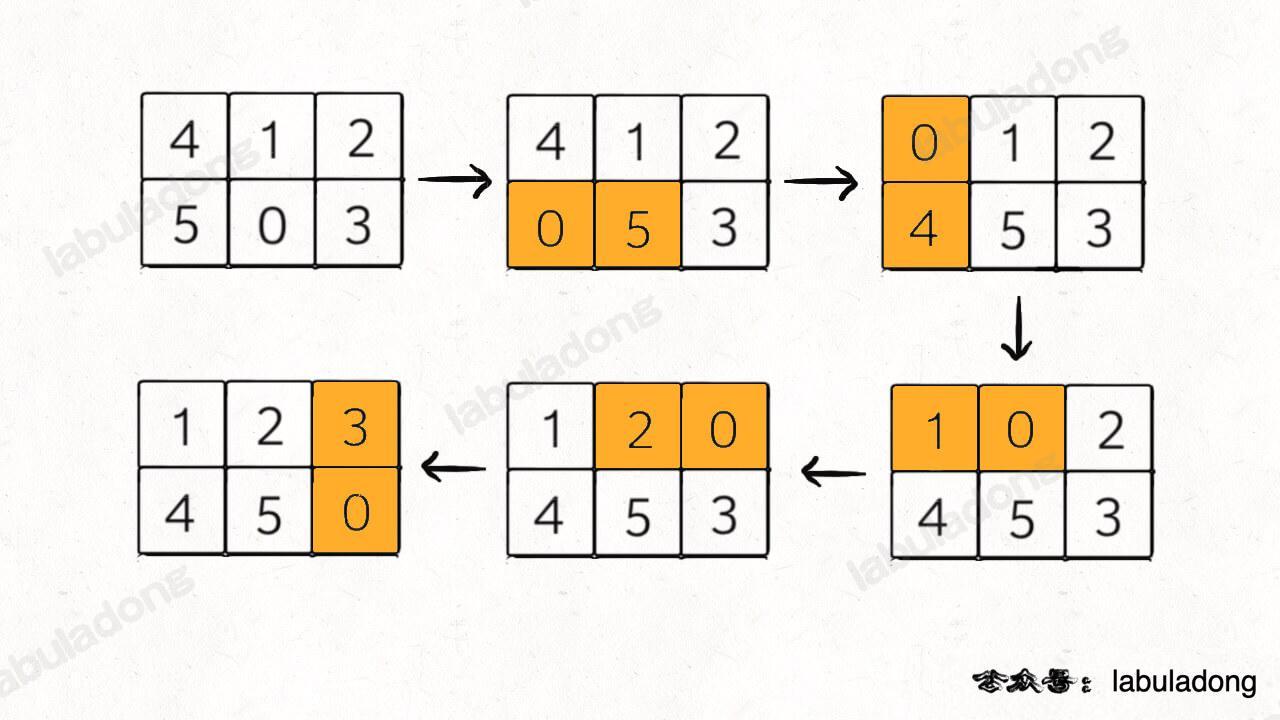
如果输入的是 board = [[1,2,3],[5,4,0]],则算法返回 -1,因为这种局面下无论如何都不能赢得游戏。
思路分析
对于这种计算最小步数的问题,我们就要敏感地想到 BFS 算法。
这个题目转化成 BFS 问题是有一些技巧的,我们面临如下问题:
1、一般的 BFS 算法,是从一个起点 start 开始,向终点 target 进行寻路,但是拼图问题不是在寻路,而是在不断交换数字,这应该怎么转化成 BFS 算法问题呢?
2、即便这个问题能够转化成 BFS 问题,如何处理起点 start 和终点 target?它们都是数组哎,把数组放进队列,套 BFS 框架,想想就比较麻烦且低效。
首先回答第一个问题,BFS 算法并不只是一个寻路算法,而是一种暴力搜索算法,只要涉及暴力穷举的问题,BFS 就可以用,而且可以最快地找到答案。
你想想计算机怎么解决问题的?哪有什么特殊技巧,本质上就是把所有可行解暴力穷举出来,然后从中找到一个最优解罢了。
明白了这个道理,我们的问题就转化成了:如何穷举出 board 当前局面下可能衍生出的所有局面?这就简单了,看数字 0 的位置呗,和上下左右的数字进行交换就行了:

这样其实就是一个 BFS 问题,每次先找到数字 0,然后和周围的数字进行交换,形成新的局面加入队列…… 当第一次到达 target 时,就得到了赢得游戏的最少步数。
对于第二个问题,我们这里的 board 仅仅是 2x3 的二维数组,所以可以压缩成一个一维字符串。其中比较有技巧性的点在于,二维数组有「上下左右」的概念,压缩成一维后,如何得到某一个索引上下左右的索引?
对于这道题,题目说输入的数组大小都是 2 x 3,所以我们可以直接手动写出来这个映射:
// 记录一维字符串的相邻索引
int neighbor[6][3] = {
{1, 3},
{0, 4, 2},
{1, 5},
{0, 4},
{3, 1, 5},
{4, 2}
};
这个含义就是,在一维字符串中,索引 i 在二维数组中的的相邻索引为 neighbor[i]:
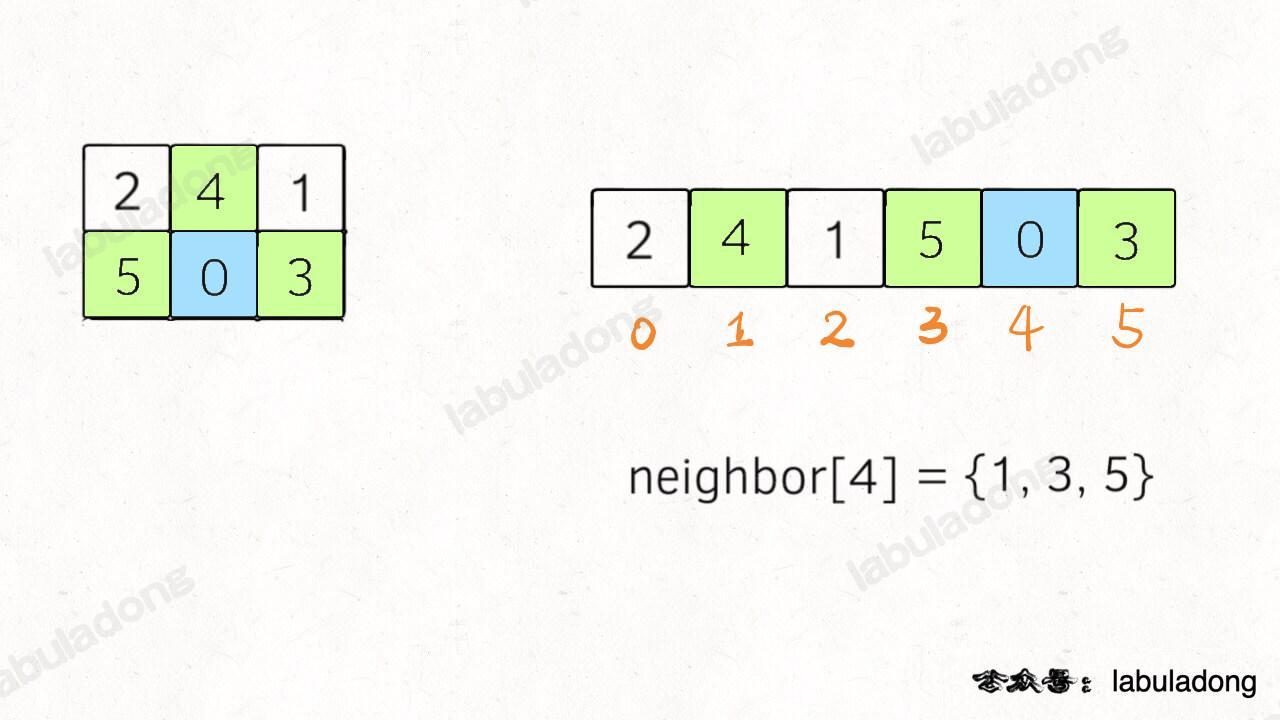
那么对于一个 m x n 的二维数组,手写它的一维索引映射肯定不现实了,如何用代码生成它的一维索引映射呢?
观察上图就能发现,如果二维数组中的某个元素 e 在一维数组中的索引为 i,那么 e 的左右相邻元素在一维数组中的索引就是 i - 1 和 i + 1,而 e 的上下相邻元素在一维数组中的索引就是 i - n 和 i + n,其中 n 为二维数组的列数。
这样,对于 m x n 的二维数组,我们可以写一个函数来生成它的 neighbor 索引映射:
vector<vector<int>> generateNeighborMapping(int m, int n) {
vector<vector<int>> neighbor(m * n);
for (int i = 0; i < m * n; i++) {
vector<int> neighbors;
// 如果不是第一列,有左侧邻居
if (i % n != 0) neighbors.push_back(i - 1);
// 如果不是最后一列,有右侧邻居
if (i % n != n - 1) neighbors.push_back(i + 1);
// 如果不是第一行,有上方邻居
if (i - n >= 0) neighbors.push_back(i - n);
// 如果不是最后一行,有下方邻居
if (i + n < m * n) neighbors.push_back(i + n);
}
return neighbor;
}
至此,我们就把这个问题完全转化成标准的 BFS 问题了,借助 [BFS 算法框架] 的代码框架,直接就可以套出解法代码了:
int slidingPuzzle(vector<vector<int>>& board) {
int m = 2, n = 3;
string target = "123450";
string start = "";
// 将 2x3 的数组转化成字符串作为 BFS 的起点
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
start += to_string(board[i][j]);
}
}
// 记录一维字符串的相邻索引
vector<vector<int>> neighbor = {
{1, 3},
{0, 4, 2},
{1, 5},
{0, 4},
{3, 1, 5},
{4, 2}
};
/******* BFS 算法框架开始 *******/
queue<string> q;
unordered_set<string> visited;
// 从起点开始 BFS 搜索
q.push(start);
visited.insert(start);
int step = 0;
while (!q.empty()) {
int sz = q.size();
for (int i = 0; i < sz; i++) {
string cur = q.front();
q.pop();
// 判断是否达到目标局面
if (target == cur) {
return step;
}
// 找到数字 0 的索引
int idx = 0;
for (; cur[idx] != '0'; idx++);
// 将数字 0 和相邻的数字交换位置
for (int adj : neighbor[idx]) {
string new_board = swap(cur, adj, idx);
// 防止走回头路
if (!visited.count(new_board)) {
q.push(new_board);
visited.insert(new_board);
}
}
}
step++;
}
/******* BFS 算法框架结束 *******/
return -1;
}
string swap(string s, int i, int j) {
char temp = s[i];
s[i] = s[j];
s[j] = temp;
return s;
}