链表算法
递归魔法:反转单链表
题目
使用递归反转一个链表
进阶:使用递归反转单链表的一部分
给你单链表的头指针 head 和两个整数 left 和 right ,其中 left <= right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。
示例 1:
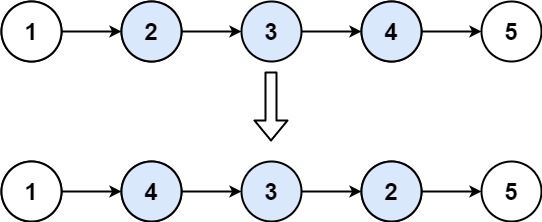
输入:head = [1,2,3,4,5], left = 2, right = 4
输出:[1,4,3,2,5]
示例 2:
输入:head = [5], left = 1, right = 1
输出:[5]
提示:
- 链表中节点数目为
n 1 <= n <= 500-500 <= Node.val <= 5001 <= left <= right <= n
进阶: 你可以使用一趟扫描完成反转吗?
注意这里的索引是从 1 开始的。迭代的思路大概是:先用一个 for 循环找到第 left 个位置,然后再用一个 for 循环将 left 和 right 之间的元素反转。但是我们的递归解法不用一个 for 循环,纯递归实现反转。
递归反转整个链表
class Solution {
public:
// 定义:输入一个单链表头结点,将该链表反转,返回新的头结点
ListNode* reverse(ListNode* head) {
if (head == nullptr || head->next == nullptr) {
return head;
}
ListNode* last = reverse(head->next);
head->next->next = head;
head->next = nullptr; // 这句话只为处理真正的head节点
return last;
}
};
对于递归算法,最重要的就是明确递归函数的定义。具体来说,我们的 reverse 函数定义是这样的:输入一个节点 head,将「以 head 为起点」的链表反转,并返回反转之后的头结点。
明白了函数的定义,再来看这个问题。比如说我们想反转这个链表:
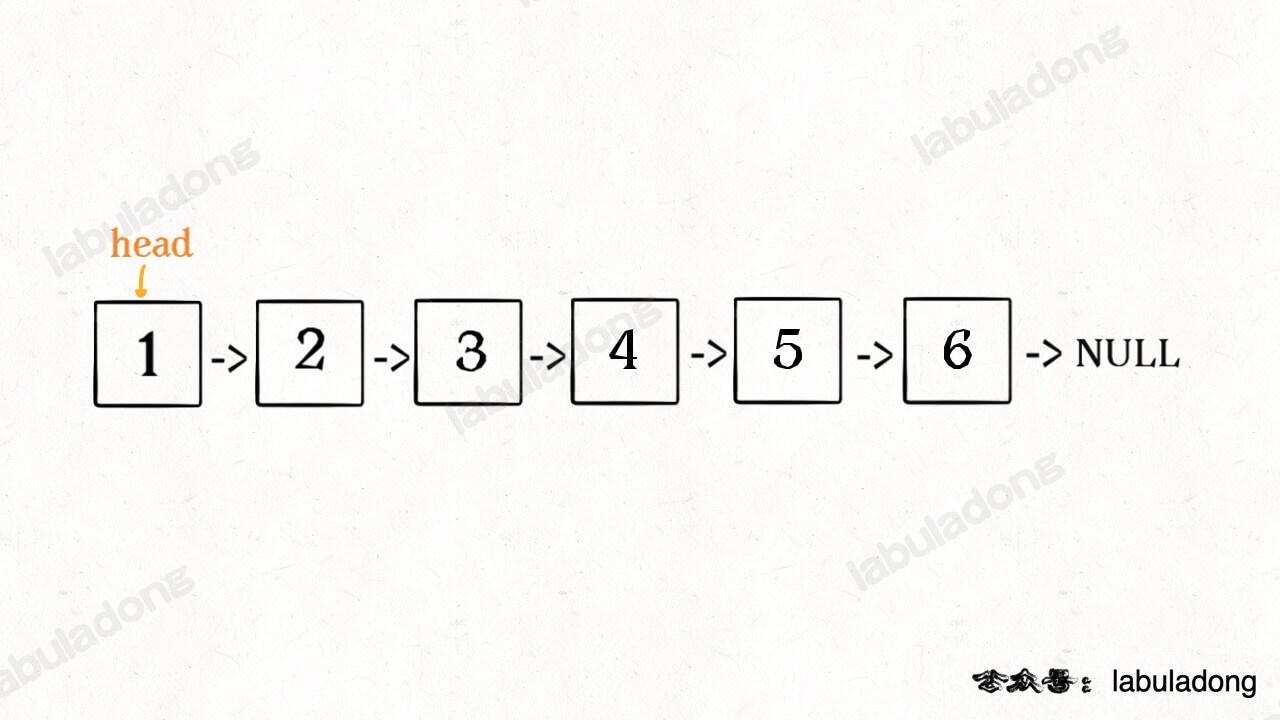
那么输入 reverse(head) 后,会在这里进行递归:
ListNode last = reverse(head->next);
不要跳进递归(你的脑袋能压几个栈呀?),而是要根据刚才的函数定义,来弄清楚这段代码会产生什么结果:
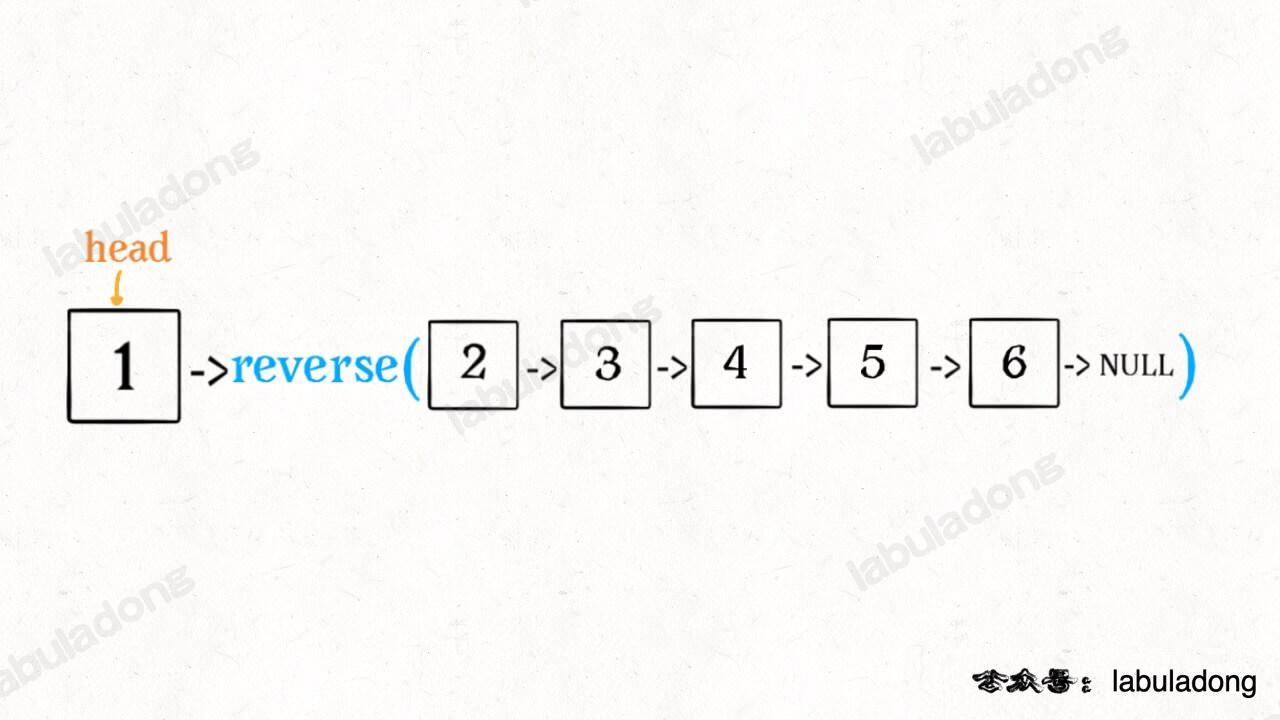
这个 reverse(head->next) 执行完成后,整个链表就成了这样:

并且根据函数定义,reverse 函数会返回反转之后的头结点,我们用变量 last 接收了。
现在再来看下面的代码:
head->next->next = head;
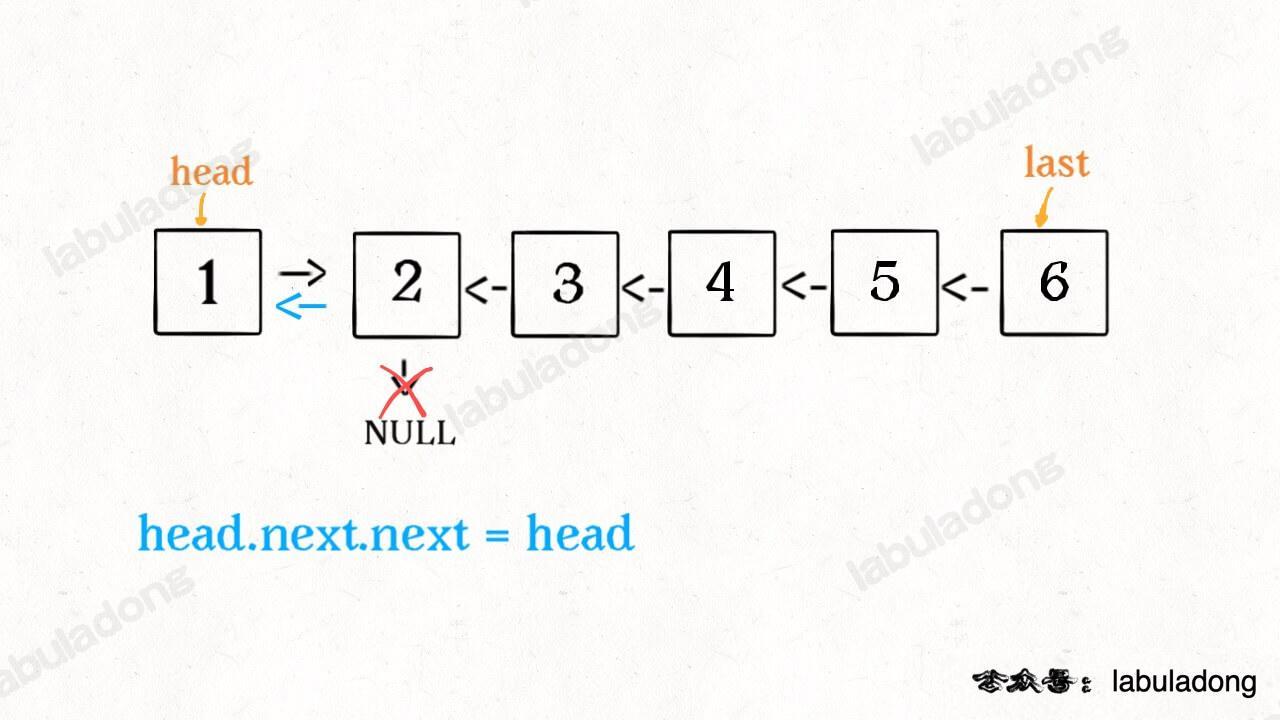
接下来:
head->next = null;
return last;
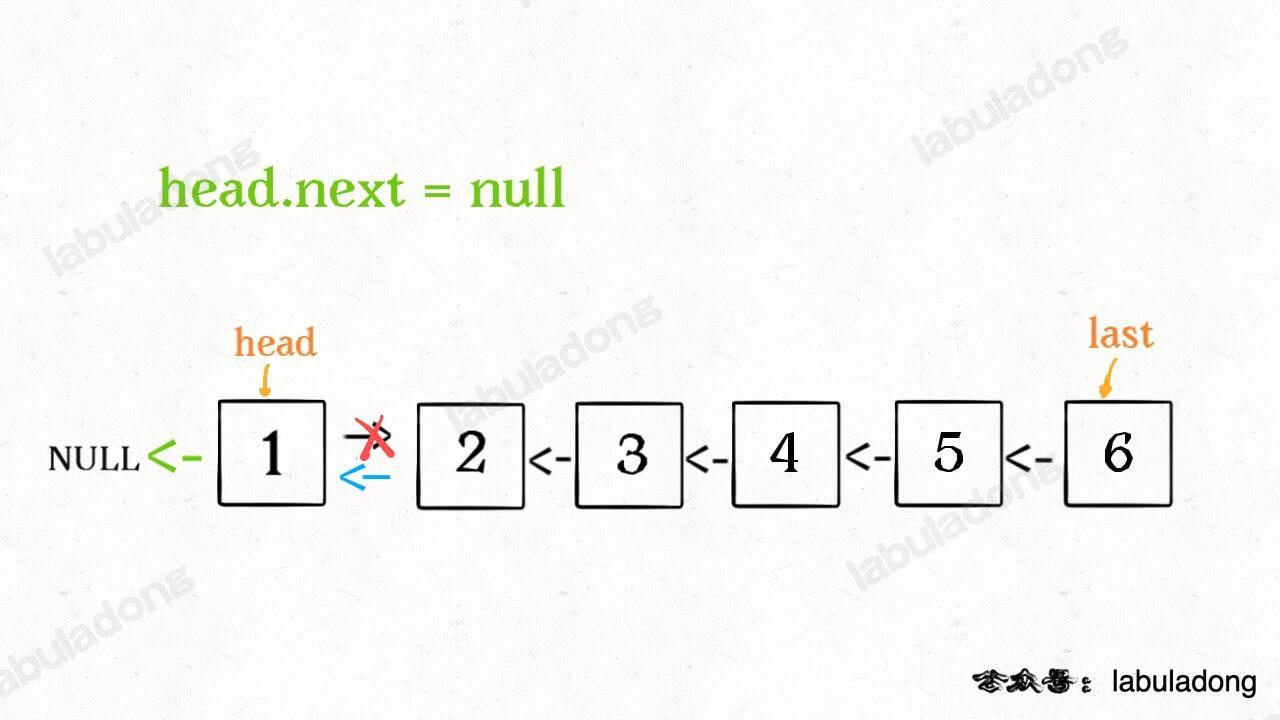
神不神奇,这样整个链表就反转过来了!递归代码就是这么简洁优雅,不过其中有两个地方需要注意:
1、递归函数要有 base case,也就是这句:
if (head == null || head->next == null) {
return head;
}
意思是如果链表为空或者只有一个节点的时候,反转结果就是它自己,直接返回即可。
2、当链表递归反转之后,新的头结点是 last,而之前的 head 变成了最后一个节点,别忘了链表的末尾要指向 null:
head->next = null;
理解了这两点后,我们就可以进一步深入了,接下来的问题其实都是在这个算法上的扩展。
反转链表的前N个节点
题目
比如说对于下图链表,执行 reverseN(head, 3):

解决思路和反转整个链表差不多,只要稍加修改即可:
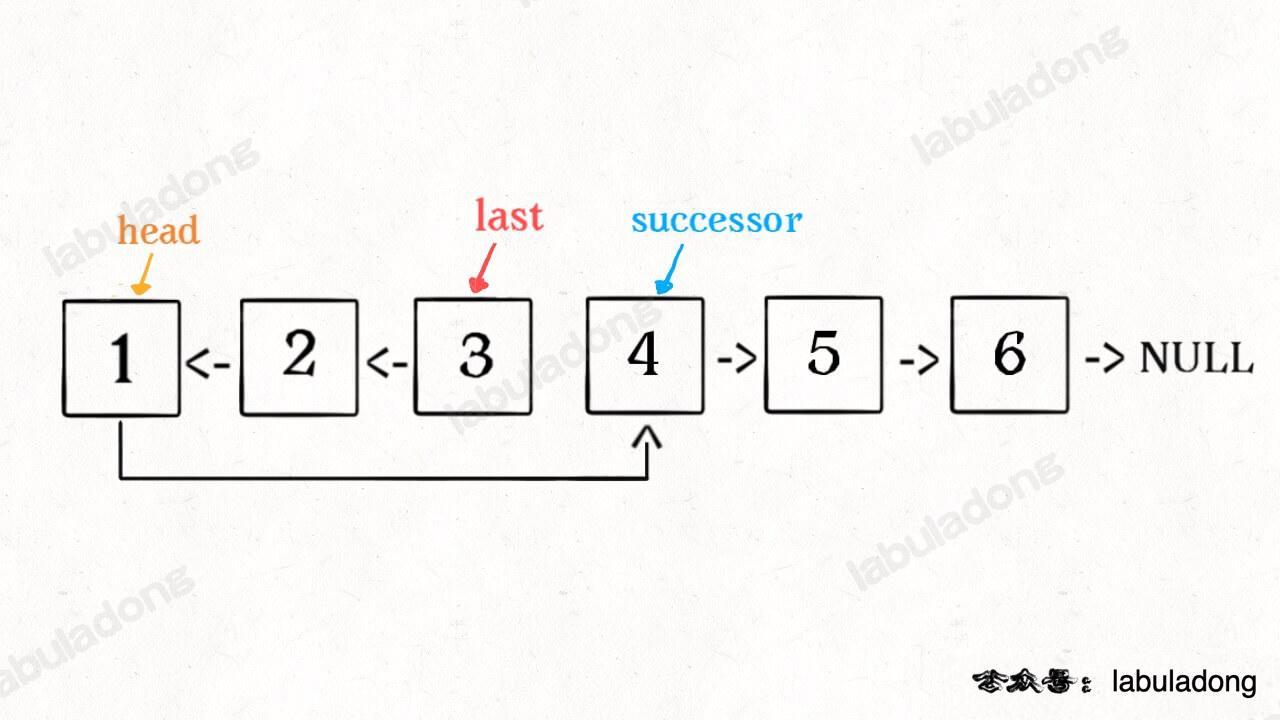
ListNode* successor = nullptr; // 后驱节点
// 反转以 head 为起点的 n 个节点,返回新的头结点
ListNode* reverseN(ListNode* head, int n) {
if (n == 1) {
// 记录第 n + 1 个节点
successor = head->next;
return head;
}
// 以 head.next 为起点,需要反转前 n - 1 个节点
ListNode* last = reverseN(head->next, n - 1);
head->next->next = head;
// 让反转之后的 head 节点和后面的节点连起来
head->next = successor;
return last;
}
具体的区别:
- base case 变为
n == 1,反转一个元素,就是它本身,同时要记录后驱节点。 - 刚才我们直接把
head.next设置为 null,因为整个链表反转后原来的head变成了整个链表的最后一个节点。但现在head节点在递归反转之后不一定是最后一个节点了,所以要记录后驱successor(第n + 1个节点),反转之后将head连接上。
反转链表的一部分
现在解决我们最开始提出的问题,给一个索引区间 [m, n](索引从 1 开始),仅仅反转区间中的链表元素。
首先,如果 m == 1,就相当于反转链表开头的 n 个元素嘛,也就是我们刚才实现的功能:
ListNode* reverseBetween(ListNode* head, int m, int n) {
// base case
if (m == 1) {
// 相当于反转前 n 个元素
return reverseN(head, n);
}
// ...
}
如果 m != 1 怎么办?如果我们把 head 的索引视为 1,那么我们是想从第 m 个元素开始反转对吧;如果把 head.next 的索引视为 1 呢?那么相对于 head.next,反转的区间应该是从第 m - 1 个元素开始的;那么对于 head.next.next 呢……
区别于迭代思想,这就是递归思想,所以我们可以完成代码:
ListNode* reverseBetween(ListNode* head, int m, int n) {
// base case
if (m == 1) {
return reverseN(head, n);
}
// 前进到反转的起点触发 base case
head->next = reverseBetween(head->next, m - 1, n - 1);
return head;
}
总结
递归的思想相对迭代思想,稍微有点难以理解,处理的技巧是:不要跳进递归,而是利用明确的定义来实现算法逻辑。
处理看起来比较困难的问题,可以尝试化整为零,把一些简单的解法进行修改,解决困难的问题。
值得一提的是,递归操作链表并不高效。和迭代解法相比,虽然时间复杂度都是 O(N),但是迭代解法的空间复杂度是 O(1),而递归解法需要堆栈,空间复杂度是 O(N)。所以递归操作链表可以作为对递归算法的练习或者拿去和小伙伴装逼,但是考虑效率的话还是使用迭代算法更好。
如何K个一组反转链表
题目
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
示例 1:

输入:head = [1,2,3,4,5], k = 2
输出:[2,1,4,3,5]
示例 2:
输入:head = [1,2,3,4,5], k = 3
输出:[3,2,1,4,5]
提示:
- 链表中的节点数目为
n 1 <= k <= n <= 50000 <= Node.val <= 1000
进阶:你可以设计一个只用 O(1) 额外内存空间的算法解决此问题吗?
分析问题
首先,链表是一种兼具递归和迭代性质的数据结构,认真思考一下可以发现这个问题具有递归性质。
什么叫递归性质?直接上图理解,比如说我们对这个链表调用 reverseKGroup(head, 2),即以 2 个节点为一组反转链表:
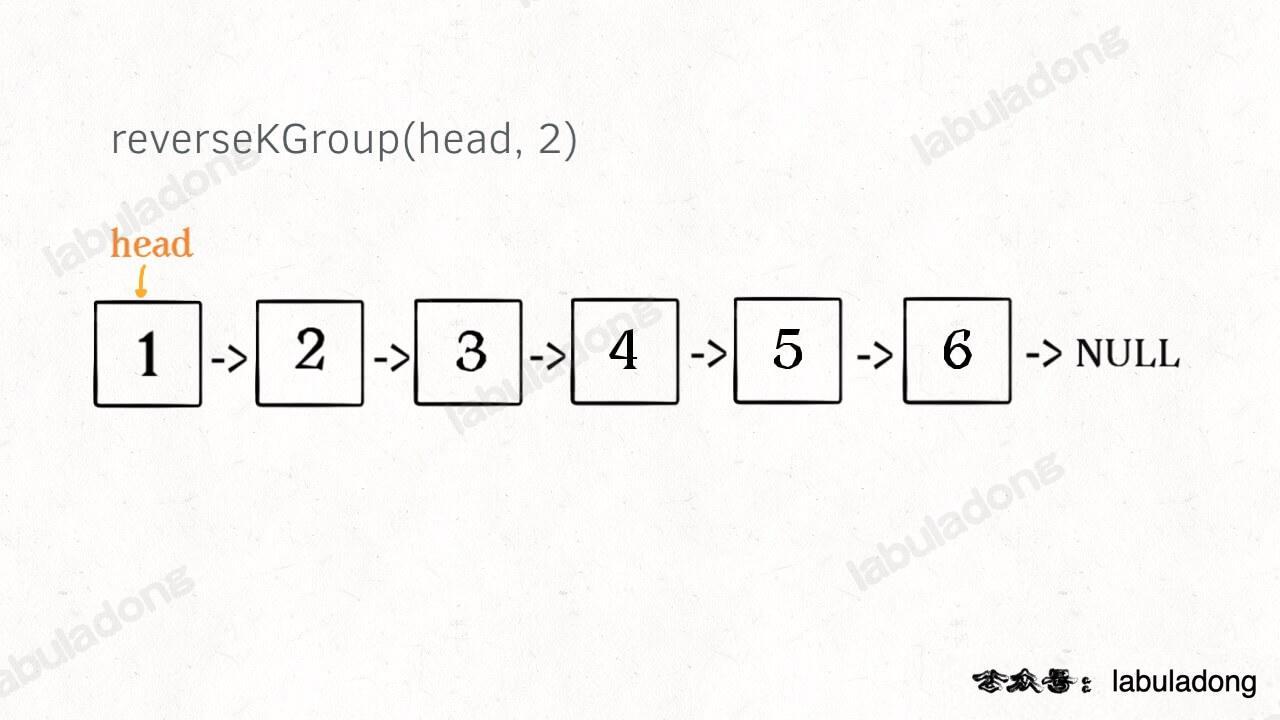
如果我设法把前 2 个节点反转,那么后面的那些节点怎么处理?后面的这些节点也是一条链表,而且规模(长度)比原来这条链表小,这就叫子问题。
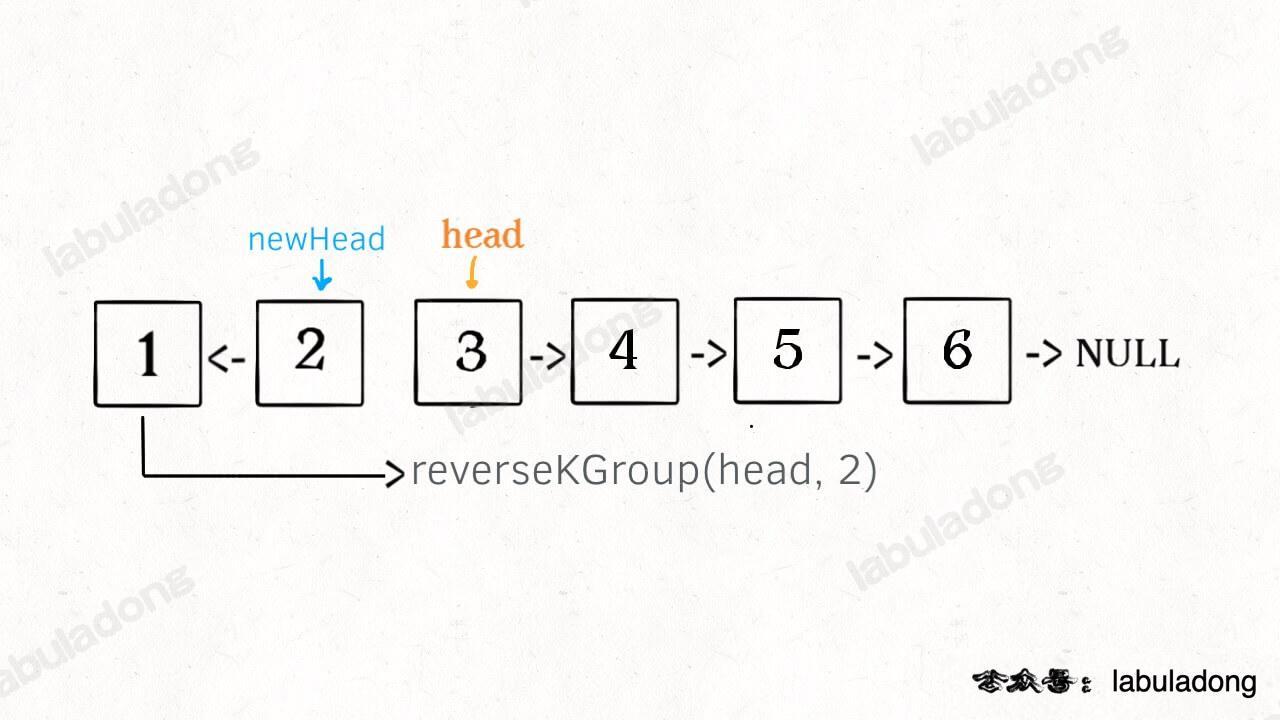
我们可以把原先的 head 指针移动到后面这一段链表的开头,然后继续递归调用 reverseKGroup(head, 2),因为子问题(后面这部分链表)和原问题(整条链表)的结构完全相同,这就是所谓的递归性质。
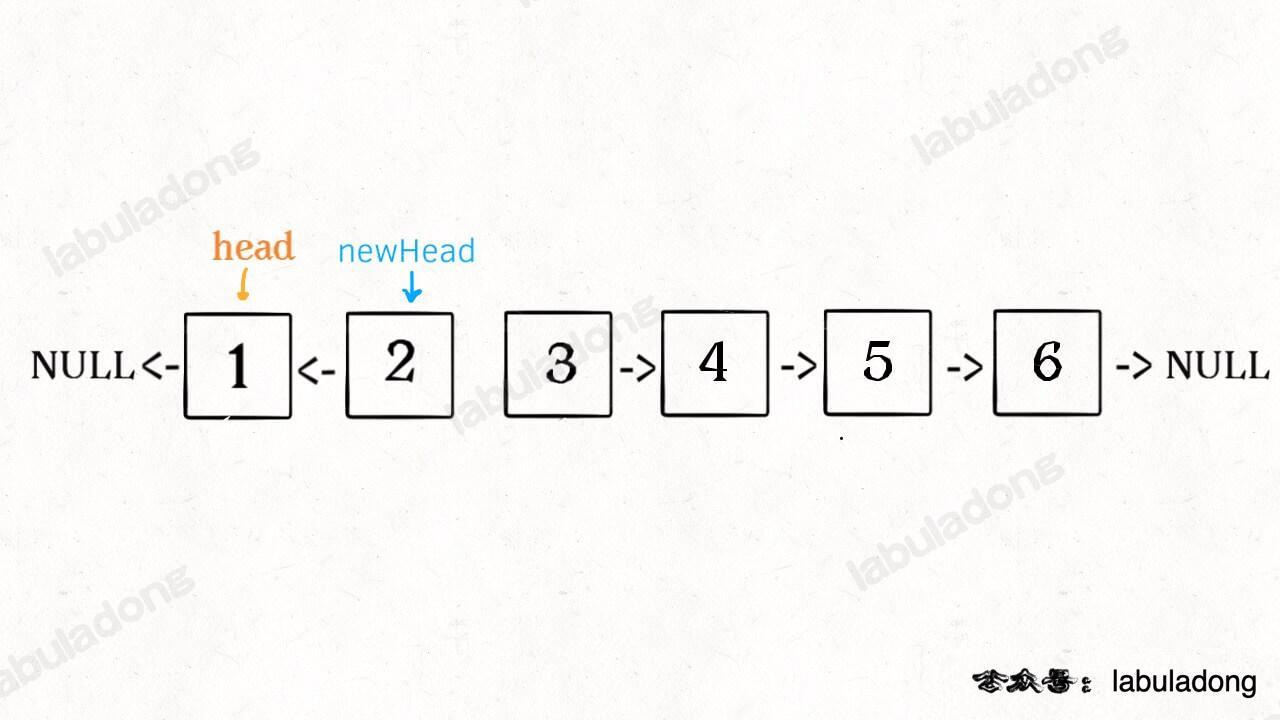
发现了递归性质,就可以得到大致的算法流程:
1、先反转以 head 开头的 k 个元素。
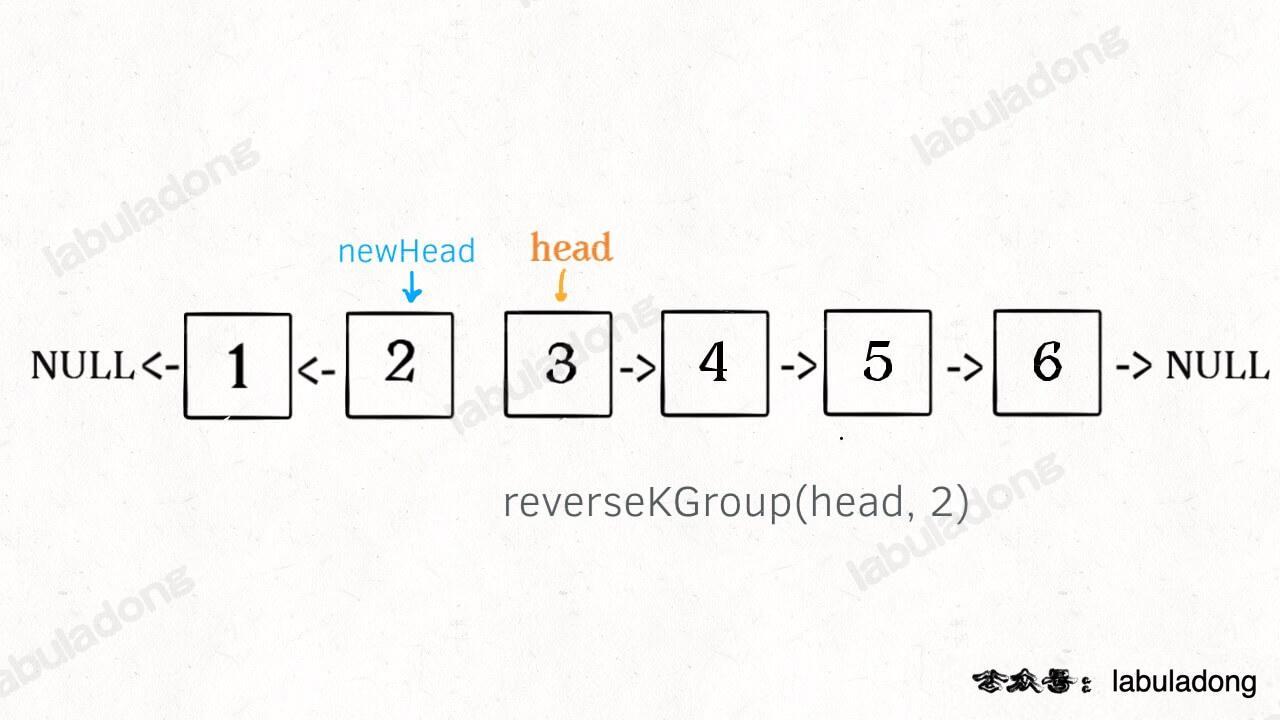
2、将第 k + 1 个元素作为 head 递归调用 reverseKGroup 函数。
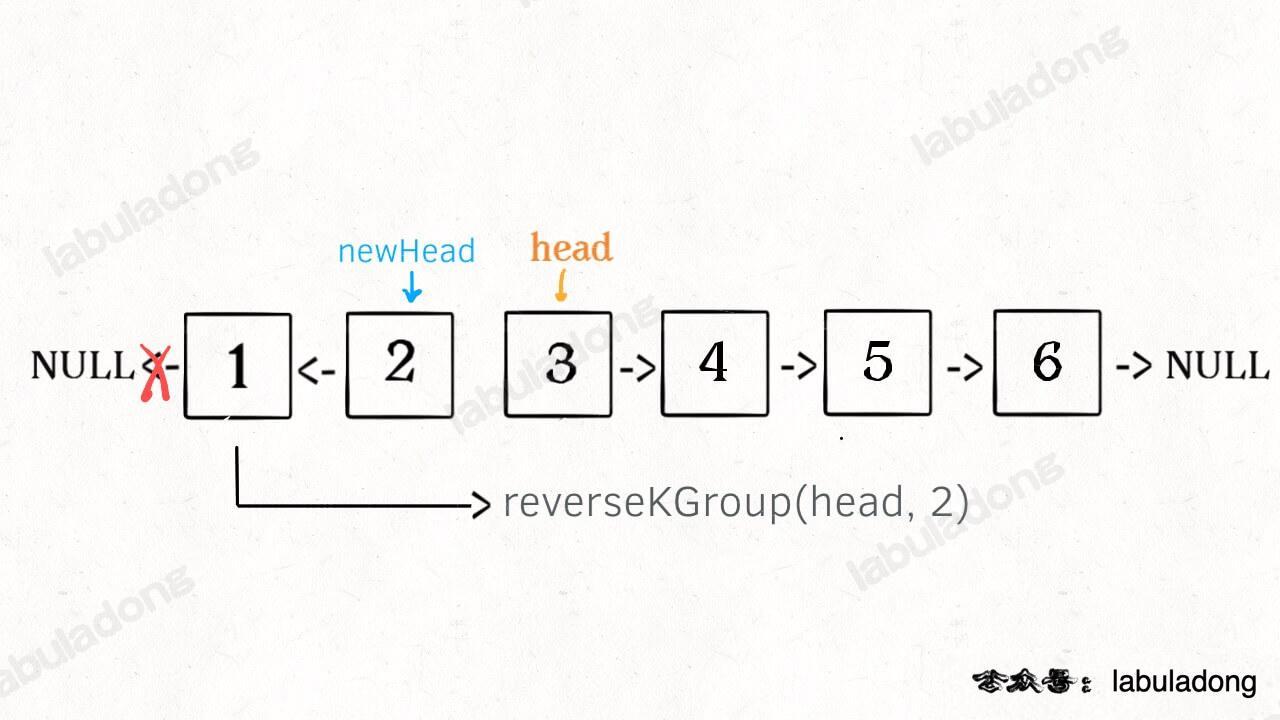
3、将上述两个过程的结果连接起来。
整体思路就是这样了,最后一点值得注意的是,递归函数都有个 base case,对于这个问题是什么呢?
题目说了,如果最后的元素不足 k 个,就保持不变。这就是 base case,待会会在代码里体现。
代码实现
首先,我们要实现一个 reverse 函数反转一个区间之内的元素。在此之前我们再简化一下,给定链表头结点,如何反转整个链表?
// 反转以 a 为头结点的链表
ListNode* reverse(ListNode* a) {
ListNode *pre, *cur, *nxt;
pre = nullptr;
cur = a;
nxt = a;
while (cur != nullptr) {
nxt = cur->next;
// 逐个结点反转
cur->next = pre;
// 更新指针位置
pre = cur;
cur = nxt;
}
// 返回反转后的头结点
return pre;
}
算法执行的过程如下 GIF 所示::

这次使用迭代思路来实现的,借助动画理解应该很容易。
「反转以 a 为头结点的链表」其实就是「反转 a 到 null 之间的结点」,那么如果让你「反转 a 到 b 之间的结点」,你会不会?
只要更改函数签名,并把上面的代码中 null 改成 b 即可:
// Reverse elements in the interval [a, b), note that it is left-closed and right-open
// 反转区间 [a, b) 的元素,注意是左闭右开
ListNode* reverse(ListNode* a, ListNode* b) {
ListNode *pre, *cur, *nxt;
pre = NULL; cur = a; nxt = a;
// Just change the termination condition of while
// while 终止的条件改一下就行了
while (cur != b) {
nxt = cur->next;
cur->next = pre;
pre = cur;
cur = nxt;
}
// Return the head node after reversal
// 返回反转后的头结点
return pre;
}
现在我们迭代实现了反转部分链表的功能,接下来就按照之前的逻辑编写 reverseKGroup 函数即可:
ListNode* reverseKGroup(ListNode* head, int k) {
if (head == nullptr) return nullptr;
// 区间 [a, b) 包含 k 个待反转元素
ListNode *a, *b;
a = b = head;
for (int i = 0; i < k; i++) {
// 不足 k 个,不需要反转,base case
if (b == nullptr) return head;
b = b->next;
}
// 反转前 k 个元素
ListNode *newHead = reverse(a, b);
// 递归反转后续链表并连接起来
a->next = reverseKGroup(b, k);
return newHead;
}
解释一下 for 循环之后的几句代码,注意 reverse 函数是反转区间 [a, b),所以情形是这样的:
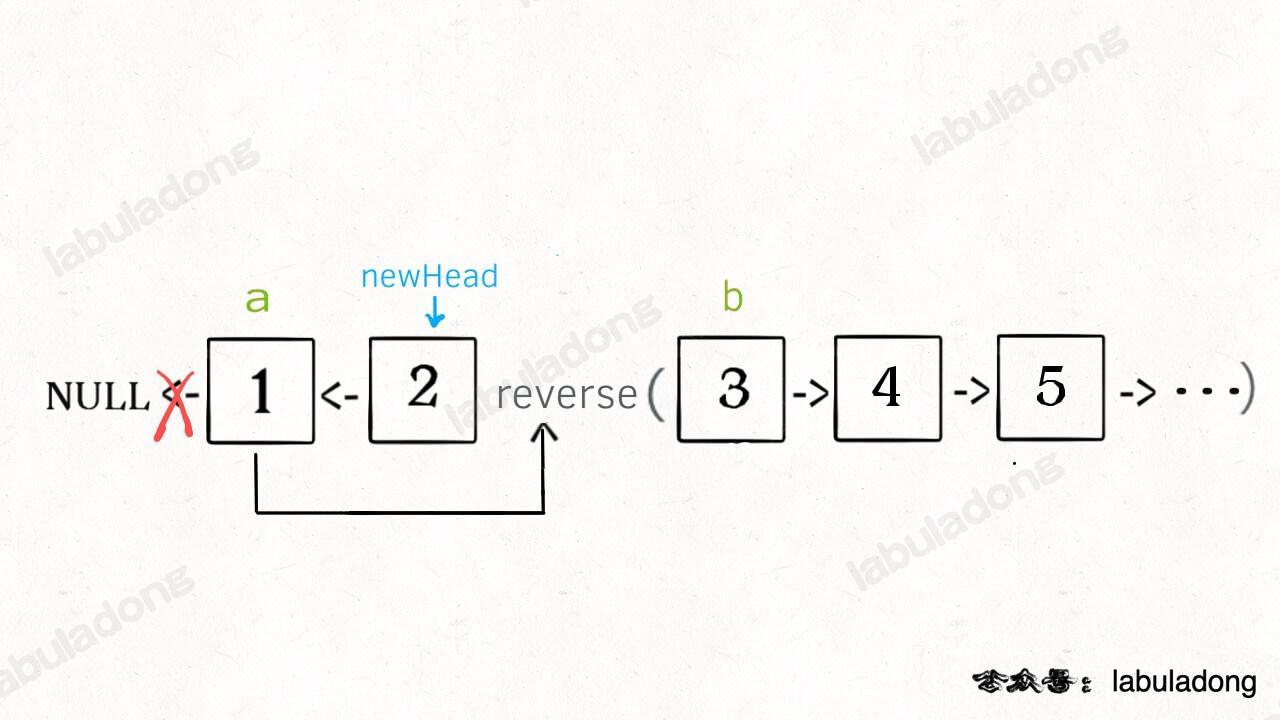
递归部分就不展开了,整个函数递归完成之后就是这个结果,完全符合题意:
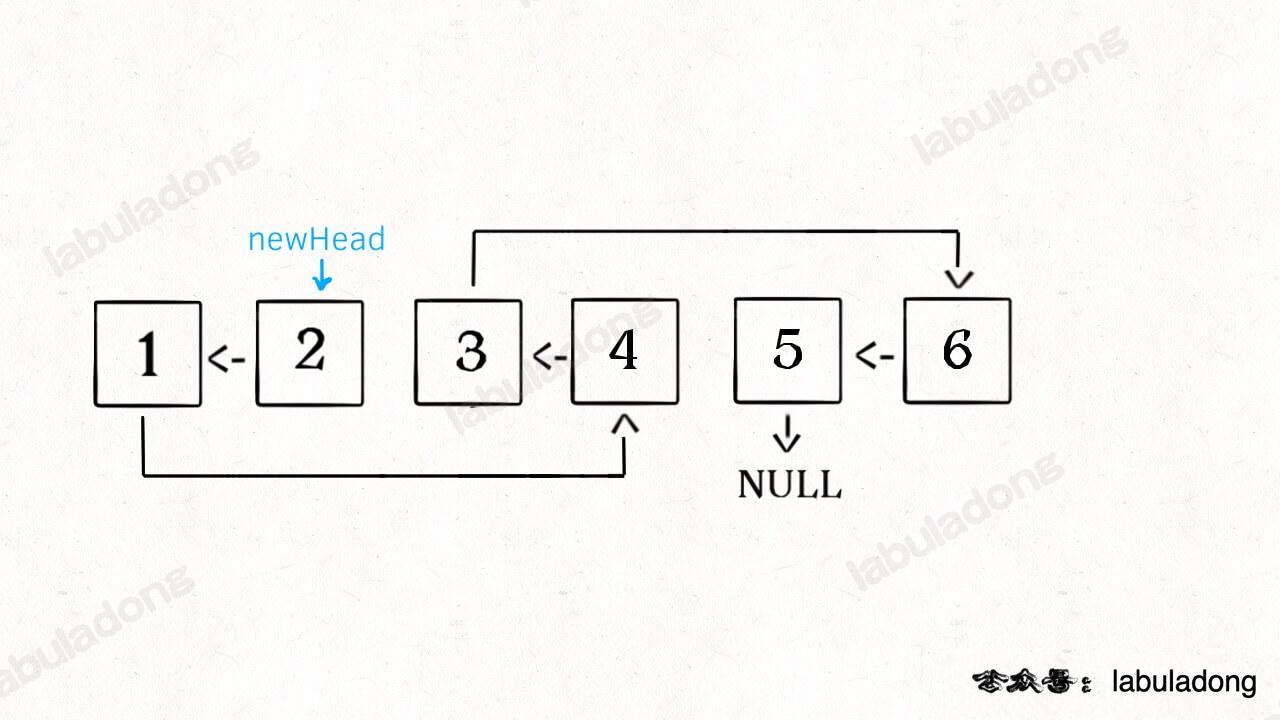
最后建议大家,对于这种基础数据结构的题目,可以多尝试思考递归解法。因为那些复杂数据结构、高级算法其实都是基于这些基础问题的变种,如果你掌握好基础,再去看高级的题目就会容易很多。
如何判断回文链表
寻找回文串的核心思想是从中心向两端扩展:
// 在 s 中寻找以 s[left] 和 s[right] 为中心的最长回文串
string palindrome(string s, int left, int right) {
// 防止索引越界
while (left >= 0 && right < s.length()
&& s[left] == s[right]) {
// 双指针,向两边展开
left--;
right++;
}
// 返回以 s[left] 和 s[right] 为中心的最长回文串
return s.substr(left + 1, right - left - 1);
}
因为回文串长度可能为奇数也可能是偶数,长度为奇数时只存在一个中心点,而长度为偶数时存在两个中心点,所以上面这个函数需要传入 l 和 r。
而判断一个字符串是不是回文串就简单很多,不需要考虑奇偶情况,只需要双指针技巧,从两端向中间逼近即可。
判断回文单链表
题目
输入一个单链表的头结点,判断这个链表中的数字是不是回文,函数签名如下:
bool isPalindrome(ListNode* head);
比如说:
输入: 1->2->null
输出: false
输入: 1->2->2->1->null
输出: true
这道题的关键在于,单链表无法倒着遍历,无法使用双指针技巧。
其实,借助二叉树后序遍历的思路,不需要显式反转原始链表也可以倒序遍历链表
class Solution {
public:
// 从左向右移动的指针
ListNode* left;
// 从右向左移动的指针
ListNode* right;
// 记录链表是否为回文
bool res = true;
bool isPalindrome(ListNode* head) {
left = head;
traverse(head);
return res;
}
void traverse(ListNode* right) {
if (right == nullptr) {
return;
}
// 利用递归,走到链表尾部
traverse(right->next);
// 后序遍历位置,此时的 right 指针指向链表右侧尾部
// 所以可以和 left 指针比较,判断是否是回文链表
if (left->val != right->val) {
res = false;
}
left = left->next;
}
};
这么做的核心逻辑是什么呢?实际上就是把链表节点放入一个栈,然后再拿出来,这时候元素顺序就是反的,只不过我们利用的是递归函数的堆栈而已。
当然,无论造一条反转链表还是利用后序遍历,算法的时间和空间复杂度都是 O(N)。下面我们想想,能不能不用额外的空间,解决这个问题呢?
优化空间复杂度
1、先通过 [双指针技巧] 中的快慢指针来找到链表的中点:
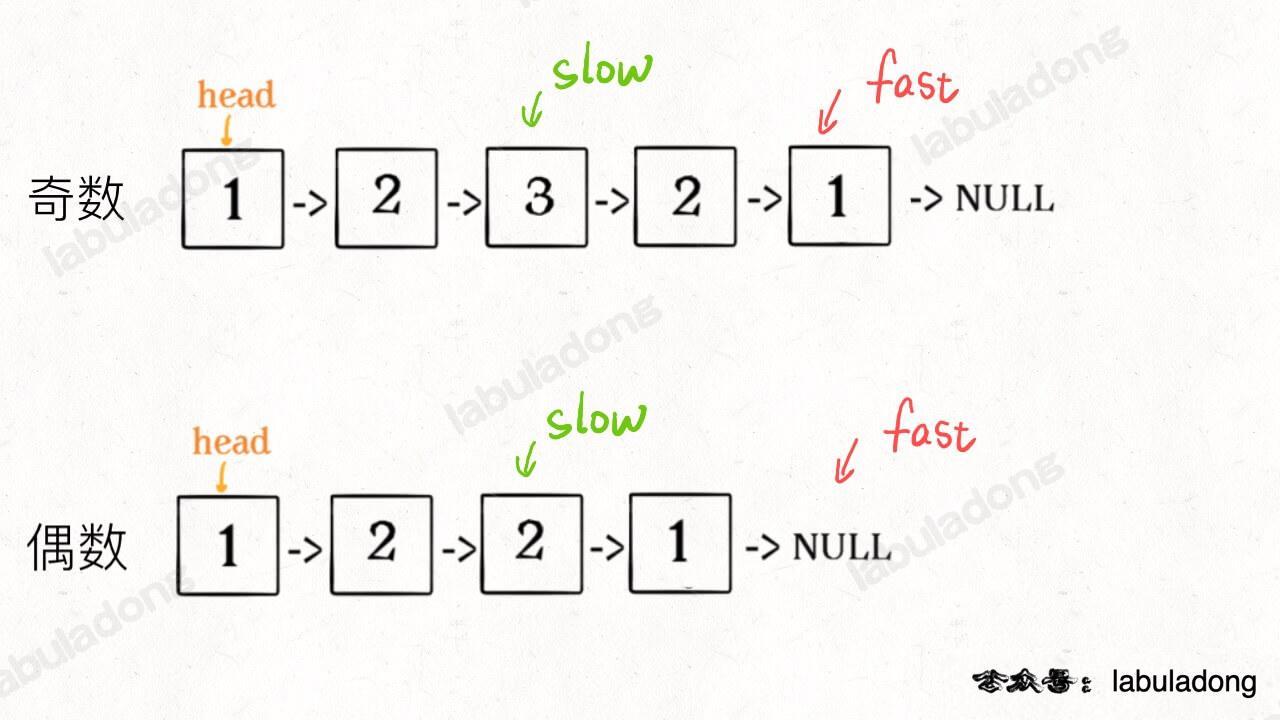
2、如果fast指针没有指向null,说明链表长度为奇数,slow还要再前进一步:
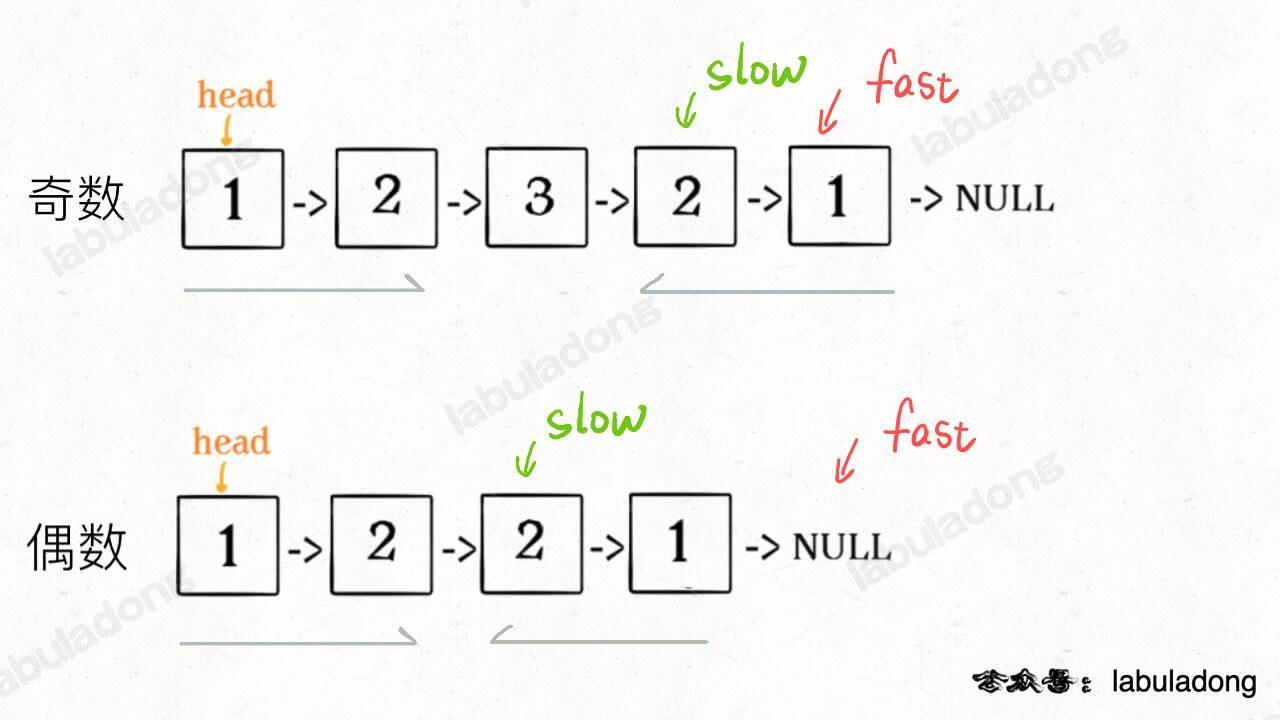
3、从slow开始反转后面的链表,现在就可以开始比较回文串了:
class Solution {
public:
bool isPalindrome(ListNode* head) {
ListNode* slow, *fast, *p, *q;
slow = fast = head;
while (fast != nullptr && fast->next != nullptr) {
p = slow;
slow = slow->next;
fast = fast->next->next;
}
if (fast != nullptr){
p = slow;
slow = slow->next;
}
ListNode* left = head;
ListNode* right = reverse(slow);
q = right;
while (right != nullptr) {
if (left->val != right->val)
return false;
left = left->next;
right = right->next;
}
return true;
}
ListNode* reverse(ListNode* head) {
ListNode* pre = nullptr, *cur = head;
while (cur != nullptr) {
ListNode* next = cur->next;
cur->next = pre;
pre = cur;
cur = next;
}
return pre;
}
};
算法总体的时间复杂度 O(N),空间复杂度 O(1),已经是最优的了。
我知道肯定有读者会问:这种解法虽然高效,但破坏了输入链表的原始结构,能不能避免这个瑕疵呢?
其实这个问题很好解决,关键在于得到p, q这两个指针位置:
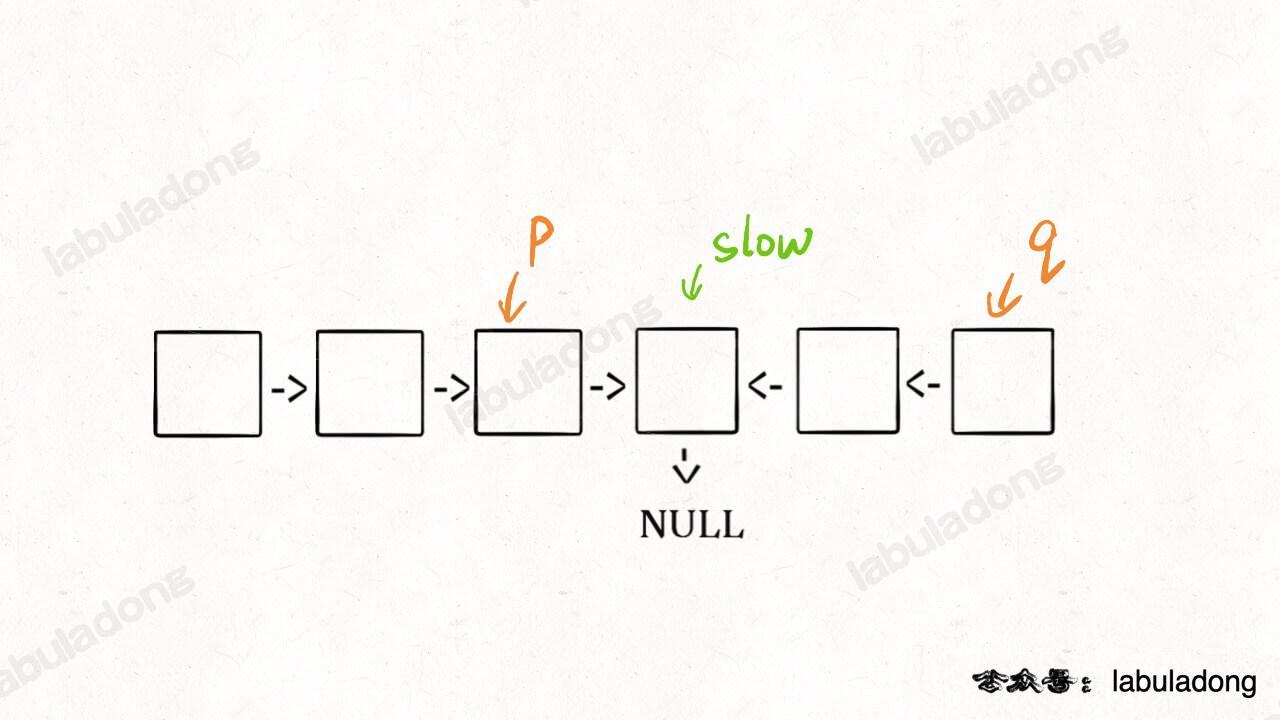
这样,只要在函数 return 之前加一段代码即可恢复原先链表顺序:
p->next = reverse(q);
数组算法
小而美的算法技巧:前缀和数组
前缀和技巧适用于快速、频繁地计算一个索引区间内的元素之和。
一维数组中的前缀和
题目
给定一个整数数组 nums,处理以下类型的多个查询:
- 计算索引
left和right(包含left和right)之间的nums元素的 和 ,其中left <= right
实现 NumArray 类:
NumArray(int[] nums)使用数组nums初始化对象int sumRange(int i, int j)返回数组nums中索引left和right之间的元素的 总和 ,包含left和right两点(也就是nums[left] + nums[left + 1] + ... + nums[right])
示例 1:
输入:
["NumArray", "sumRange", "sumRange", "sumRange"]
[[[-2, 0, 3, -5, 2, -1]], [0, 2], [2, 5], [0, 5]]
输出:
[null, 1, -1, -3]
解释:
NumArray numArray = new NumArray([-2, 0, 3, -5, 2, -1]);
numArray.sumRange(0, 2); // return 1 ((-2) + 0 + 3)
numArray.sumRange(2, 5); // return -1 (3 + (-5) + 2 + (-1))
numArray.sumRange(0, 5); // return -3 ((-2) + 0 + 3 + (-5) + 2 + (-1))
提示:
1 <= nums.length <= 104-105 <= nums[i] <= 1050 <= i <= j < nums.length- 最多调用
104次sumRange方法
思路及代码
class NumArray {
private:
// 前缀和数组
vector<int> preSum;
public:
/* 输入一个数组,构造前缀和 */
NumArray(vector<int>& nums) {
// preSum[0] = 0,便于计算累加和
preSum.resize(nums.size() + 1);
// 计算 nums 的累加和
for (int i = 1; i < preSum.size(); i++) {
preSum[i] = preSum[i - 1] + nums[i - 1];
}
}
/* 查询闭区间 [left, right] 的累加和 */
int sumRange(int left, int right) {
return preSum[right + 1] - preSum[left];
}
};
核心思路是我们 new 一个新的数组 preSum 出来,preSum[i] 记录 nums[0..i-1] 的累加和,看图 10 = 3 + 5 + 2:

看这个 preSum 数组,如果我想求索引区间 [1, 4] 内的所有元素之和,就可以通过 preSum[5] - preSum[1] 得出。
这样,sumRange 函数仅仅需要做一次减法运算,避免了每次进行 for 循环调用,最坏时间复杂度为常数 O(1)。
这个技巧在生活中运用也挺广泛的,比方说,你们班上有若干同学,每个同学有一个期末考试的成绩(满分 100 分),那么请你实现一个 API,输入任意一个分数段,返回有多少同学的成绩在这个分数段内。
那么,你可以先通过计数排序的方式计算每个分数具体有多少个同学,然后利用前缀和技巧来实现分数段查询的 API:
int[] scores; // 存储着所有同学的分数
// 试卷满分 100 分
int[] count = new int[100 + 1]
// 记录每个分数有几个同学
for (int score : scores)
count[score]++
// 构造前缀和
for (int i = 1; i < count.length; i++)
count[i] = count[i] + count[i-1];
// 利用 count 这个前缀和数组进行分数段查询
接下来,我们看一看前缀和思路在二维数组中如何运用。
二维矩阵中的前缀和
题目
给定一个二维矩阵 matrix,以下类型的多个请求:
- 计算其子矩形范围内元素的总和,该子矩阵的 左上角 为
(row1, col1),右下角 为(row2, col2)。
实现 NumMatrix 类:
NumMatrix(int[][] matrix)给定整数矩阵matrix进行初始化int sumRegion(int row1, int col1, int row2, int col2)返回 左上角(row1, col1)、右下角(row2, col2)所描述的子矩阵的元素 总和 。
示例 1:
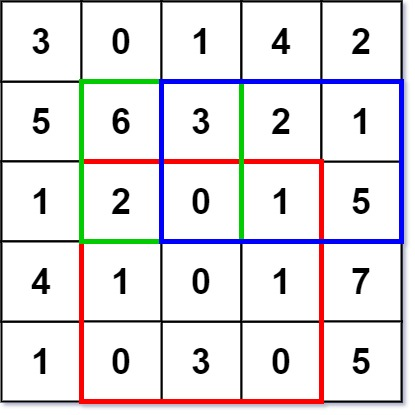
输入:
["NumMatrix","sumRegion","sumRegion","sumRegion"]
[[[[3,0,1,4,2],[5,6,3,2,1],[1,2,0,1,5],[4,1,0,1,7],[1,0,3,0,5]]],[2,1,4,3],[1,1,2,2],[1,2,2,4]]
输出:
[null, 8, 11, 12]
解释:
NumMatrix numMatrix = new NumMatrix([[3,0,1,4,2],[5,6,3,2,1],[1,2,0,1,5],[4,1,0,1,7],[1,0,3,0,5]]);
numMatrix.sumRegion(2, 1, 4, 3); // return 8 (红色矩形框的元素总和)
numMatrix.sumRegion(1, 1, 2, 2); // return 11 (绿色矩形框的元素总和)
numMatrix.sumRegion(1, 2, 2, 4); // return 12 (蓝色矩形框的元素总和)
提示:
m == matrix.lengthn == matrix[i].length1 <= m, n <= 200-105 <= matrix[i][j] <= 1050 <= row1 <= row2 < m0 <= col1 <= col2 < n- 最多调用
104次sumRegion方法
思路
注意任意子矩阵的元素和可以转化成它周边几个大矩阵的元素和的运算:

而这四个大矩阵有一个共同的特点,就是左上角都是 (0, 0) 原点。
那么做这道题更好的思路和一维数组中的前缀和是非常类似的,我们可以维护一个二维 preSum 数组,专门记录以原点为顶点的矩阵的元素之和,就可以用几次加减运算算出任何一个子矩阵的元素和:
class NumMatrix {
private:
// 定义:preSum[i][j] 记录 matrix 中子矩阵 [0, 0, i-1, j-1] 的元素和
vector<vector<int>> preSum;
public:
NumMatrix(vector<vector<int>>& matrix) {
int m = matrix.size(), n = matrix[0].size();
if (m == 0 || n == 0) return;
// 构造前缀和矩阵
preSum = vector<vector<int>>(m + 1, vector<int>(n + 1));
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
// 计算每个矩阵 [0, 0, i, j] 的元素和
preSum[i][j] = preSum[i-1][j] + preSum[i][j-1] + matrix[i - 1][j - 1] - preSum[i-1][j-1];
}
}
}
// 计算子矩阵 [x1, y1, x2, y2] 的元素和
int sumRegion(int x1, int y1, int x2, int y2) {
// 目标矩阵之和由四个相邻矩阵运算获得
return preSum[x2+1][y2+1] - preSum[x1][y2+1] - preSum[x2+1][y1] + preSum[x1][y1];
}
};
小而美的算法技巧:差分数组
差分数组的主要适用场景是频繁对原始数组的某个区间的元素进行增减。
比如说,我给你输入一个数组 nums,然后又要求给区间 nums[2..6] 全部加 1,再给 nums[3..9] 全部减 3,再给 nums[0..4] 全部加 2,再给…
一通操作猛如虎,然后问你,最后 nums 数组的值是什么?
常规的思路很容易,你让我给区间 nums[i..j] 加上 val,那我就一个 for 循环给它们都加上呗,还能咋样?这种思路的时间复杂度是 O(N),由于这个场景下对 nums 的修改非常频繁,所以效率会很低下。
这里就需要差分数组的技巧,类似前缀和技巧构造的 preSum 数组,我们先对 nums 数组构造一个 diff 差分数组,diff[i] 就是 nums[i] 和 nums[i-1] 之差:
int diff[nums.size()];
// 构造差分数组
diff[0] = nums[0];
for (int i = 1; i < nums.size(); i++) {
diff[i] = nums[i] - nums[i - 1];
}
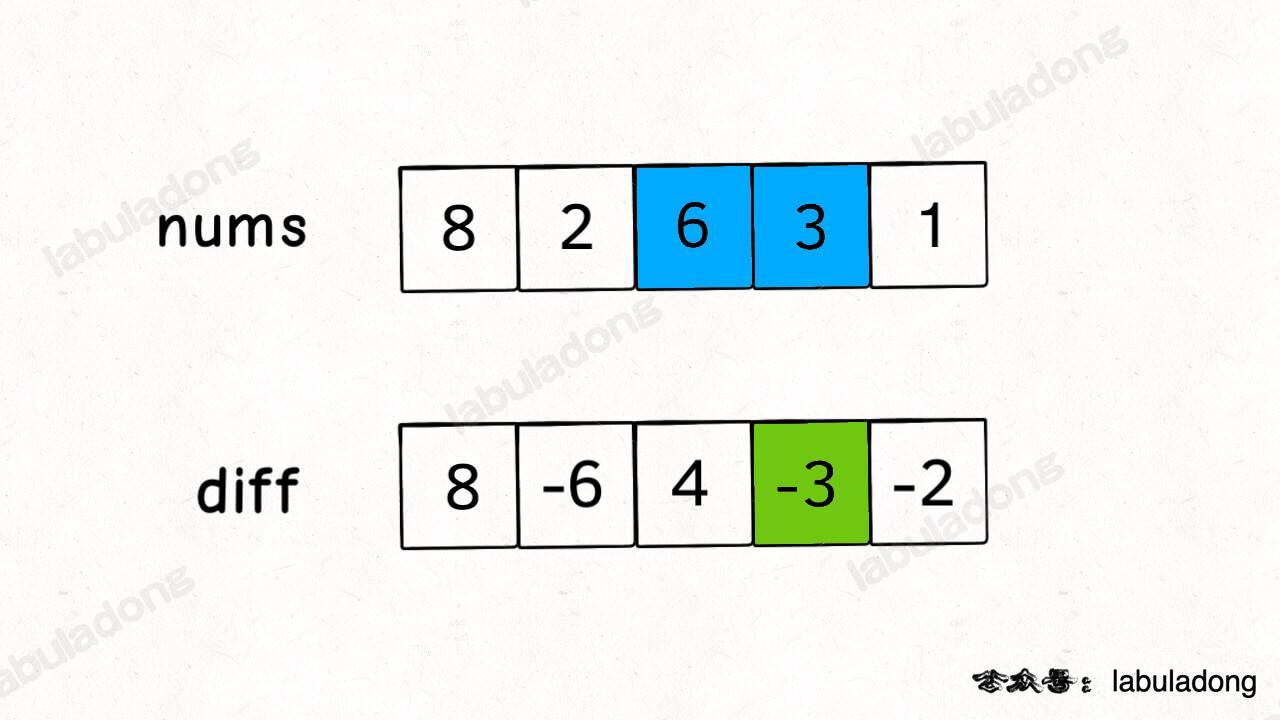
通过这个 diff 差分数组是可以反推出原始数组 nums 的,代码逻辑如下:
int res[diff.size()];
// 根据差分数组构造结果数组
res[0] = diff[0];
for (int i = 1; i < diff.size(); i++) {
res[i] = res[i - 1] + diff[i];
}
这样构造差分数组 diff,就可以快速进行区间增减的操作,如果你想对区间 nums[i..j] 的元素全部加 3,那么只需要让 diff[i] += 3,然后再让 diff[j+1] -= 3 即可:
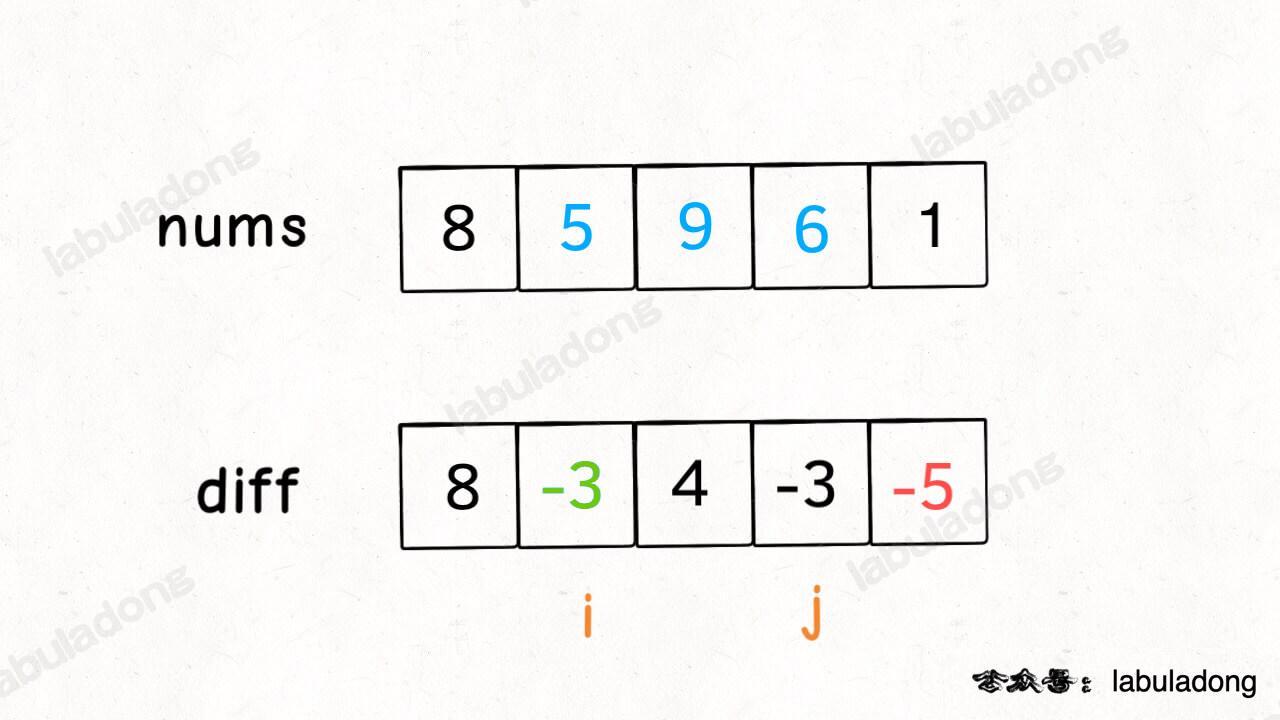
原理很简单,回想 diff 数组反推 nums 数组的过程,diff[i] += 3 意味着给 nums[i..] 所有的元素都加了 3,然后 diff[j+1] -= 3 又意味着对于 nums[j+1..] 所有元素再减 3,那综合起来,是不是就是对 nums[i..j] 中的所有元素都加 3 了?
只要花费 O(1) 的时间修改 diff 数组,就相当于给 nums 的整个区间做了修改。多次修改 diff,然后通过 diff 数组反推,即可得到 nums 修改后的结果。
现在我们把差分数组抽象成一个类,包含 increment 方法和 result 方法:
// 差分数组工具类
class Difference {
// 差分数组
private:
int* diff;
/* 输入一个初始数组,区间操作将在这个数组上进行 */
public:
Difference(int* nums, int length) {
assert(length > 0);
diff = new int[length]();
diff[0] = nums[0];
for (int i = 1; i < length; i++) {
diff[i] = nums[i] - nums[i - 1];
}
}
/* 给闭区间 [i, j] 增加 val(可以是负数)*/
void increment(int i, int j, int val) {
diff[i] += val;
if (j + 1 < sizeof(diff) / sizeof(diff[0])) {
diff[j + 1] -= val;
}
}
/* 返回结果数组 */
int* result() {
int* res = new int[sizeof(diff) / sizeof(diff[0])]();
res[0] = diff[0];
for (int i = 1; i < sizeof(diff) / sizeof(diff[0]); i++) {
res[i] = res[i - 1] + diff[i];
}
return res;
}
};
这里注意一下 increment 方法中的 if 语句:
当 j+1 >= diff.length 时,说明是对 nums[i] 及以后的整个数组都进行修改,那么就不需要再给 diff 数组减 val 了。
算法实践
题目
假设你有一个长度为 n 的数组,初始情况下所有的数字均为 0,你将会被给出 k 个更新的操作。
其中,每个操作会被表示为一个三元组:[startIndex, endIndex, inc],你需要将子数组 A[startIndex … endIndex](包括 startIndex 和 endIndex)增加 inc。
请你返回 k 次操作后的数组。
示例:
输入: length = 5, updates = [[1,3,2],[2,4,3],[0,2,-2]]
输出: [-2,0,3,5,3]
解释:
初始状态:
[0,0,0,0,0]
进行了操作 [1,3,2] 后的状态:
[0,2,2,2,0]
进行了操作 [2,4,3] 后的状态:
[0,2,5,5,3]
进行了操作 [0,2,-2] 后的状态:
[-2,0,3,5,3]
代码:
class Solution {
public:
vector<int> getModifiedArray(int length, vector<vector<int>>& updates) {
// nums 初始化为全 0
vector<int> nums(length, 0);
// 构造差分解法
Difference df(nums);
for (auto& update : updates) {
int i = update[0];
int j = update[1];
int val = update[2];
df.increment(i, j, val);
}
return df.result();
}
};
题目
这里有 n 个航班,它们分别从 1 到 n 进行编号。
有一份航班预订表 bookings ,表中第 i 条预订记录 bookings[i] = [firsti, lasti, seatsi] 意味着在从 firsti 到 lasti (包含 firsti 和 lasti )的 每个航班 上预订了 seatsi 个座位。
请你返回一个长度为 n 的数组 answer,里面的元素是每个航班预定的座位总数。
示例 1:
输入:bookings = [[1,2,10],[2,3,20],[2,5,25]], n = 5
输出:[10,55,45,25,25]
解释:
航班编号 1 2 3 4 5
预订记录 1 : 10 10
预订记录 2 : 20 20
预订记录 3 : 25 25 25 25
总座位数: 10 55 45 25 25
因此,answer = [10,55,45,25,25]
示例 2:
输入:bookings = [[1,2,10],[2,2,15]], n = 2
输出:[10,25]
解释:
航班编号 1 2
预订记录 1 : 10 10
预订记录 2 : 15
总座位数: 10 25
因此,answer = [10,25]
提示:
1 <= n <= 2 * 1041 <= bookings.length <= 2 * 104bookings[i].length == 31 <= firsti <= lasti <= n1 <= seatsi <= 104
代码
class Solution {
public:
vector<int> corpFlightBookings(vector<vector<int>>& bookings, int n) {
// nums 初始化为全 0
vector<int> nums(n);
// 构造差分解法
Difference df(nums);
for (auto& booking : bookings) {
// 注意转成数组索引要减一哦
int i = booking[0] - 1;
int j = booking[1] - 1;
int val = booking[2];
// 对区间 nums[i..j] 增加 val
df.increment(i, j, val);
}
// 返回最终的结果数组
return df.result();
}
};
题目
你是一个开公交车的司机,公交车的最大载客量为 capacity,沿途要经过若干车站,给你一份乘客行程表 int[][] trips,其中 trips[i] = [num, start, end] 代表着有 num 个旅客要从站点 start 上车,到站点 end 下车,请你计算是否能够一次把所有旅客运送完毕(不能超过最大载客量 capacity)。
思路
比如输入:
trips = [[2,1,5],[3,3,7]], capacity = 4
这就不能一次运完,因为 trips[1] 最多只能上 2 人,否则车就会超载。
相信你已经能够联想到差分数组技巧了:trips[i] 代表着一组区间操作,旅客的上车和下车就相当于数组的区间加减;只要结果数组中的元素都小于 capacity,就说明可以不超载运输所有旅客。
但问题是,差分数组的长度(车站的个数)应该是多少呢?题目没有直接给,但给出了数据取值范围:
0 <= trips[i][1] < trips[i][2] <= 1000
车站编号从 0 开始,最多到 1000,也就是最多有 1001 个车站,那么我们的差分数组长度可以直接设置为 1001,这样索引刚好能够涵盖所有车站的编号:
class Solution {
public:
bool carPooling(vector<vector<int>>& trips, int capacity) {
// 最多有 1001 个车站
vector<int> nums(1001);
// 构造差分解法
Difference df(nums);
for (vector<int> trip : trips) {
// 乘客数量
int val = trip[0];
// 第 trip[1] 站乘客上车
int i = trip[1];
// 第 trip[2] 站乘客已经下车,
// 即乘客在车上的区间是 [trip[1], trip[2] - 1]
int j = trip[2] - 1;
// 进行区间操作
df.increment(i, j, val);
}
vector<int> res = df.result();
// 客车自始至终都不应该超载
for (int i = 0; i < res.size(); i++) {
if (capacity < res[i]) {
return false;
}
}
return true;
}
};
田忌赛马背后的算法决策
题目
给你输入两个长度相等的数组 nums1 和 nums2,请你重新组织 nums1 中元素的位置,使得 nums1 的「优势」最大化。
如果 nums1[i] > nums2[i],就是说 nums1 在索引 i 上对 nums2[i] 有「优势」。优势最大化也就是说让你重新组织 nums1,尽可能多的让 nums1[i] > nums2[i]。
思路
比如输入:
nums1 = [12,24,8,32]
nums2 = [13,25,32,11]
你的算法应该返回 [24,32,8,12],因为这样排列 nums1 的话有三个元素都有「优势」。
这就像田忌赛马的情景,nums1 就是田忌的马,nums2 就是齐王的马,数组中的元素就是马的战斗力,你就是孙膑,展示你真正的技术吧。
仔细想想,这个题的解法还是有点扑朔迷离的。什么时候应该放弃抵抗去送人头,什么时候应该硬刚?这里面应该有一种算法策略来最大化「优势」。
送人头一定是迫不得已而为之的权宜之计,否则隔壁田忌就会以为你是齐王买来的演员。只有田忌的上等马比不过齐王的上等马时,才会用下等马去和齐王的上等马互换。
对于比较复杂的问题,可以尝试从特殊情况考虑。
你想,谁应该去应对齐王最快的马?肯定是田忌最快的那匹马,我们简称一号选手。
如果田忌的一号选手比不过齐王的一号选手,那其他马肯定是白给了,显然这种情况应该用田忌垫底的马去送人头,降低己方损失,保存实力,增加接下来比赛的胜率。
但如果田忌的一号选手能比得过齐王的一号选手,那就和齐王硬刚好了,反正这把田忌可以赢。
你也许说,这种情况下说不定田忌的二号选手也能干得过齐王的一号选手?如果可以的话,让二号选手去对决齐王的一号选手,不是更节约?
就好比,如果考 60 分就能过的话,何必考 90 分?每多考一分就亏一分,刚刚好卡在 60 分是最划算的。
这种节约的策略是没问题的,但是没有必要。这也是本题有趣的地方,需要绕个脑筋急转弯:
我们暂且把田忌的一号选手称为 T1,二号选手称为 T2,齐王的一号选手称为 Q1。
如果 T2 能赢 Q1,你试图保存己方实力,让 T2 去战 Q1,把 T1 留着是为了对付谁?
显然,你担心齐王还有战力大于 T2 的马,可以让 T1 去对付。
但是你仔细想想,现在 T2 已经是可以战胜 Q1 的,Q1 可是齐王的最快的马耶,齐王剩下的那些马里,怎么可能还有比 T2 更强的马?
所以,没必要节约,最后我们得出的策略就是:
将齐王和田忌的马按照战斗力排序,然后按照排名一一对比。如果田忌的马能赢,那就比赛,如果赢不了,那就换个垫底的来送人头,保存实力。
上述思路的代码逻辑如下:
int n = sizeof(nums1) / sizeof(nums1[0]);
sort(nums1, nums1 + n); // 田忌的马
sort(nums2, nums2 + n); // 齐王的马
// 从最快的马开始比
for (int i = n - 1; i >= 0; i--) {
if (nums1[i] > nums2[i]) {
// 比得过,跟他比
} else {
// 比不过,换个垫底的来送人头
}
}
根据这个思路,我们需要对两个数组排序,但是 nums2 中元素的顺序不能改变,因为计算结果的顺序依赖 nums2 的顺序,所以不能直接对 nums2 进行排序,而是利用其他数据结构来辅助。
class Solution {
public:
vector<int> advantageCount(vector<int>& nums1, vector<int>& nums2) {
int n = nums1.size();
// 给 nums2 降序排序
vector<pair<int, int>> maxpq;
for (int i = 0; i < n; i++) {
maxpq.push_back({nums2[i], i});
}
sort(maxpq.begin(), maxpq.end(), greater<pair<int, int>>());
// 给 nums1 升序排序
sort(nums1.begin(), nums1.end());
// nums1[left] 是最小值,nums1[right] 是最大值
int left = 0, right = n - 1;
vector<int> res(n);
for (auto& p : maxpq) {
// maxval 是 nums2 中的最大值,i 是对应索引
int i = p.second, maxval = p.first;
if (maxval < nums1[right]) {
// 如果 nums1[right] 能胜过 maxval,那就自己上
res[i] = nums1[right];
right--;
} else {
// 否则用最小值混一下,养精蓄锐
res[i] = nums1[left];
left++;
}
}
return res;
}
};
二叉树算法
二叉树(思路篇)
二叉树解决总纲领:
1、是否可以通过遍历一遍二叉树得到答案?如果可以,用一个 traverse 函数配合外部变量来实现,这叫「遍历」的思维模式。
2、是否可以定义一个递归函数,通过子问题(子树)的答案推导出原问题的答案?如果可以,写出这个递归函数的定义,并充分利用这个函数的返回值,这叫「分解问题」的思维模式。
无论使用哪种思维模式,你都需要思考:
如果单独抽出一个二叉树节点,它需要做什么事情?需要在什么时候(前/中/后序位置)做?其他的节点不用你操心,递归函数会帮你在所有节点上执行相同的操作。
翻转二叉树
题目
输入一个二叉树根节点 root,让你把整棵树镜像翻转,比如输入的二叉树如下:
4
/ \
2 7
/ \ / \
1 3 6 9
算法原地翻转二叉树,使得以 root 为根的树变成:
4
/ \
7 2
/ \ / \
9 6 3 1
不难发现,只要把二叉树上的每一个节点的左右子节点进行交换,最后的结果就是完全翻转之后的二叉树。
思路
1、这题能不能用「遍历」的思维模式解决?
可以,我写一个 traverse 函数遍历每个节点,让每个节点的左右子节点颠倒过来就行了。
单独抽出一个节点,需要让它做什么?让它把自己的左右子节点交换一下。
需要在什么时候做?好像前中后序位置都可以。
综上,可以写出如下解法代码:
class Solution {
public:
// 主函数
TreeNode* invertTree(TreeNode* root) {
// 遍历二叉树,交换每个节点的子节点
if(root != NULL) traverse(root);
return root;
}
// 二叉树遍历函数
void traverse(TreeNode* root) {
if(root != NULL) {
/**** 前序位置 ****/
// 每一个节点需要做的事就是交换它的左右子节点
TreeNode* tmp = root->left;
root->left = root->right;
root->right = tmp;
// 遍历框架,去遍历左右子树的节点
traverse(root->left);
traverse(root->right);
}
}
};
你把前序位置的代码移到后序位置也可以,但是直接移到中序位置是不行的,需要稍作修改,这应该很容易看出来吧,我就不说了。(其实就是递归函数传入的参数要一样)
// 遍历框架,去遍历左右子树的节点
traverse(root->left);
TreeNode* tmp = root->left;
root->left = root->right;
root->right = tmp;
traverse(root->left);
2、这题能不能用「分解问题」的思维模式解决?
我们尝试给 invertTree 函数赋予一个定义:将以 root 为根的这棵二叉树翻转,返回翻转后的二叉树的根节点
然后思考,对于某一个二叉树节点 x 执行 invertTree(x),你能利用这个递归函数的定义做点啥?
我可以用 invertTree(x.left) 先把 x 的左子树翻转,再用 invertTree(x.right) 把 x 的右子树翻转,最后把 x 的左右子树交换,这恰好完成了以 x 为根的整棵二叉树的翻转,即完成了 invertTree(x) 的定义。
class Solution {
public:
// 定义:将以 root 为根的这棵二叉树翻转,返回翻转后的二叉树的根节点
TreeNode* invertTree(TreeNode* root) {
if (root == nullptr) {
return nullptr;
}
// 利用函数定义,先翻转左右子树
TreeNode* left = invertTree(root->left);
TreeNode* right = invertTree(root->right);
// 然后交换左右子节点
root->left = right;
root->right = left;
// 和定义逻辑自恰:以 root 为根的这棵二叉树已经被翻转,返回 root
return root;
}
};
这种「分解问题」的思路,核心在于你要给递归函数一个合适的定义,然后用函数的定义来解释你的代码;如果你的逻辑成功自恰,那么说明你这个算法是正确的。
填充节点的右侧指针
题目
给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
struct Node {
int val;
Node *left;
Node *right;
Node *next;
}
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。初始状态下,所有 next 指针都被设置为 NULL。
示例 1:

输入:root = [1,2,3,4,5,6,7]
输出:[1,#,2,3,#,4,5,6,7,#]
解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。序列化的输出按层序遍历排列,同一层节点由 next 指针连接,'#' 标志着每一层的结束。
示例 2:
输入:root = []
输出:[]
提示:
- 树中节点的数量在
[0, 212 - 1]范围内 -1000 <= node.val <= 1000
进阶:
- 你只能使用常量级额外空间。
- 使用递归解题也符合要求,本题中递归程序占用的栈空间不算做额外的空间复杂度。
思路
题目的意思就是把二叉树的每一层节点都用 next 指针连接起来:
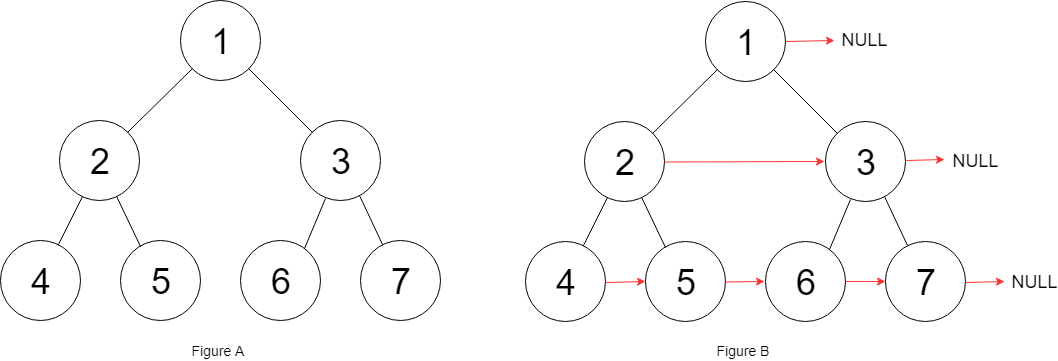
而且题目说了,输入是一棵「完美二叉树」,形象地说整棵二叉树是一个正三角形,除了最右侧的节点 next 指针会指向 null,其他节点的右侧一定有相邻的节点。
1、这题能不能用「遍历」的思维模式解决?
很显然,一定可以。
每个节点要做的事也很简单,把自己的 next 指针指向右侧节点就行了。
也许你会模仿上一道题,直接写出如下代码:
// 二叉树遍历函数
void traverse(TreeNode* root) {
if (root == NULL || root->left == NULL) {
return;
}
// 把左子节点的 next 指针指向右子节点
root->left->next = root->right;
traverse(root->left);
traverse(root->right);
}
但是,这段代码其实有很大问题,因为它只能把相同父节点的两个节点穿起来
节点 5 和节点 6 不属于同一个父节点,那么按照这段代码的逻辑,它俩就没办法被穿起来,这是不符合题意的,但是问题出在哪里?
传统的 traverse 函数是遍历二叉树的所有节点,但现在我们想遍历的其实是两个相邻节点之间的「空隙」。
所以我们可以在二叉树的基础上进行抽象,你把图中的每一个方框看做一个节点:

这样,一棵二叉树被抽象成了一棵三叉树,三叉树上的每个节点就是原先二叉树的两个相邻节点。
现在,我们只要实现一个 traverse 函数来遍历这棵三叉树,每个「三叉树节点」需要做的事就是把自己内部的两个二叉树节点穿起来:
class Solution {
public:
// 主函数
Node* connect(Node* root) {
if (root == nullptr) return nullptr;
// 遍历「三叉树」,连接相邻节点
traverse(root->left, root->right);
return root;
}
// 三叉树遍历框架
void traverse(Node* node1, Node* node2) {
if (node1 == nullptr || node2 == nullptr) {
return;
}
/**** 前序位置 ****/
// 将传入的两个节点穿起来
node1->next = node2;
// 连接相同父节点的两个子节点
traverse(node1->left, node1->right);
traverse(node2->left, node2->right);
// 连接跨越父节点的两个子节点
traverse(node1->right, node2->left);
}
};
这样,traverse 函数遍历整棵「三叉树」,将所有相邻节的二叉树节点都连接起来,也就避免了我们之前出现的问题,把这道题完美解决。
2、这题能不能用「分解问题」的思维模式解决?
嗯,好像没有什么特别好的思路,所以这道题无法使用「分解问题」的思维来解决。
将二叉树展开为链表
给你二叉树的根结点 root ,请你将它展开为一个单链表:
- 展开后的单链表应该同样使用
TreeNode,其中right子指针指向链表中下一个结点,而左子指针始终为null。 - 展开后的单链表应该与二叉树 先序遍历 顺序相同。
示例 1:
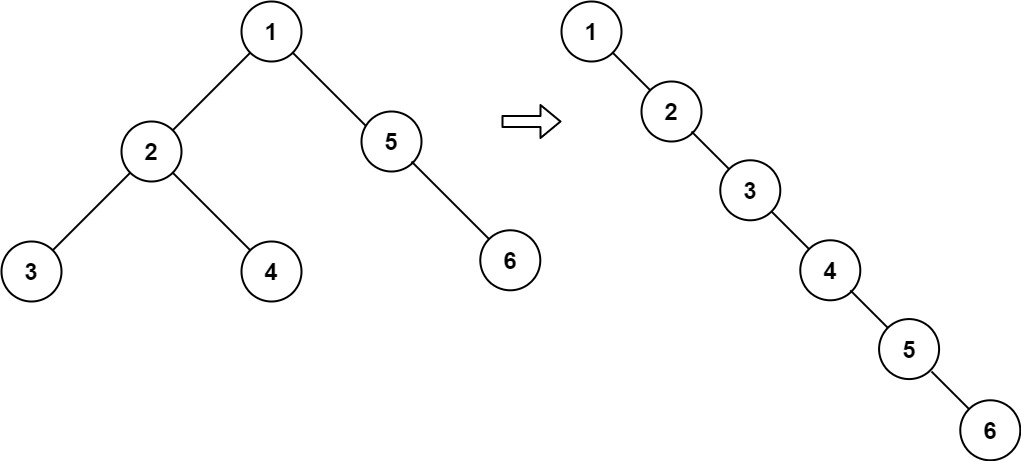
输入:root = [1,2,5,3,4,null,6]
输出:[1,null,2,null,3,null,4,null,5,null,6]
示例 2:
输入:root = []
输出:[]
示例 3:
输入:root = [0]
输出:[0]
提示:
- 树中结点数在范围
[0, 2000]内 -100 <= Node.val <= 100
进阶:你可以使用原地算法(O(1) 额外空间)展开这棵树吗?
1、这题能不能用「遍历」的思维模式解决?
乍一看感觉是可以的:对整棵树进行前序遍历,一边遍历一边构造出一条「链表」就行了:
// 虚拟头节点,dummy.right 就是结果
TreeNode* dummy = new TreeNode(-1);
// 用来构建链表的指针
TreeNode* p = dummy;
void traverse(TreeNode* root) {
if (root == nullptr) {
return;
}
// 前序位置
p->right = new TreeNode(root->val);
p = p->right;
traverse(root->left);
traverse(root->right);
}
但是注意 flatten 函数的签名,返回类型为 void,也就是说题目希望我们在原地把二叉树拉平成链表。这样一来,没办法通过简单的二叉树遍历来解决这道题了。
2、这题能不能用「分解问题」的思维模式解决?
我们尝试给出 flatten 函数的定义:输入节点 root,然后 root 为根的二叉树就会被拉平为一条链表
有了这个函数定义,如何按题目要求把一棵树拉平成一条链表?
对于一个节点 x,可以执行以下流程:
1、先利用 flatten(x.left) 和 flatten(x.right) 将 x 的左右子树拉平。
2、将 x 的右子树接到左子树下方,然后将整个左子树作为右子树。

class Solution {
public:
// 定义:将以 root 为根的树拉平为链表
void flatten(TreeNode* root) {
// base case
if (root == nullptr) return;
// 利用定义,把左右子树拉平
flatten(root->left);
flatten(root->right);
/**** 后序遍历位置 ****/
// 1、左右子树已经被拉平成一条链表
TreeNode* left = root->left;
TreeNode* right = root->right;
// 2、将左子树作为右子树
root->left = nullptr;
root->right = left;
// 3、将原先的右子树接到当前右子树的末端
TreeNode* p = root;
while (p->right != nullptr) {
p = p->right;
}
p->right = right;
}
};
你看,这就是递归的魅力,你说 flatten 函数是怎么把左右子树拉平的?
不容易说清楚,但是只要知道 flatten 的定义如此并利用这个定义,让每一个节点做它该做的事情,然后 flatten 函数就会按照定义工作。
至此,这道题也解决了,我们前文 k个一组翻转链表 的递归思路和本题也有一些类似。
二叉树(构造篇)
二叉树的构造问题一般都是使用「分解问题」的思路:构造整棵树 = 根节点 + 构造左子树 + 构造右子树。
构造最大二叉树
题目
给定一个不重复的整数数组 nums 。 最大二叉树 可以用下面的算法从 nums 递归地构建:
- 创建一个根节点,其值为
nums中的最大值。 - 递归地在最大值 左边 的 子数组前缀上 构建左子树。
- 递归地在最大值 右边 的 子数组后缀上 构建右子树。
返回 nums 构建的 *最大二叉树* 。
示例 1:

输入:nums = [3,2,1,6,0,5]
输出:[6,3,5,null,2,0,null,null,1]
解释:递归调用如下所示:
- [3,2,1,6,0,5] 中的最大值是 6 ,左边部分是 [3,2,1] ,右边部分是 [0,5] 。
- [3,2,1] 中的最大值是 3 ,左边部分是 [] ,右边部分是 [2,1] 。
- 空数组,无子节点。
- [2,1] 中的最大值是 2 ,左边部分是 [] ,右边部分是 [1] 。
- 空数组,无子节点。
- 只有一个元素,所以子节点是一个值为 1 的节点。
- [0,5] 中的最大值是 5 ,左边部分是 [0] ,右边部分是 [] 。
- 只有一个元素,所以子节点是一个值为 0 的节点。
- 空数组,无子节点。
示例 2:

输入:nums = [3,2,1]
输出:[3,null,2,null,1]
提示:
1 <= nums.length <= 10000 <= nums[i] <= 1000nums中的所有整数 互不相同
思路
每个二叉树节点都可以认为是一棵子树的根节点,对于根节点,首先要做的当然是把想办法把自己先构造出来,然后想办法构造自己的左右子树。
所以,我们要遍历数组把找到最大值 maxVal,从而把根节点 root 做出来,然后对 maxVal 左边的数组和右边的数组进行递归构建,作为 root 的左右子树。
class Solution {
public:
TreeNode* constructMaximumBinaryTree(vector<int>& nums) {
return build(nums, 0, nums.size()-1);
}
private:
// 定义:将 nums[lo..hi] 构造成符合条件的树,返回根节点
TreeNode* build(vector<int>& nums, int lo, int hi) {
// base case
if (lo > hi) {
return nullptr;
}
// 找到数组中的最大值和对应的索引
int index = -1, maxVal = INT_MIN;
for (int i = lo; i <= hi; i++) {
if (maxVal < nums[i]) {
index = i;
maxVal = nums[i];
}
}
// 先构造出根节点
TreeNode* root = new TreeNode(maxVal);
// 递归调用构造左右子树
root->left = build(nums, lo, index - 1);
root->right = build(nums, index + 1, hi);
return root;
}
};
通过前序和中序遍历结果构造二叉树
题目
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
示例 1:

输入: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
输出: [3,9,20,null,null,15,7]
示例 2:
输入: preorder = [-1], inorder = [-1]
输出: [-1]
提示:
1 <= preorder.length <= 3000inorder.length == preorder.length-3000 <= preorder[i], inorder[i] <= 3000preorder和inorder均 无重复 元素inorder均出现在preorderpreorder保证 为二叉树的前序遍历序列inorder保证 为二叉树的中序遍历序列
思路
废话不多说,直接来想思路,首先思考,根节点应该做什么。
类似上一题,我们肯定要想办法确定根节点的值,把根节点做出来,然后递归构造左右子树即可。
我们先来回顾一下,前序遍历和中序遍历的结果有什么特点?
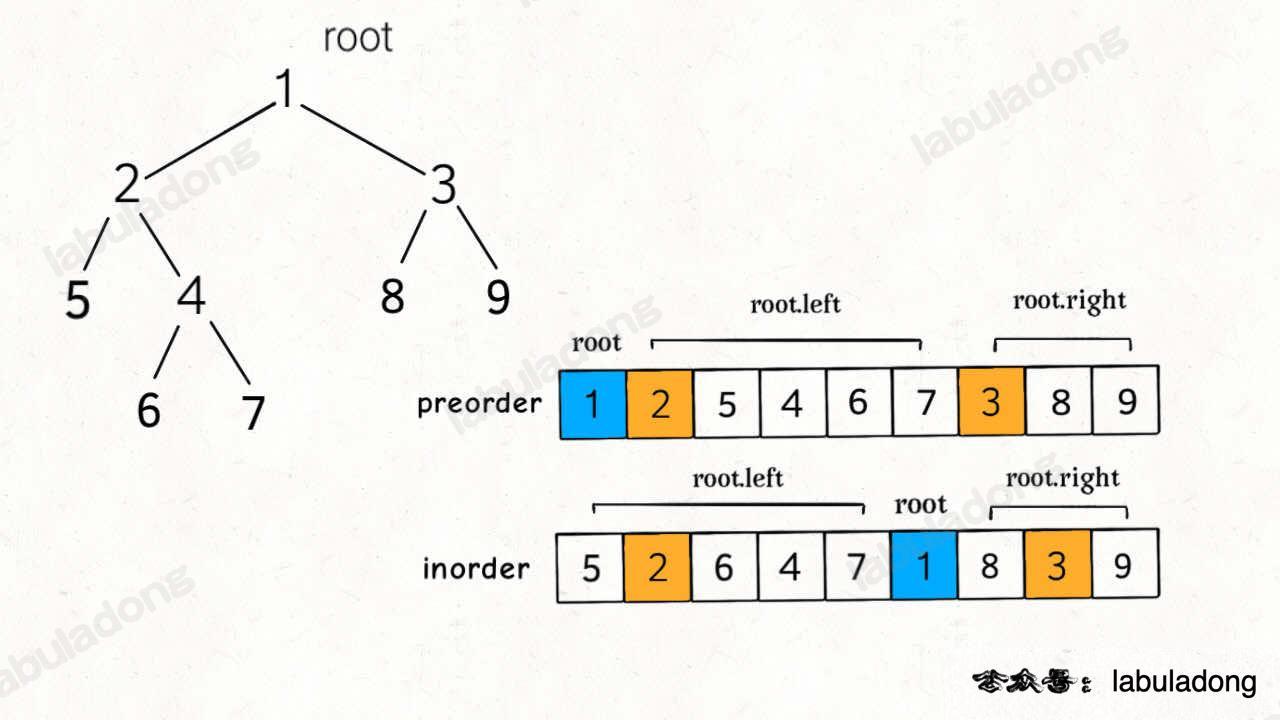
找到根节点是很简单的,前序遍历的第一个值 preorder[0] 就是根节点的值。
关键在于如何通过根节点的值,将 preorder 和 inorder 数组划分成两半,构造根节点的左右子树?
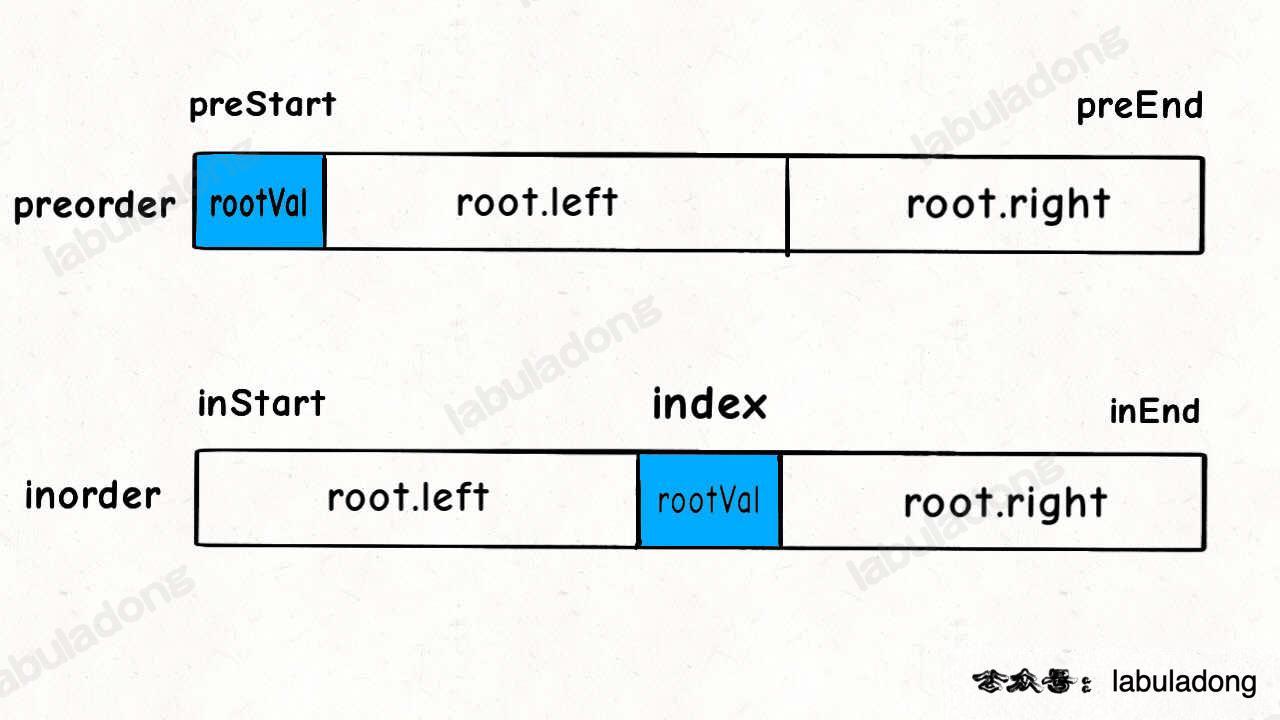
另外,也有读者注意到,通过 for 循环遍历的方式去确定 index 效率不算高,可以进一步优化。
因为题目说二叉树节点的值不存在重复,所以可以使用一个 HashMap 存储元素到索引的映射,这样就可以直接通过 HashMap 查到 rootVal 对应的 index
class Solution {
public:
// 存储 inorder 中值到索引的映射
unordered_map<int, int> valToIndex;
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
for (int i = 0; i < inorder.size(); i++) {
valToIndex[inorder[i]] = i;
}
return build(preorder, 0, preorder.size() - 1,
inorder, 0, inorder.size() - 1);
}
// build 函数的定义:
// 若前序遍历数组为 preorder[preStart..preEnd],
// 中序遍历数组为 inorder[inStart..inEnd],
// 构造二叉树,返回该二叉树的根节点
TreeNode* build(vector<int>& preorder, int preStart, int preEnd,
vector<int>& inorder, int inStart, int inEnd) {
if (preStart > preEnd) {
return NULL;
}
// root 节点对应的值就是前序遍历数组的第一个元素
int rootVal = preorder[preStart];
// rootVal 在中序遍历数组中的索引
int index = valToIndex[rootVal];
int leftSize = index - inStart;
// 先构造出当前根节点
TreeNode* root = new TreeNode(rootVal);
// 递归构造左右子树
root->left = build(preorder, preStart + 1, preStart + leftSize,
inorder, inStart, index - 1);
root->right = build(preorder, preStart + leftSize + 1, preEnd,
inorder, index + 1, inEnd);
return root;
}
};
通过后序和中序遍历结果构造二叉树
题目
给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
示例 1:
输入:inorder = [9,3,15,20,7], postorder = [9,15,7,20,3]
输出:[3,9,20,null,null,15,7]
示例 2:
输入:inorder = [-1], postorder = [-1]
输出:[-1]
提示:
1 <= inorder.length <= 3000postorder.length == inorder.length-3000 <= inorder[i], postorder[i] <= 3000inorder和postorder都由 不同 的值组成postorder中每一个值都在inorder中inorder保证是树的中序遍历postorder保证是树的后序遍历
思路
类似的,看下后序和中序遍历的特点:

这道题和上一题的关键区别是,后序遍历和前序遍历相反,根节点对应的值为 postorder 的最后一个元素。
class Solution {
public:
// 存储 inorder 中值到索引的映射
unordered_map<int, int> valToIndex;
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
for (int i = 0; i < inorder.size(); i++) {
valToIndex[inorder[i]] = i;
}
return build(inorder, 0, inorder.size() - 1,
postorder, 0, postorder.size() - 1);
}
// build 函数的定义:
// 后序遍历数组为 postorder[postStart..postEnd],
// 中序遍历数组为 inorder[inStart..inEnd],
// 构造二叉树,返回该二叉树的根节点
TreeNode* build(vector<int>& inorder, int inStart, int inEnd,
vector<int>& postorder, int postStart, int postEnd) {
if (inStart > inEnd) {
return nullptr;
}
// root 节点对应的值就是后序遍历数组的最后一个元素
int rootVal = postorder[postEnd];
// rootVal 在中序遍历数组中的索引
int index = valToIndex[rootVal];
// 左子树的节点个数
int leftSize = index - inStart;
TreeNode* root = new TreeNode(rootVal);
// 递归构造左右子树
root->left = build(inorder, inStart, index - 1,
postorder, postStart, postStart + leftSize - 1);
root->right = build(inorder, index + 1, inEnd,
postorder, postStart + leftSize, postEnd - 1);
return root;
}
};
通过前序和后序遍历结果构造二叉树
题目
给你输入二叉树的前序和后序遍历结果,让你还原二叉树的结构。
如果有多种可能的还原结果,你可以返回任意一种。
思路
这道题和前两道题有一个本质的区别:
通过前序中序,或者后序中序遍历结果可以确定唯一一棵原始二叉树,但是通过前序后序遍历结果无法确定唯一的原始二叉树。
为什么呢?我们说过,构建二叉树的套路很简单,先找到根节点,然后找到并递归构造左右子树即可。
前两道题,可以通过前序或者后序遍历结果找到根节点,然后根据中序遍历结果确定左右子树(题目说了树中没有 val 相同的节点)。
这道题,你可以确定根节点,但是无法确切的知道左右子树有哪些节点。
不过话说回来,用后序遍历和前序遍历结果还原二叉树,解法逻辑上和前两道题差别不大,也是通过控制左右子树的索引来构建:
1、首先把前序遍历结果的第一个元素或者后序遍历结果的最后一个元素确定为根节点的值。
2、然后把前序遍历结果的第二个元素作为左子树的根节点的值。
3、在后序遍历结果中寻找左子树根节点的值,从而确定了左子树的索引边界,进而确定右子树的索引边界,递归构造左右子树即可。

class Solution {
// 存储 postorder 中值到索引的映射
unordered_map<int, int> valToIndex;
public:
TreeNode* constructFromPrePost(vector<int>& preorder, vector<int>& postorder) {
for (int i = 0; i < postorder.size(); i++) {
valToIndex[postorder[i]] = i;
}
return build(preorder, 0, preorder.size() - 1,
postorder, 0, postorder.size() - 1);
}
// 定义:根据 preorder[preStart..preEnd] 和 postorder[postStart..postEnd]
// 构建二叉树,并返回根节点。
TreeNode* build(vector<int>& preorder, int preStart, int preEnd,
vector<int>& postorder, int postStart, int postEnd) {
if (preStart > preEnd) {
return nullptr;
}
if (preStart == preEnd) {
return new TreeNode(preorder[preStart]);
}
// root 节点对应的值就是前序遍历数组的第一个元素
int rootVal = preorder[preStart];
// root.left 的值是前序遍历第二个元素
// 通过前序和后序遍历构造二叉树的关键在于通过左子树的根节点
// 确定 preorder 和 postorder 中左右子树的元素区间
int leftRootVal = preorder[preStart + 1];
// leftRootVal 在后序遍历数组中的索引
int index = valToIndex[leftRootVal];
// 左子树的元素个数
int leftSize = index - postStart + 1;
// 先构造出当前根节点
TreeNode* root = new TreeNode(rootVal);
// 递归构造左右子树
// 根据左子树的根节点索引和元素个数推导左右子树的索引边界
root->left = build(preorder, preStart + 1, preStart + leftSize,
postorder, postStart, index);
root->right = build(preorder, preStart + leftSize + 1, preEnd,
postorder, index + 1, postEnd - 1);
return root;
}
};
代码和前两道题非常类似,我们可以看着代码思考一下,为什么通过前序遍历和后序遍历结果还原的二叉树可能不唯一呢?
关键在这一句:
int leftRootVal = preorder[preStart + 1];
我们假设前序遍历的第二个元素是左子树的根节点,但实际上左子树有可能是空指针,那么这个元素就应该是右子树的根节点。由于这里无法确切进行判断,所以导致了最终答案的不唯一。
至此,通过前序和后序遍历结果还原二叉树的问题也解决了。
二叉搜索树(特性篇)
寻找第K小的元素
题目
给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 个最小元素(从 1 开始计数)。
示例 1:
输入:root = [3,1,4,null,2], k = 1
输出:1
示例 2:
输入:root = [5,3,6,2,4,null,null,1], k = 3
输出:3
提示:
- 树中的节点数为
n。 1 <= k <= n <= 1040 <= Node.val <= 104
进阶:如果二叉搜索树经常被修改(插入/删除操作)并且你需要频繁地查找第 k 小的值,你将如何优化算法?
思路
这个需求很常见吧,一个直接的思路就是升序排序,然后找第 k 个元素呗。BST 的中序遍历其实就是升序排序的结果,找第 k 个元素肯定不是什么难事。
按照这个思路,可以直接写出代码:
class Solution {
private:
// 记录结果
int res = 0;
// 记录当前元素的排名
int rank = 0;
void traverse(TreeNode* root, int k) {
if (root == nullptr) {
return;
}
traverse(root->left, k);
// 中序代码位置
rank++;
if (k == rank) {
// 找到第 k 小的元素
res = root->val;
return;
}
traverse(root->right, k);
}
public:
int kthSmallest(TreeNode* root, int k) {
// 利用 BST 的中序遍历特性
traverse(root, k);
return res;
}
};
拓展:如果让你实现一个在二叉搜索树中通过排名计算对应元素的方法
select(int k),你会怎么设计?
如果按照我们刚才说的方法,利用「BST 中序遍历就是升序排序结果」这个性质,每次寻找第 k 小的元素都要中序遍历一次,最坏的时间复杂度是 O(N),N 是 BST 的节点个数。
要知道 BST 性质是非常牛逼的,像红黑树这种改良的自平衡 BST,增删查改都是 O(logN) 的复杂度,让你算一个第 k 小元素,时间复杂度竟然要 O(N),有点低效了。
所以说,计算第 k 小元素,最好的算法肯定也是对数级别的复杂度,不过这个依赖于 BST 节点记录的信息有多少。
我们想一下 BST 的操作为什么这么高效?就拿搜索某一个元素来说,BST 能够在对数时间找到该元素的根本原因还是在 BST 的定义里,左子树小右子树大嘛,所以每个节点都可以通过对比自身的值判断去左子树还是右子树搜索目标值,从而避免了全树遍历,达到对数级复杂度。
那么回到这个问题,想找到第 k 小的元素,或者说找到排名为 k 的元素,如果想达到对数级复杂度,关键也在于每个节点得知道他自己排第几。
比如说你让我查找排名为 k 的元素,当前节点知道自己排名第 m,那么我可以比较 m 和 k 的大小:
1、如果 m == k,显然就是找到了第 k 个元素,返回当前节点就行了。
2、如果 k < m,那说明排名第 k 的元素在左子树,所以可以去左子树搜索第 k 个元素。
3、如果 k > m,那说明排名第 k 的元素在右子树,所以可以去右子树搜索第 k - m - 1 个元素。
这样就可以将时间复杂度降到 O(logN) 了。
那么,如何让每一个节点知道自己的排名呢?
这就是我们之前说的,需要在二叉树节点中维护额外信息。每个节点需要记录,以自己为根的这棵二叉树有多少个节点。
也就是说,我们 TreeNode 中的字段应该如下:
class TreeNode {
public:
int val;
// 以该节点为根的树的节点总数
int size;
TreeNode* left;
TreeNode* right;
};
有了 size 字段,外加 BST 节点左小右大的性质,对于每个节点 node 就可以通过 node.left 推导出 node 的排名,从而做到我们刚才说到的对数级算法。
当然,size 字段需要在增删元素的时候需要被正确维护,力扣提供的 TreeNode 是没有 size 这个字段的,所以我们这道题就只能利用 BST 中序遍历的特性实现了,但是我们上面说到的优化思路是 BST 的常见操作,还是有必要理解的。
BST转化累加树
题目
给出二叉 搜索 树的根节点,该树的节点值各不相同,请你将其转换为累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
提醒一下,二叉搜索树满足下列约束条件:
- 节点的左子树仅包含键 小于 节点键的节点。
- 节点的右子树仅包含键 大于 节点键的节点。
- 左右子树也必须是二叉搜索树。
注意:本题和 1038: https://leetcode-cn.com/problems/binary-search-tree-to-greater-sum-tree/ 相同
示例 1:
输入:[4,1,6,0,2,5,7,null,null,null,3,null,null,null,8]
输出:[30,36,21,36,35,26,15,null,null,null,33,null,null,null,8]
示例 2:
输入:root = [0,null,1]
输出:[1,null,1]
示例 3:
输入:root = [1,0,2]
输出:[3,3,2]
示例 4:
输入:root = [3,2,4,1]
输出:[7,9,4,10]
提示:
- 树中的节点数介于
0和104之间。 - 每个节点的值介于
-104和104之间。 - 树中的所有值 互不相同 。
- 给定的树为二叉搜索树。
思路
按照二叉树的通用思路,需要思考每个节点应该做什么,但是这道题上很难想到什么思路。
BST 的每个节点左小右大,这似乎是一个有用的信息,既然累加和是计算大于等于当前值的所有元素之和,那么每个节点都去计算右子树的和,不就行了吗?
这是不行的。对于一个节点来说,确实右子树都是比它大的元素,但问题是它的父节点也可能是比它大的元素呀?这个没法确定的,我们又没有触达父节点的指针,所以二叉树的通用思路在这里用不了。
此路不通,我们不妨换一个思路,还是利用 BST 的中序遍历特性。
刚才我们说了 BST 的中序遍历代码可以升序打印节点的值
那如果我想降序打印节点的值怎么办?
很简单,只要把递归顺序改一下就行了
这段代码可以降序打印 BST 节点的值,如果维护一个外部累加变量 sum,然后把 sum 赋值给 BST 中的每一个节点,不就将 BST 转化成累加树了吗?
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode* convertBST(TreeNode* root) {
traverse(root);
return root;
}
private:
// 记录累加和
int sum = 0;
void traverse(TreeNode* root) {
if (root == nullptr) {
return;
}
traverse(root->right);
// 维护累加和
sum += root->val;
// 将 BST 转化成累加树
root->val = sum;
traverse(root->left);
}
};
二叉搜索树(基操篇)
BST 的基础操作:判断 BST 的合法性、增、删、查。其中「删」和「判断合法性」略微复杂。
BST 的基础操作主要依赖「左小右大」的特性,可以在二叉树中做类似二分搜索的操作,寻找一个元素的效率很高。
判断BST的合法性
按照 BST 左小右大的特性,每个节点想要判断自己是否是合法的 BST 节点,要做的事不就是比较自己和左右孩子吗?感觉应该这样写代码:
bool isValidBST(TreeNode* root) {
if (root == nullptr) return true;
// root 的左边应该更小
if (root->left != nullptr && root->left->val >= root->val)
return false;
// root 的右边应该更大
if (root->right != nullptr && root->right->val <= root->val)
return false;
return isValidBST(root->left)
&& isValidBST(root->right);
}
但是这个算法出现了错误,BST 的每个节点应该要小于右边子树的所有节点,下面这个二叉树显然不是 BST,因为节点 10 的右子树中有一个节点 6,但是我们的算法会把它判定为合法 BST:

出现问题的原因在于,对于每一个节点 root,代码值检查了它的左右孩子节点是否符合左小右大的原则;但是根据 BST 的定义,root 的整个左子树都要小于 root.val,整个右子树都要大于 root.val。
问题是,对于某一个节点 root,他只能管得了自己的左右子节点,怎么把 root 的约束传递给左右子树呢?请看正确的代码:
bool isValidBST(TreeNode* root) {
return isValidBST(root, nullptr, nullptr);
}
// 限定以 root 为根的子树节点必须满足 max->val > root->val > min->val
bool isValidBST(TreeNode* root, TreeNode* min, TreeNode* max) {
// base case
if (root == nullptr) return true;
// 若 root->val 不符合 max 和 min 的限制,说明不是合法 BST
if (min != nullptr && root->val <= min->val) return false;
if (max != nullptr && root->val >= max->val) return false;
// 限定左子树的最大值是 root->val,右子树的最小值是 root->val
return isValidBST(root->left, min, root)
&& isValidBST(root->right, root, max);
}
我们通过使用辅助函数,增加函数参数列表,在参数中携带额外信息,将这种约束传递给子树的所有节点,这也是二叉树算法的一个小技巧吧。
在BST中搜索元素
题目
在 BST 中搜索值为 target 的节点
思路
不需要递归地搜索两边,类似二分查找思想,根据 target 和 root.val 的大小比较,就能排除一边。
TreeNode* searchBST(TreeNode* root, int target) {
if (root == nullptr) {
return nullptr;
}
// 去左子树搜索
if (root->val > target) {
return searchBST(root->left, target);
}
// 去右子树搜索
if (root->val < target) {
return searchBST(root->right, target);
}
return root;
}
在BST中插入一个数
对数据结构的操作无非遍历 + 访问,遍历就是「找」,访问就是「改」。具体到这个问题,插入一个数,就是先找到插入位置,然后进行插入操作。
上一个问题,我们总结了 BST 中的遍历框架,就是「找」的问题。直接套框架,加上「改」的操作即可。一旦涉及「改」,就类似二叉树的构造问题,函数要返回 TreeNode 类型,并且要对递归调用的返回值进行接收。
TreeNode* insertIntoBST(TreeNode* root, int val) {
// 找到空位置插入新节点
if (root == nullptr) return new TreeNode(val);
// if (root->val == val)
// BST 中一般不会插入已存在元素
if (root->val < val)
root->right = insertIntoBST(root->right, val);
if (root->val > val)
root->left = insertIntoBST(root->left, val);
return root;
}
在BST中删除一个数
这个问题稍微复杂,跟插入操作类似,先「找」再「改」,先把框架写出来再说:
TreeNode* deleteNode(TreeNode* root, int key) {
if (root->val == key) {
// 找到啦,进行删除
} else if (root->val > key) {
// 去左子树找
root->left = deleteNode(root->left, key);
} else if (root->val < key) {
// 去右子树找
root->right = deleteNode(root->right, key);
}
return root;
}
找到目标节点了,比方说是节点 A,如何删除这个节点,这是难点。因为删除节点的同时不能破坏 BST 的性质。有三种情况,用图片来说明。
情况 1:A 恰好是末端节点,两个子节点都为空,那么它可以当场去世了。
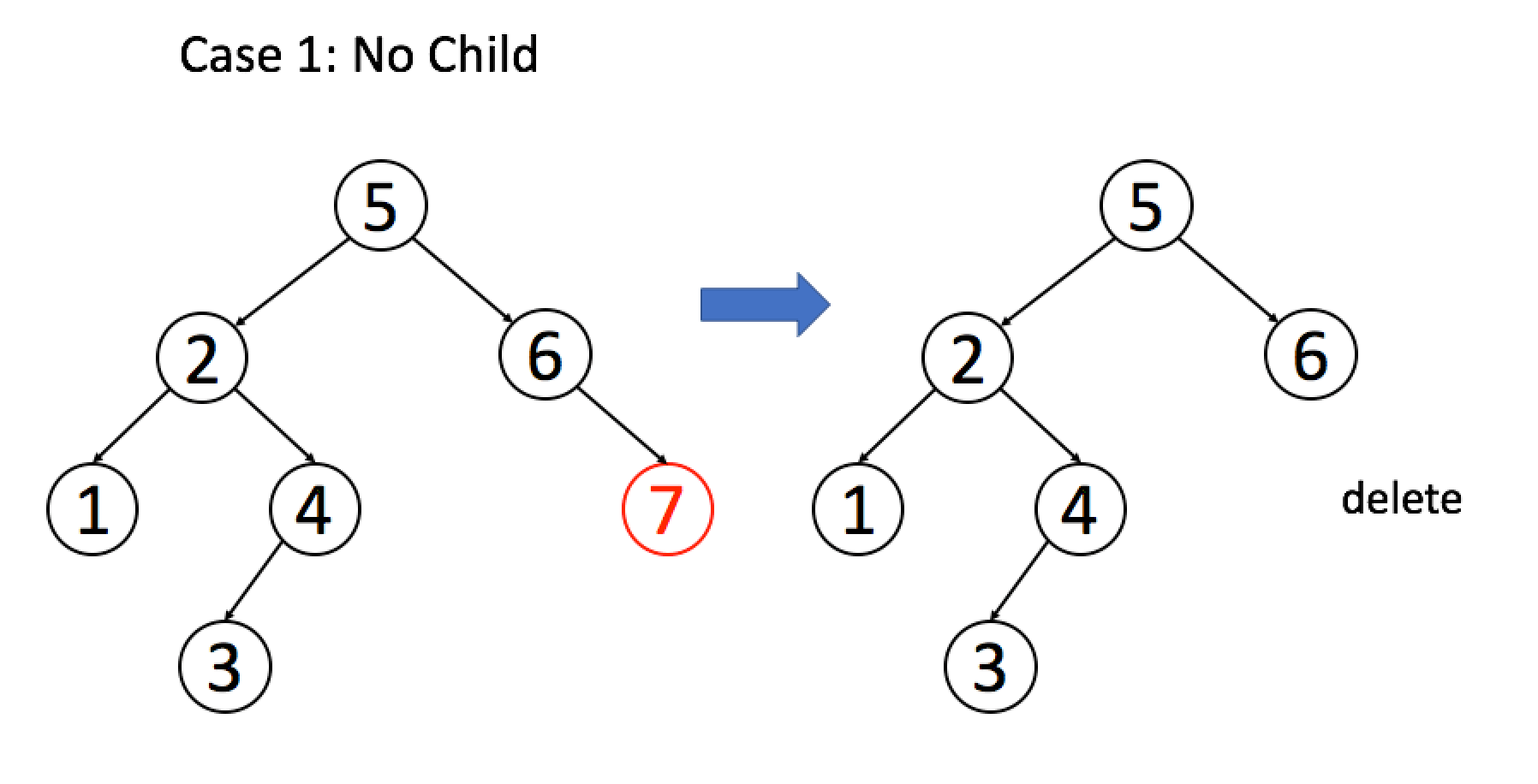
if (root->left == null && root->right == null)
return null;
情况 2:A 只有一个非空子节点,那么它要让这个孩子接替自己的位置。

// 排除了情况 1 之后
if (root->left == null) return root->right;
if (root->right == null) return root->left;
情况 3:A 有两个子节点,麻烦了,为了不破坏 BST 的性质,A 必须找到左子树中最大的那个节点,或者右子树中最小的那个节点来接替自己。我们以第二种方式讲解。
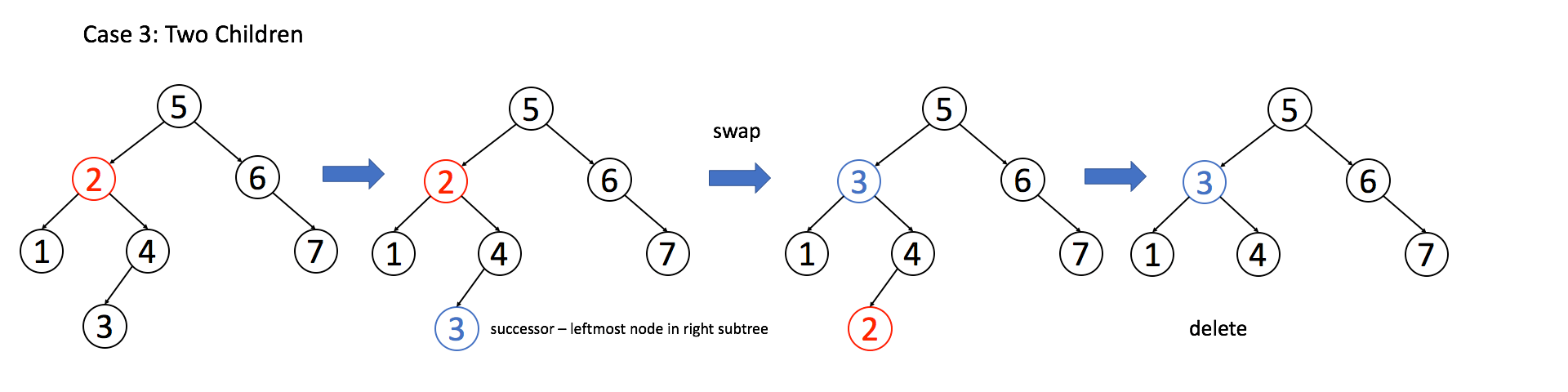
if (root->left != null && root->right != null) {
// 找到右子树的最小节点
TreeNode* minNode = getMin(root->right);
// 把 root 改成 minNode
root->val = minNode->val;
// 转而去删除 minNode
root->right = deleteNode(root->right, minNode->val);
}
// 在 BST 中删除节点
TreeNode deleteNode(TreeNode root, int key) {
// 当根节点为空,则直接返回 null
if (root == null) return null;
if (root.val == key) {
// 当节点为叶子节点或者只有一个子节点时,直接返回该子节点
if (root.left == null) return root.right;
if (root.right == null) return root.left;
// 当节点有两个子节点时,用其右子树最小的节点代替该节点
TreeNode minNode = getMin(root.right);
root.right = deleteNode(root.right, minNode.val);
minNode.left = root.left;
minNode.right = root.right;
root = minNode;
} else if (root.val > key) {
// 删除节点在左子树中
root.left = deleteNode(root.left, key);
} else if (root.val < key) {
// 删除节点在右子树中
root.right = deleteNode(root.right, key);
}
return root;
}
// 获取以 node 为根节点的 BST 中最小的节点
TreeNode getMin(TreeNode node) {
while (node.left != null) node = node.left;
return node;
}
这样,删除操作就完成了。注意一下,上述代码在处理情况 3 时通过一系列略微复杂的链表操作交换 root 和 minNode 两个节点:
// 处理情况 3
// 获得右子树最小的节点
TreeNode minNode = getMin(root.right);
// 删除右子树最小的节点
root.right = deleteNode(root.right, minNode.val);
// 用右子树最小的节点替换 root 节点
minNode.left = root.left;
minNode.right = root.right;
root = minNode;
有的读者可能会疑惑,替换 root 节点为什么这么麻烦,直接改 val 字段不就行了?看起来还更简洁易懂:
// 处理情况 3
// 获得右子树最小的节点
TreeNode minNode = getMin(root.right);
// 删除右子树最小的节点
root.right = deleteNode(root.right, minNode.val);
// 用右子树最小的节点替换 root 节点
root.val = minNode.val;
仅对于这道算法题来说是可以的,但这样操作并不完美,我们一般不会通过修改节点内部的值来交换节点。因为在实际应用中,BST 节点内部的数据域是用户自定义的,可以非常复杂,而 BST 作为数据结构(一个工具人),其操作应该和内部存储的数据域解耦,所以我们更倾向于使用指针操作来交换节点,根本没必要关心内部数据。
最后总结一下吧
通过这篇文章,我们总结出了如下几个技巧:
1、如果当前节点会对下面的子节点有整体影响,可以通过辅助函数增长参数列表,借助参数传递信息。
2、在二叉树递归框架之上,扩展出一套 BST 代码框架:
void BST(TreeNode root, int target) {
if (root.val == target)
// 找到目标,做点什么
if (root.val < target)
BST(root.right, target);
if (root.val > target)
BST(root.left, target);
}
3、根据代码框架掌握了 BST 的增删查改操作。
如何计算完全二叉树的节点数
如果让你数一下一棵普通二叉树有多少个节点,这很简单,只要在二叉树的遍历框架上加一点代码就行了。
但是,力扣第第 222 题「完全二叉树的节点个数」给你一棵完全二叉树,让你计算它的节点个数,你会不会?算法的时间复杂度是多少?
这个算法的时间复杂度应该是 O(logN*logN),如果你心中的算法没有达到这么高效,那么本文就是给你写的。
思路分析
如果是一个普通二叉树,显然只要向下面这样遍历一边即可,时间复杂度 O(N):
int countNodes(TreeNode* root) {
if (root == nullptr) return 0;
return 1 + countNodes(root->left) + countNodes(root->right);
}
那如果是一棵满二叉树,节点总数就和树的高度呈指数关系:
int countNodes(TreeNode* root) {
int h = 0;
// 计算树的高度
while (root != nullptr) {
root = root->left;
h++;
}
// 节点总数就是 2^h - 1
return pow(2, h) - 1;
}
完全二叉树比普通二叉树特殊,但又没有满二叉树那么特殊,计算它的节点总数,可以说是普通二叉树和完全二叉树的结合版,先看代码:
int countNodes(TreeNode* root) {
TreeNode* l = root, * r = root;
// 沿最左侧和最右侧分别计算高度(因为叶子节点必在同一层,且高度差只为1)
int hl = 0, hr = 0;
while (l != nullptr) {
l = l->left;
hl++;
}
while (r != nullptr) {
r = r->right;
hr++;
}
// 如果左右侧计算的高度相同,则是一棵满二叉树
if (hl == hr) {
return pow(2, hl) - 1;
}
// 如果左右侧的高度不同,则按照普通二叉树的逻辑计算
return 1 + countNodes(root->left) + countNodes(root->right);
}
结合刚才针对满二叉树和普通二叉树的算法,上面这段代码应该不难理解,就是一个结合版,但是其中降低时间复杂度的技巧是非常微妙的。
复杂度分析
直觉感觉好像最坏情况下是 O(N*logN) 吧,因为之前的 while 需要 logN 的时间,最后要 O(N) 的时间向左右子树递归:
return 1 + countNodes(root.left) + countNodes(root.right);
关键点在于,这两个递归只有一个会真的递归下去,另一个一定会触发 hl == hr 而立即返回,不会递归下去。
为什么呢?原因如下:
一棵完全二叉树的两棵子树,至少有一棵是满二叉树:
看图就明显了吧,由于完全二叉树的性质,其子树一定有一棵是满的,所以一定会触发 hl == hr,只消耗 O(logN) 的复杂度而不会继续递归。
综上,算法的递归深度就是树的高度 O(logN),每次递归所花费的时间就是 while 循环,需要 O(logN),所以总体的时间复杂度是 O(logN*logN)。
所以说,「完全二叉树」这个概念还是有它存在的原因的,不仅适用于数组实现二叉堆,而且连计算节点总数这种看起来简单的操作都有高效的算法实现。
用栈模拟递归迭代遍历二叉树
理论上,所有递归算法都可以利用栈改成迭代的形式,因为计算机本质上就是借助栈来迭代地执行递归函数的。所以本文就来利用「栈」模拟函数递归的过程,总结一套二叉树通用迭代遍历框架。
递归框架改为迭代
如果我们想将递归算法改为迭代算法,就不能从框架上理解算法的逻辑,而要深入细节,思考计算机是如何进行递归的。
假设计算机运行函数 A,就会把 A 放到调用栈里面,如果 A 又调用了函数 B,则把 B 压在 A 上面,如果 B 又调用了 C,那就再把 C 压到 B 上面……
当 C 执行结束后,C 出栈,返回值传给 B,B 执行完后出栈,返回值传给 A,最后等 A 执行完,返回结果并出栈,此时调用栈为空,整个函数调用链结束。
我们递归遍历二叉树的函数也是一样的,当函数被调用时,被压入调用栈,当函数结束时,从调用栈中弹出。
那么我们可以写出下面这段代码模拟递归调用的过程:
#include<stack>
using namespace std;
stack<TreeNode*> stk;
void traverse(TreeNode* root) {
if (root == nullptr) return;
// 函数开始时压入调用栈
stk.push(root);
traverse(root->left);
traverse(root->right);
// 函数结束时离开调用栈
stk.pop();
}
如果在前序遍历的位置入栈,后序遍历的位置出栈,stk 中的节点变化情况就反映了 traverse 函数的递归过程(GIF 中绿色节点就是被压入栈中的节点,灰色节点就是弹出栈的节点):

简单说就是这样一个流程:
1、拿到一个节点,就一路向左遍历(因为 traverse(root.left) 排在前面),把路上的节点都压到栈里。
2、往左走到头之后就开始退栈,看看栈顶节点的右指针,非空的话就重复第 1 步。
写成迭代代码就是这样:
class Solution {
private:
stack<TreeNode*> stk;
public:
vector<int> traverse(TreeNode* root) {
pushLeftBranch(root);
while (!stk.empty()) {
TreeNode* p = stk.top();
stk.pop();
pushLeftBranch(p->right);
}
}
// 左侧树枝一撸到底,都放入栈中
void pushLeftBranch(TreeNode* p) {
while (p != nullptr) {
stk.push(p);
p = p->left;
}
}
};
上述代码虽然已经可以模拟出递归函数的运行过程,不过还没有找到递归代码中的前中后序代码位置,所以需要进一步修改。
迭代代码框架
想在迭代代码中体现前中后序遍历,关键点在哪里?
当我从栈中拿出一个节点 p,我应该想办法搞清楚这个节点 p 左右子树的遍历情况。
- 如果
p的左右子树都没有被遍历,那么现在对p进行操作就属于前序遍历代码。 - 如果
p的左子树被遍历过了,而右子树没有被遍历过,那么现在对p进行操作就属于中序遍历代码。 - 如果
p的左右子树都被遍历过了,那么现在对p进行操作就属于后序遍历代码。
上述逻辑写成伪码如下:
class Solution {
private:
stack<TreeNode*> stk;
public:
vector<int> traverse(TreeNode* root) {
pushLeftBranch(root);
vector<int> result;
while (!stk.empty()) {
TreeNode* p = stk.top();
if (p->left == nullptr) {
/*******************/
/** 中序遍历代码位置 **/
/*******************/
// 去遍历 p 的右子树
stk.pop();
pushLeftBranch(p->right);
}
else if (p->right == nullptr) {
/*******************/
/** 后序遍历代码位置 **/
/*******************/
// 以 p 为根的树遍历完了,出栈
stk.pop();
result.push_back(p->val);
}
else {
stk.pop();
stk.push(p);
pushLeftBranch(p->right);
pushLeftBranch(p->left);
}
}
return result;
}
void pushLeftBranch(TreeNode* p) {
while (p != nullptr) {
/*******************/
/** 前序遍历代码位置 **/
/*******************/
stk.push(p);
p = p->left;
}
}
};
有刚才的铺垫,这段代码应该是不难理解的,关键是如何判断 p 的左右子树到底被遍历过没有呢?
其实很简单,我们只需要维护一个 visited 指针,指向「上一次遍历完成的根节点」,就可以判断 p 的左右子树遍历情况了
下面是迭代遍历二叉树的完整代码框架:
class Solution {
private:
// 模拟函数调用栈
stack<TreeNode*> stk;
// 左侧树枝一撸到底
void pushLeftBranch(TreeNode* p) {
while (p != nullptr) {
/*******************/
/** 前序遍历代码位置 **/
/*******************/
stk.push(p);
p = p->left;
}
}
public:
vector<int> traverse(TreeNode* root) {
// 指向上一次遍历完的子树根节点
TreeNode* visited = new TreeNode(-1);
// 开始遍历整棵树
pushLeftBranch(root);
while (!stk.empty()) {
TreeNode* p = stk.top();
// p 的左子树被遍历完了,且右子树没有被遍历过
if ((p->left == nullptr || p->left == visited)
&& p->right != visited) {
/*******************/
/** 中序遍历代码位置 **/
/*******************/
// 去遍历 p 的右子树
pushLeftBranch(p->right);
}
// p 的右子树被遍历完了
if (p->right == nullptr || p->right == visited) {
/*******************/
/** 后序遍历代码位置 **/
/*******************/
// 以 p 为根的子树被遍历完了,出栈
// visited 指针指向 p
visited = p;
stk.pop();
}
}
}
};
代码中最有技巧性的是这个 visited 指针,它记录最近一次遍历完的子树根节点(最近一次 pop 出栈的节点),我们可以根据对比 p 的左右指针和 visited 是否相同来判断节点 p 的左右子树是否被遍历过,进而分离出前中后序的代码位置。
visited指针初始化指向一个新 new 出来的二叉树节点,相当于一个特殊值,目的是避免和输入二叉树中的节点重复。
只需把递归算法中的前中后序位置的代码复制粘贴到上述框架的对应位置,就可以把任意递归的二叉树算法改写成迭代形式了。
设计数据结构
队列实现栈以及栈实现队列
栈实现队列
我们使用两个栈 s1, s2 就能实现一个队列的功能(这样放置栈可能更容易理解):

当调用 push 让元素入队时,只要把元素压入 s1 即可,比如说 push 进 3 个元素分别是 1,2,3,那么底层结构就是这样:

那么如果这时候使用 peek 查看队头的元素怎么办呢?按道理队头元素应该是 1,但是在 s1 中 1 被压在栈底,现在就要轮到 s2 起到一个中转的作用了:当 s2 为空时,可以把 s1 的所有元素取出再添加进 s2,这时候 s2 中元素就是先进先出顺序了:

当 s2 中存在元素时,直接调用操作 s2 的 pop 方法,弹出的就是最先插入的元素,即实现了队列的 pop 操作。
#include <stack>
class MyQueue {
private:
std::stack<int> s1, s2;
public:
MyQueue() {
}
// 添加元素到队尾
void push(int x) {
s1.push(x);
}
// 返回队头元素
int peek() {
if (s2.empty())
// 把 s1 元素压入 s2
while (!s1.empty()) {
s2.push(s1.top());
s1.pop();
}
return s2.top();
}
// 删除队头元素并返回
int pop() {
// 先调用 peek 保证 s2 非空
peek();
int poppedValue = s2.top();
s2.pop();
return poppedValue;
}
// 判断队列是否为空
// 两个栈都为空才说明队列为空
bool empty() {
return s1.empty() && s2.empty();
}
};
至此,就用栈结构实现了一个队列,核心思想是利用两个栈互相配合。
值得一提的是,这几个操作的时间复杂度是多少呢?
有点意思的是 peek 操作,调用它时可能触发 while 循环,这样的话时间复杂度是 O(N),但是大部分情况下 while 循环不会被触发,时间复杂度是 O(1)。由于 pop 操作调用了 peek,它的时间复杂度和 peek 相同。
像这种情况,可以说它们的最坏时间复杂度是 O(N),因为包含 while 循环,可能需要从 s1 往 s2 搬移元素。
但是它们的均摊时间复杂度是 O(1),这个要这么理解:对于一个元素,最多只可能被搬运一次,也就是说 peek 操作平均到每个元素的时间复杂度是 O(1)。
用队列实现栈
先说 push API,直接将元素加入队列,同时记录队尾元素,因为队尾元素相当于栈顶元素,如果要 top 查看栈顶元素的话可以直接返回。
我们的底层数据结构是先进先出的队列,每次 pop 只能从队头取元素;但是栈是后进先出,也就是说 pop API 要从队尾取元素。
解决方法简单粗暴,把队列前面的都取出来再加入队尾,让之前的队尾元素排到队头,这样就可以取出了。
这样实现还有一点小问题就是,原来的队尾元素被推到队头并删除了,但是 top_elem 变量没有更新,我们还需要一点小修改:
class MyStack {
queue<int> q;
public:
// 添加元素到栈顶
void push(int x) {
// x 是队列的队尾,是栈的栈顶
q.push(x);
top_elem = x;
}
// 返回栈顶元素
int top() {
return top_elem;
}
bool empty() {
return q.empty();
}
// 删除栈顶的元素并返回
int pop() {
int size = q.size();
// 留下队尾 2 个元素
while (size > 2) {
q.push(q.front());
q.pop();
size--;
}
// 记录新的队尾元素
top_elem = q.front();
q.push(q.front());
q.pop();
// 删除之前的队尾元素
int target = q.front();
q.pop();
return target;
}
};
很明显,用队列实现栈的话,pop 操作时间复杂度是 O(N),其他操作都是 O(1)。
个人认为,用队列实现栈是没啥亮点的问题,但是用双栈实现队列是值得学习的。
从栈 s1 搬运元素到 s2 之后,元素在 s2 中就变成了队列的先进先出顺序,这个特性有点类似「负负得正」,确实不太容易想到。
单调栈算法模板
单调栈实际上就是栈,只是利用了一些巧妙的逻辑,使得每次新元素入栈后,栈内的元素都保持有序(单调递增或单调递减)。
单调栈用途不太广泛,只处理一类典型的问题,比如「下一个更大元素」,「上一个更小元素」等。
单调栈模板
题目
输入一个数组 nums,请你返回一个等长的结果数组,结果数组中对应索引存储着下一个更大元素,如果没有更大的元素,就存 -1。
思路
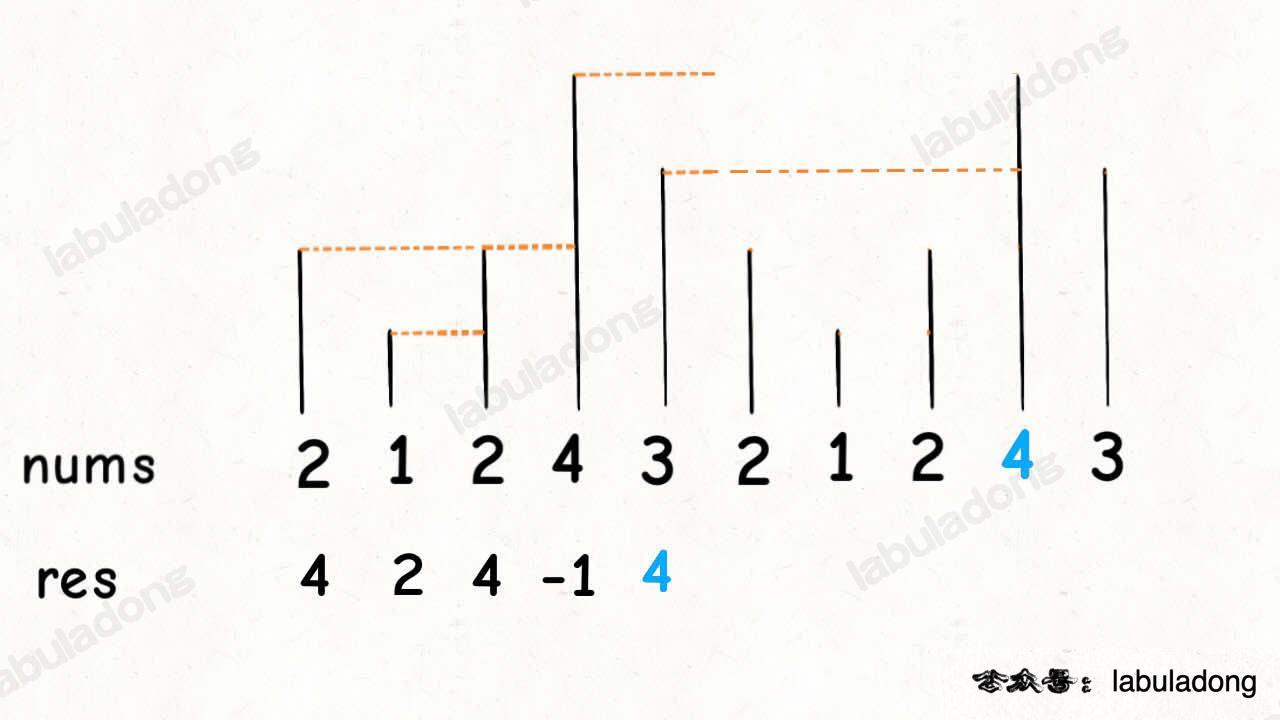
比如说,输入一个数组 nums = [2,1,2,4,3],你返回数组 [4,2,4,-1,-1]。因为第一个 2 后面比 2 大的数是 4; 1 后面比 1 大的数是 2;第二个 2 后面比 2 大的数是 4; 4 后面没有比 4 大的数,填 -1;3 后面没有比 3 大的数,填 -1。
这道题的暴力解法很好想到,就是对每个元素后面都进行扫描,找到第一个更大的元素就行了。但是暴力解法的时间复杂度是 O(n^2)。
这个问题可以这样抽象思考:把数组的元素想象成并列站立的人,元素大小想象成人的身高。这些人面对你站成一列,如何求元素「2」的下一个更大元素呢?很简单,如果能够看到元素「2」,那么他后面可见的第一个人就是「2」的下一个更大元素,因为比「2」小的元素身高不够,都被「2」挡住了,第一个露出来的就是答案。

单调栈模板
vector<int> calculateGreaterElement(vector<int>& nums) {
int n = nums.size();
// 存放答案的数组
vector<int> res(n);
stack<int> s;
// 倒着往栈里放
for (int i = n - 1; i >= 0; i--) {
// 判定个子高矮
while (!s.empty() && s.top() <= nums[i]) {
// 矮个起开,反正也被挡着了。。。
s.pop();
}
// nums[i] 身后的更大元素
res[i] = s.empty() ? -1 : s.top();
s.push(nums[i]);
}
return res;
}
这就是单调队列解决问题的模板。for 循环要从后往前扫描元素,因为我们借助的是栈的结构,倒着入栈,其实是正着出栈。while 循环是把两个「个子高」元素之间的元素排除,因为他们的存在没有意义,前面挡着个「更高」的元素,所以他们不可能被作为后续进来的元素的下一个更大元素了。
这个算法的时间复杂度不是那么直观,如果你看到 for 循环嵌套 while 循环,可能认为这个算法的复杂度也是 O(n^2),但是实际上这个算法的复杂度只有 O(n)。
分析它的时间复杂度,要从整体来看:总共有 n 个元素,每个元素都被 push 入栈了一次,而最多会被 pop 一次,没有任何冗余操作。所以总的计算规模是和元素规模 n 成正比的,也就是 O(n) 的复杂度。
问题变形
题目
nums1 中数字 x 的 下一个更大元素 是指 x 在 nums2 中对应位置 右侧 的 第一个 比 x 大的元素。
给你两个 没有重复元素 的数组 nums1 和 nums2 ,下标从 0 开始计数,其中nums1 是 nums2 的子集。
对于每个 0 <= i < nums1.length ,找出满足 nums1[i] == nums2[j] 的下标 j ,并且在 nums2 确定 nums2[j] 的 下一个更大元素 。如果不存在下一个更大元素,那么本次查询的答案是 -1 。
返回一个长度为 nums1.length 的数组 ans 作为答案,满足 ans[i] 是如上所述的 下一个更大元素 。
示例 1:
输入:nums1 = [4,1,2], nums2 = [1,3,4,2].
输出:[-1,3,-1]
解释:nums1 中每个值的下一个更大元素如下所述:
- 4 ,用加粗斜体标识,nums2 = [1,3,4,2]。不存在下一个更大元素,所以答案是 -1 。
- 1 ,用加粗斜体标识,nums2 = [1,3,4,2]。下一个更大元素是 3 。
- 2 ,用加粗斜体标识,nums2 = [1,3,4,2]。不存在下一个更大元素,所以答案是 -1 。
示例 2:
输入:nums1 = [2,4], nums2 = [1,2,3,4].
输出:[3,-1]
解释:nums1 中每个值的下一个更大元素如下所述:
- 2 ,用加粗斜体标识,nums2 = [1,2,3,4]。下一个更大元素是 3 。
- 4 ,用加粗斜体标识,nums2 = [1,2,3,4]。不存在下一个更大元素,所以答案是 -1 。
提示:
1 <= nums1.length <= nums2.length <= 10000 <= nums1[i], nums2[i] <= 104nums1和nums2中所有整数 互不相同nums1中的所有整数同样出现在nums2中
进阶:你可以设计一个时间复杂度为 O(nums1.length + nums2.length) 的解决方案吗?
思路
其实和把我们刚才的代码改一改就可以解决这道题了,因为题目说 nums1 是 nums2 的子集,那么我们先把 nums2 中每个元素的下一个更大元素算出来存到一个映射里,然后再让 nums1 中的元素去查表即可:
class Solution {
public:
vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {
// 记录 nums2 中每个元素的下一个更大元素
vector<int> greater = calculateGreaterElement(nums2);
// 转化成映射:元素 x -> x 的下一个最大元素
unordered_map<int, int> greaterMap;
for (int i = 0; i < nums2.size(); i++) {
greaterMap[nums2[i]] = greater[i];
}
// nums1 是 nums2 的子集,所以根据 greaterMap 可以得到结果
vector<int> res(nums1.size());
for (int i = 0; i < nums1.size(); i++) {
res[i] = greaterMap[nums1[i]];
}
return res;
}
vector<int> calculateGreaterElement(vector<int>& nums) {
// 见上文
}
};
题目
给你一个数组 temperatures,这个数组存放的是近几天的天气气温,你返回一个等长的数组,计算:对于每一天,你还要至少等多少天才能等到一个更暖和的气温;如果等不到那一天,填 0。
思路
比如说给你输入 temperatures = [73,74,75,71,69,76],你返回 [1,1,3,2,1,0]。因为第一天 73 华氏度,第二天 74 华氏度,比 73 大,所以对于第一天,只要等一天就能等到一个更暖和的气温,后面的同理。
这个问题本质上也是找下一个更大元素,只不过现在不是问你下一个更大元素的值是多少,而是问你当前元素距离下一个更大元素的索引距离而已。
相同的思路,直接调用单调栈的算法模板,稍作改动就可以,直接上代码吧:
class Solution {
public:
vector<int> dailyTemperatures(vector<int>& temperatures) {
int n = temperatures.size();
vector<int> res(n, 0);
// 这里放元素索引,而不是元素
stack<int> s;
/* 单调栈模板 */
for (int i = n - 1; i >= 0; i--) {
while (!s.empty() && temperatures[s.top()] <= temperatures[i]) {
s.pop();
}
// 得到索引间距
res[i] = s.empty() ? 0 : (s.top() - i);
// 将索引入栈,而不是元素
s.push(i);
}
return res;
}
};
如何处理环型数组
题目
输入一个「环形数组」,请你计算其中每个元素的下一个更大元素。
比如输入 [2,1,2,4,3],你应该返回 [4,2,4,-1,4],因为拥有了环形属性,最后一个元素 3 绕了一圈后找到了比自己大的元素 4。
思路
我们一般是通过 % 运算符求模(余数),来模拟环形特效:
#include <iostream>
using namespace std;
int main(){
int arr[5] = {1, 2, 3, 4, 5};
int n = sizeof(arr) / sizeof(arr[0]), index = 0;
while (true) {
// 在环形数组中转圈
cout << arr[index % n] << endl;
index++;
}
return 0;
}
这个问题肯定还是要用单调栈的解题模板,但难点在于,比如输入是 [2,1,2,4,3],对于最后一个元素 3,如何找到元素 4 作为下一个更大元素。
对于这种需求,常用套路就是将数组长度翻倍:
这样,元素 3 就可以找到元素 4 作为下一个更大元素了,而且其他的元素都可以被正确地计算。
有了思路,最简单的实现方式当然可以把这个双倍长度的数组构造出来,然后套用算法模板。但是,我们可以不用构造新数组,而是利用循环数组的技巧来模拟数组长度翻倍的效果。直接看代码吧:
class Solution {
public:
vector<int> nextGreaterElements(vector<int>& nums) {
int n = nums.size();
vector<int> res(n);
stack<int> s;
// 数组长度加倍模拟环形数组
for (int i = 2 * n - 1; i >= 0; i--) {
// 索引 i 要求模,其他的和模板一样
while (!s.empty() && s.top() <= nums[i % n]) {
s.pop();
}
res[i % n] = s.empty() ? -1 : s.top();
s.push(nums[i % n]);
}
return res;
}
};
这样,就可以巧妙解决环形数组的问题,时间复杂度 O(N)。
单调队列结构解决滑动窗口
单调队列:其实没啥难的,就是一个「队列」,只是使用了一点巧妙的方法,使得队列中的元素全都是单调递增(或递减)的。
为啥要发明「单调队列」这种结构呢,主要是为了解决下面这个场景:
给你一个数组 window,已知其最值为 A,如果给 window 中添加一个数 B,那么比较一下 A 和 B 就可以立即算出新的最值;但如果要从 window 数组中减少一个数,就不能直接得到最值了,因为如果减少的这个数恰好是 A,就需要遍历 window 中的所有元素重新寻找新的最值。
这个场景很常见,但不用单调队列似乎也可以,比如优先级队列也是一种特殊的队列,专门用来动态寻找最值的,我创建一个大(小)顶堆,不就可以很快拿到最大(小)值了吗?
如果单纯地维护最值的话,优先级队列很专业,队头元素就是最值。但优先级队列无法满足标准队列结构「先进先出」的时间顺序,因为优先级队列底层利用二叉堆对元素进行动态排序,元素的出队顺序是元素的大小顺序,和入队的先后顺序完全没有关系。
所以,现在需要一种新的队列结构,既能够维护队列元素「先进先出」的时间顺序,又能够正确维护队列中所有元素的最值,这就是「单调队列」结构。
比方说,你注意看前文 [滑动窗口核心框架] 讲的几道题目,每当窗口扩大(right++)和窗口缩小(left++)时,单凭移出和移入窗口的元素即可决定是否更新答案。
但本文说的那个判断一个窗口中最值的例子,无法单凭移出窗口的那个元素更新窗口的最值,除非重新遍历所有元素,但这样的话时间复杂度就上来了,这是我们不希望看到的。
题目
给你输入一个数组 nums 和一个正整数 k,有一个大小为 k 的窗口在 nums 上从左至右滑动,请你输出每次窗口中 k 个元素的最大值。

搭建解题框架
要实现的「单调队列」的 API
class MonotonicQueue {
public:
// 在队尾添加元素 n
void push(int n);
// 返回当前队列中的最大值
int max();
// 队头元素如果是 n,删除它
void pop(int n);
};
当然,这几个 API 的实现方法肯定跟一般的 Queue 不一样,不过我们暂且不管,而且认为这几个操作的时间复杂度都是 O(1),先把这道「滑动窗口」问题的解答框架搭出来:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
MonotonicQueue window;
vector<int> res;
for (int i = 0; i < nums.size(); i++) {
if (i < k - 1) {
//先把窗口的前 k - 1 填满
window.push(nums[i]);
} else {
// 窗口开始向前滑动
// 移入新元素
window.push(nums[i]);
// 将当前窗口中的最大元素记入结果
res.push_back(window.max());
// 移出最后的元素
window.pop(nums[i - k + 1]);
}
}
return res;
}

实现单调队列
观察滑动窗口的过程就能发现,实现「单调队列」必须使用一种数据结构支持在头部和尾部进行插入和删除,很明显双链表是满足这个条件的。
「单调队列」的核心思路和「单调栈」类似,push 方法依然在队尾添加元素,但是要把前面比自己小的元素都删掉:
#include<deque>
using namespace std;
class MonotonicQueue {
// 双链表,支持快速在头部和尾部增删元素
// 维护其中的元素自尾部到头部单调递增
private:
deque<int> maxq;
// 在尾部添加一个元素 n,维护 maxq 的单调性质
public:
void push(int n) {
// 将前面小于自己的元素都删除
while (!maxq.empty() && maxq.back() < n) {
maxq.pop_back();
}
maxq.push_back(n);
}
};
你可以想象,加入数字的大小代表人的体重,体重大的会把前面体重不足的压扁,直到遇到更大的量级才停住。
如果每个元素被加入时都这样操作,最终单调队列中的元素大小就会保持一个单调递减的顺序,因此我们的 max 方法可以可以这样写:
class MonotonicQueue {
// 为了节约篇幅,省略上文给出的代码部分...
public:
int max() {
// 队头的元素肯定是最大的
return maxq.front();
}
};
pop 方法在队头删除元素 n,也很好写:
class MonotonicQueue {
// 为了节约篇幅,省略上文给出的代码部分...
public:
void pop(int n) {
if (n == maxq.front()) {
maxq.pop_front();
}
}
};
之所以要判断 n == maxq.getFirst(),是因为我们想删除的队头元素 n 可能已经被「压扁」了,可能已经不存在了,所以这时候就不用删除了:
至此,单调队列设计完毕,看下完整的解题代码:
/* 单调队列的实现 */
class MonotonicQueue {
deque<int> maxq;
public:
void push(int n) {
// 将小于 n 的元素全部删除
while (!maxq.empty() && maxq.back() < n) {
maxq.pop_back();
}
// 然后将 n 加入尾部
maxq.push_back(n);
}
int max() {
return maxq.front();
}
void pop(int n) {
if (n == maxq.front()) {
maxq.pop_front();
}
}
};
class Solution {
public:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
MonotonicQueue window;
vector<int> res;
for (int i = 0; i < nums.size(); i++) {
if (i < k - 1) {
//先填满窗口的前 k - 1
window.push(nums[i]);
} else {
// 窗口向前滑动,加入新数字
window.push(nums[i]);
// 记录当前窗口的最大值
res.push_back(window.max());
// 移出旧数字
window.pop(nums[i - k + 1]);
}
}
return res;
}
};
关于单调队列 API 的时间复杂度,读者可能有疑惑:push 操作中含有 while 循环,时间复杂度应该不是 O(1) 呀,那么本算法的时间复杂度应该不是线性时间吧?
单独看 push 操作的复杂度确实不是 O(1),但是算法整体的复杂度依然是 O(N) 线性时间。要这样想,nums 中的每个元素最多被 push 和 pop 一次,没有任何多余操作,所以整体的复杂度还是 O(N)。空间复杂度就很简单了,就是窗口的大小 O(k)。
LRU算法(乐高思想)
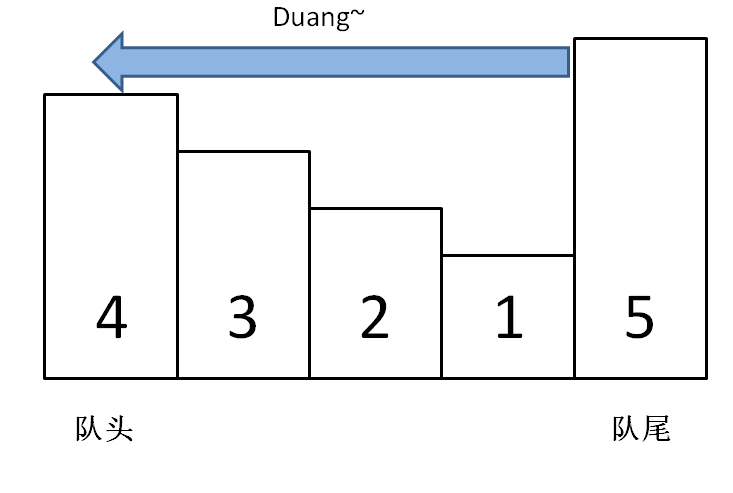
LRU 缓存淘汰算法就是一种常用策略。LRU 的全称是 Least Recently Used,也就是说我们认为最近使用过的数据应该是是「有用的」,很久都没用过的数据应该是无用的,内存满了就优先删那些很久没用过的数据。
LRU算法描述
首先要接收一个 capacity 参数作为缓存的最大容量,然后实现两个 API,一个是 put(key, val) 方法存入键值对,另一个是 get(key) 方法获取 key 对应的 val,如果 key 不存在则返回 -1。
注意哦,get 和 put 方法必须都是 O(1) 的时间复杂度。
LRU算法设计
要让 put 和 get 方法的时间复杂度为 O(1),我们可以总结出 cache 这个数据结构必要的条件:
1、显然 cache 中的元素必须有时序,以区分最近使用的和久未使用的数据,当容量满了之后要删除最久未使用的那个元素腾位置。
2、我们要在 cache 中快速找某个 key 是否已存在并得到对应的 val;
3、每次访问 cache 中的某个 key,需要将这个元素变为最近使用的,也就是说 cache 要支持在任意位置快速插入和删除元素。
那么,什么数据结构同时符合上述条件呢?哈希表查找快,但是数据无固定顺序;链表有顺序之分,插入删除快,但是查找慢。所以结合一下,形成一种新的数据结构:哈希链表 LinkedHashMap。(针对特定问题,结合基本数据结构的特性,创造新的数据结构。)
LRU 缓存算法的核心数据结构就是哈希链表,双向链表和哈希表的结合体。这个数据结构长这样:

借助这个结构,我们来逐一分析上面的 3 个条件:
1、如果我们每次默认从链表尾部添加元素,那么显然越靠尾部的元素就是最近使用的,越靠头部的元素就是最久未使用的。
2、对于某一个 key,我们可以通过哈希表快速定位到链表中的节点,从而取得对应 val。
3、链表显然是支持在任意位置快速插入和删除的,改改指针就行。只不过传统的链表无法按照索引快速访问某一个位置的元素,而这里借助哈希表,可以通过 key 快速映射到任意一个链表节点,然后进行插入和删除。
代码实现
首先,我们把 [双链表] 的节点类写出来,为了简化,key 和 val 都认为是 int 类型:
class Node {
public:
int key, val;
Node* next;
Node* prev;
Node(int k, int v){
this->key = k;
this->val = v;
}
};
然后依靠我们的 Node 类型构建一个双链表,实现几个 LRU 算法必须的 API:
class DoubleList {
private:
// 头尾虚节点
Node* head;
Node* tail;
// 链表元素数
int size;
public:
DoubleList() {
// 初始化双向链表的数据
head = new Node(0, 0);
tail = new Node(0, 0);
head->next = tail;
tail->prev = head;
size = 0;
}
// 在链表尾部添加节点 x,时间 O(1)
void addLast(Node* x) {
x->prev = tail->prev;
x->next = tail;
tail->prev->next = x;
tail->prev = x;
size++;
}
// 删除链表中的 x 节点(x 一定存在)
// 由于是双链表且给的是目标 Node 节点,时间 O(1)
void remove(Node* x) {
x->prev->next = x->next;
x->next->prev = x->prev;
size--;
}
// 删除链表中第一个节点,并返回该节点,时间 O(1)
Node* removeFirst() {
if (head->next == tail)
return nullptr;
Node* first = head->next;
remove(first);
return first;
}
// 返回链表长度,时间 O(1)
int getSize() { return size; }
};
注意我们实现的双链表 API 只能从尾部插入,也就是说靠尾部的数据是最近使用的,靠头部的数据是最久未使用的。
有了双向链表的实现,我们只需要在 LRU 算法中把它和哈希表结合起来即可,先搭出代码框架:
class LRUCache {
// key -> Node(key, val)
private HashMap<Integer, Node> map;
// Node(k1, v1) <-> Node(k2, v2)...
private DoubleList cache;
// 最大容量
private int cap;
public LRUCache(int capacity) {
this.cap = capacity;
map = new HashMap<>();
cache = new DoubleList();
}
}
先不慌去实现 LRU 算法的 get 和 put 方法。由于我们要同时维护一个双链表 cache 和一个哈希表 map,很容易漏掉一些操作,比如说删除某个 key 时,在 cache 中删除了对应的 Node,但是却忘记在 map 中删除 key。
解决这种问题的有效方法是:在这两种数据结构之上提供一层抽象 API。
说的有点玄幻,实际上很简单,就是尽量让 LRU 的主方法 get 和 put 避免直接操作 map 和 cache 的细节。我们可以先实现下面几个函数:
class LRUCache {
// 为了节约篇幅,省略上文给出的代码部分...
// 将某个 key 提升为最近使用的
private void makeRecently(int key) {
Node x = map.get(key);
// 先从链表中删除这个节点
cache.remove(x);
// 重新插到队尾
cache.addLast(x);
}
// 添加最近使用的元素
private void addRecently(int key, int val) {
Node x = new Node(key, val);
// 链表尾部就是最近使用的元素
cache.addLast(x);
// 别忘了在 map 中添加 key 的映射
map.put(key, x);
}
// 删除某一个 key
private void deleteKey(int key) {
Node x = map.get(key);
// 从链表中删除
cache.remove(x);
// 从 map 中删除
map.remove(key);
}
// 删除最久未使用的元素
private void removeLeastRecently() {
// 链表头部的第一个元素就是最久未使用的
Node deletedNode = cache.removeFirst();
// 同时别忘了从 map 中删除它的 key
int deletedKey = deletedNode.key;
map.remove(deletedKey);
}
}
上述方法就是简单的操作封装,调用这些函数可以避免直接操作 cache 链表和 map 哈希表,下面我先来实现 LRU 算法的 get 方法:
class LRUCache {
// 为了节约篇幅,省略上文给出的代码部分...
public int get(int key) {
if (!map.containsKey(key)) {
return -1;
}
// 将该数据提升为最近使用的
makeRecently(key);
return map.get(key).val;
}
}
put 方法稍微复杂一些,我们先来画个图搞清楚它的逻辑:
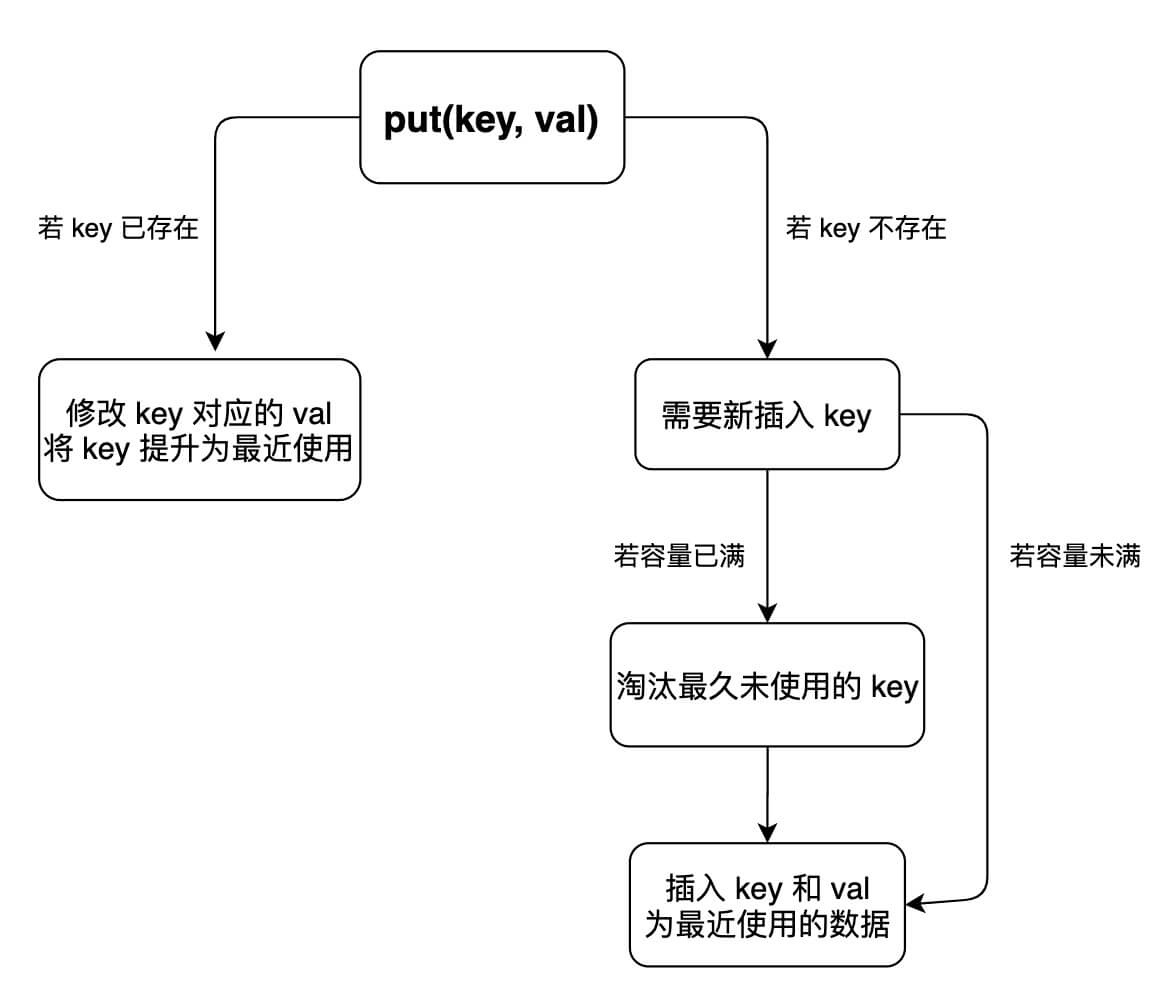
这样我们可以轻松写出 put 方法的代码:
class LRUCache {
// 为了节约篇幅,省略上文给出的代码部分...
public void put(int key, int val) {
if (map.containsKey(key)) {
// 删除旧的数据
deleteKey(key);
// 新插入的数据为最近使用的数据
addRecently(key, val);
return;
}
if (cap == cache.size()) {
// 删除最久未使用的元素
removeLeastRecently();
}
// 添加为最近使用的元素
addRecently(key, val);
}
}
二叉堆详解实现优先队列
简化版优先级队列
我们实现的这个简化版优先级队列有如下限制:
- 不支持泛型,仅支持存储整数类型的元素。
- 不考虑扩容的问题,队列的容量在创建时固定,假设插入的元素数量不会超过这个容量。
- 底层仅实现一个小顶堆(即根节点是整个堆中的最小值),不支持自定义比较器。
基于上面这些限制,这个简化版优先级队列的 API 如下:
class SimpleMinPQ {
// 创建一个容量为 capacity 的优先级队列
public SimpleMinPQ(int capacity);
// 返回队列中的元素个数
public int size();
// 向队列中插入一个元素
public void push(int x);
// 返回队列中的最小元素(堆顶元素)
public int peek();
// 删除并返回队列中的最小元素(堆顶元素)
public int pop();
}
难点分析
二叉堆的难点在于 你在插入或删除元素时,还要保持堆的性质。
增:push方法插入元素
核心步骤
以小顶堆为例,向小顶堆中插入新元素遵循两个步骤:
1、先把新元素追加到二叉树底层的最右侧,保持完全二叉树的结构。此时该元素的父节点可能比它大,不满足小顶堆的性质。
2、为了恢复小顶堆的性质,需要将这个新元素不断上浮(
swim),直到它的父节点比它小为止,或者到达根节点。此时整个二叉树就满足小顶堆的性质了。
删:pop方法删除元素
核心步骤
以小顶堆为例,删除小顶堆的堆顶元素遵循两个步骤:
1、先把堆顶元素删除,把二叉树底层的最右侧元素摘除并移动到堆顶,保持完全二叉树的结构。此时堆顶元素可能比它的子节点大,不满足小顶堆的性质。
2、为了恢复小顶堆的性质,需要将这个新的堆顶元素不断下沉(
sink),直到它的子节点比它小为止,或者到达叶子节点。此时整个二叉树就满足小顶堆的性质了。
查:peek方法查看堆顶元素
直接返回根节点的值就行了
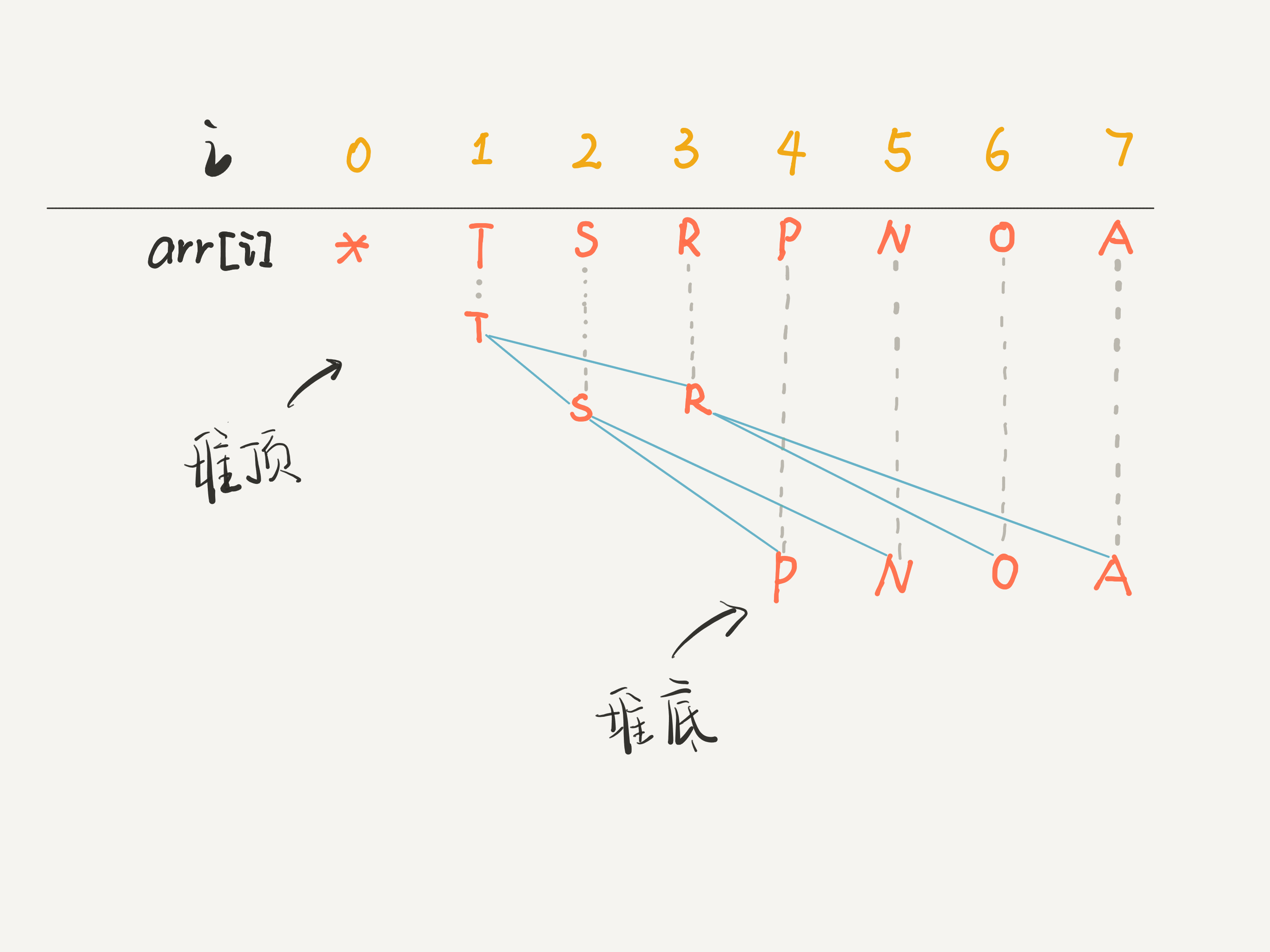
在数组上模拟二叉树
实际上,我们在代码实现的时候,不会用类似 HeapNode 的节点类来实现,而是用数组来模拟二叉树结构。
用数组模拟二叉树的原因
第一个原因是前面介绍 [数组] 和 [链表] 时说到的,链表节点需要一个额外的指针存储相邻节点的地址,所以相对数组,链表的内存消耗会大一些。我们这里的
HeapNode类也是链式存储的例子,和链表节点类似,需要额外的指针存储父节点和子节点的地址。第二个原因,也是最主要的原因,是时间复杂度的问题。仔细想一下前面我给你展示的
push和pop方法的操作过程,它们的第一步是什么?是不是要找到二叉树最底层的最右侧元素?因为上面举的场景是我们自己构造的,可以直接用操作
left, right指针的方式把目标节点拿到。但你想想,正常情况下你如何拿到二叉树的底层最右侧节点?你需要层序遍历或递归遍历二叉树,时间复杂度是O(N),进而导致push和pop方法的时间复杂度退化到O(N),这显然是不可接受的。如果用数组来模拟二叉树,就可以完美解决这个问题,在
O(1)时间内找到二叉树的底层最右侧节点。
完全二叉树是关键
想要用数组模拟二叉树,前提是这个二叉树必须是完全二叉树。
由于完全二叉树上的元素都是紧凑排列的,我们可以用数组来存储,看这幅图就明白了:
在这个数组中,索引 0 空着不用,就可以根据任意节点的索引计算出父节点或左右子节点的索引:
parent = node / 2 left = node * 2 right = node * 2 + 1我们直接在数组的末尾追加元素,就相当于在完全二叉树的最后一层从左到右依次填充元素;数组中最后一个元素,就是完全二叉树的底层最右侧的元素,完美契合我们实现二叉堆的场景。
代码实现
class SimpleMinPQ {
private:
int* heap;
int size;
public:
SimpleMinPQ(int capacity) {
// 索引 0 空着不用,所以多分配一个空间
heap = new int[capacity + 1];
size = 0;
}
int sizeFunc() {
return size;
}
// 父节点的索引
int parent(int node) {
return node / 2;
}
// 左子节点的索引
int left(int node) {
return node * 2;
}
// 右子节点的索引
int right(int node) {
return node * 2 + 1;
}
// 交换数组的两个元素
void swap(int i, int j) {
int temp = heap[i];
heap[i] = heap[j];
heap[j] = temp;
}
// 查,返回堆顶元素,时间复杂度 O(1)
int peek() {
// 索引 0 空着不用,所以堆顶元素是索引 1
return heap[1];
}
// 增,向堆中插入一个元素,时间复杂度 O(logN)
void push(int x) {
// 把新元素放到最后
heap[++size] = x;
// 然后上浮到正确位置
swim(size);
}
// 删,删除堆顶元素,时间复杂度 O(logN)
virtual int pop() {
int res = heap[1];
// 把堆底元素放到堆顶
heap[1] = heap[size--];
// 然后下沉到正确位置
sink(1);
return res;
}
// 上浮操作,时间复杂度是树高 O(logN)
void swim(int x) {
while (x > 1 && heap[parent(x)] > heap[x]) {
swap(parent(x), x);
x = parent(x);
}
}
// 下沉操作,时间复杂度是树高 O(logN)
void sink(int x) {
while (left(x) <= size || right(x) <= size) {
int min = x;
if (left(x) <= size && heap[left(x)] < heap[min]) {
min = left(x);
}
if (right(x) <= size && heap[right(x)] < heap[min]) {
min = right(x);
}
if (min == x) {
break;
}
swap(x, min);
x = min;
}
}
};
设计朋友圈时间线功能
题目及应用场景
Twitter 和微博功能差不多,主要要实现这样几个 API:
class Twitter {
public:
// user 发表一条 tweet 动态
void postTweet(int userId, int tweetId) {}
// 返回该 user 关注的人(包括他自己)最近的动态 id
// 最多 10 条,而且这些动态必须按从新到旧的时间线顺序排列
std::vector<int> getNewsFeed(int userId) {}
// follower 关注 followee,如果 Id 不存在则新建
void follow(int followerId, int followeeId) {}
// follower 取关 followee,如果 Id 不存在则什么都不做
void unfollow(int followerId, int followeeId) {}
};
举个具体的例子,方便大家理解 API 的具体用法:
Twitter twitter;
twitter.postTweet(1, 5);
// 用户 1 发送了一条新推文 5
twitter.getNewsFeed(1);
// return [5],因为自己是关注自己的
twitter.follow(1, 2);
// 用户 1 关注了用户 2
twitter.postTweet(2, 6);
// 用户2发送了一个新推文 (id = 6)
twitter.getNewsFeed(1);
// return [6, 5]
// 解释:用户 1 关注了自己和用户 2,所以返回他们的最近推文
// 而且 6 必须在 5 之前,因为 6 是最近发送的
twitter.unfollow(1, 2);
// 用户 1 取消关注了用户 2
twitter.getNewsFeed(1);
// return [5]
这几个 API 中大部分都很好实现,最核心的功能难点应该是 getNewsFeed,因为返回的结果必须在时间上有序,但问题是用户的关注是动态变化的,怎么办?
这里就涉及到算法了:如果我们把每个用户各自的推文存储在链表里,每个链表节点存储文章 id 和一个时间戳 time(记录发帖时间以便比较),而且这个链表是按 time 有序的,那么如果某个用户关注了 k 个用户,我们就可以用合并 k 个有序链表的算法合并出有序的推文列表,正确地 getNewsFeed 了!
面向对象设计
根据刚才的分析,我们需要一个 User 类,储存 user 信息,还需要一个 Tweet 类,储存推文信息,并且要作为链表的节点。所以我们先搭建一下整体的框架:
class Twitter {
private:
static int timestamp; // 时间戳
class Tweet {}; // 推文类
class User {}; // 用户类
public:
// API 方法
void postTweet(int userId, int tweetId) {} // 发布推文
std::vector<int> getNewsFeed(int userId) {} // 获取用户的新闻feed
void follow(int followerId, int followeeId) {} // 关注用户
void unfollow(int followerId, int followeeId) {} // 取消关注用户
};
// Initialize static member variable
int Twitter::timestamp = 0;
之所以要把 Tweet 和 User 类放到 Twitter 类里面,是因为 Tweet 类必须要用到一个全局时间戳 timestamp,而 User 类又需要用到 Tweet 类记录用户发送的推文,所以它们都作为内部类。不过为了清晰和简洁,下文会把每个内部类和 API 方法单独拿出来实现。
Tweet类的实现
根据前面的分析,Tweet 类很容易实现:每个 Tweet 实例需要记录自己的 tweetId 和发表时间 time,而且作为链表节点,要有一个指向下一个节点的 next 指针。
class Tweet {
private:
int id;
int time;
Tweet* next;
public:
// 需要传入推文内容(id)和发文时间
Tweet(int id, int time) {
this->id = id;
this->time = time;
this->next = nullptr;
}
};

User类的实现
我们根据实际场景想一想,一个用户需要存储的信息有 userId,关注列表,以及该用户发过的推文列表。其中关注列表应该用集合(Hash Set)这种数据结构来存,因为不能重复,而且需要快速查找;推文列表应该由链表这种数据结构储存,以便于进行有序合并的操作。画个图理解一下:
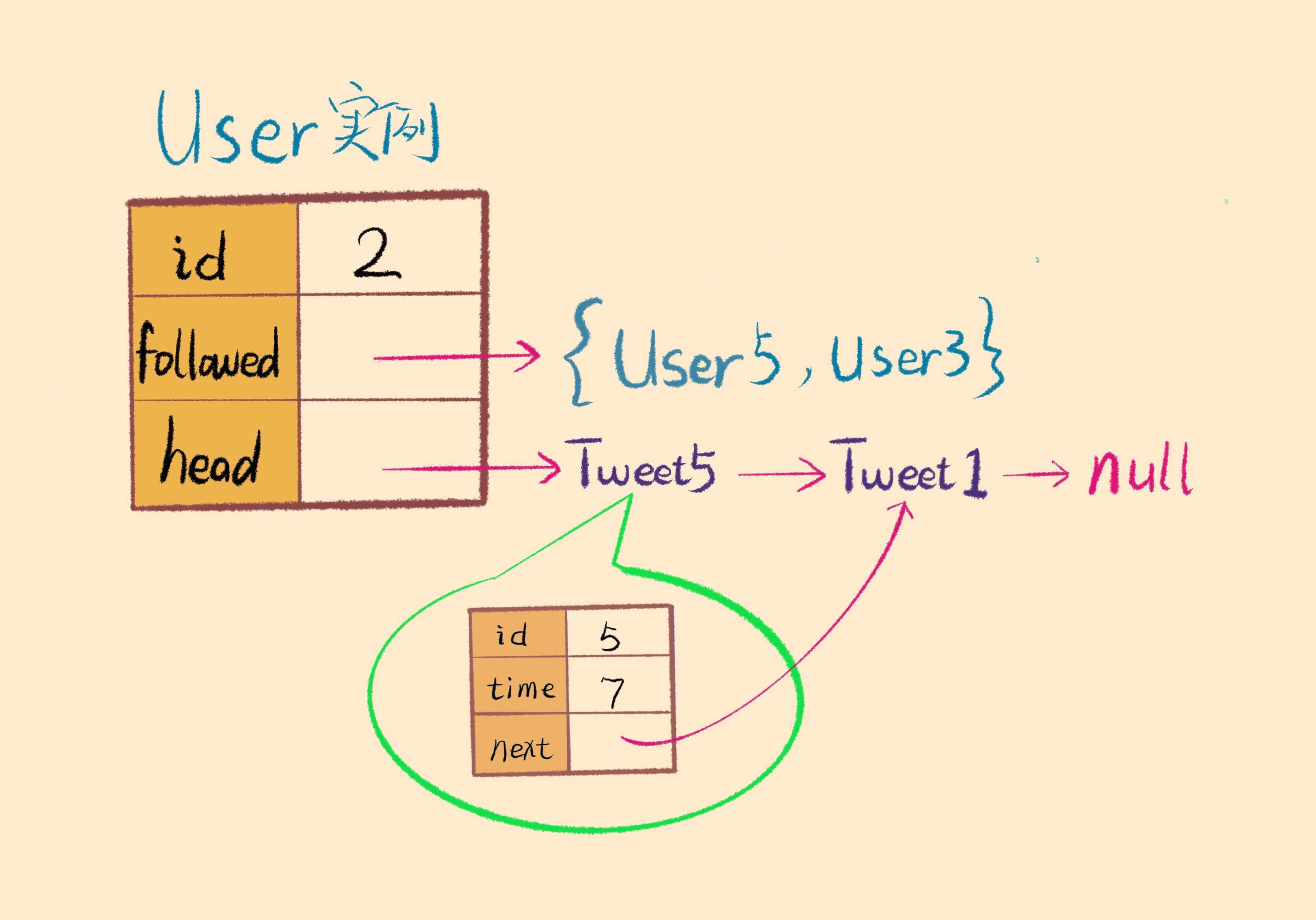
除此之外,根据面向对象的设计原则,「关注」「取关」和「发文」应该是 User 的行为,况且关注列表和推文列表也存储在 User 类中,所以我们也应该给 User 添加 follow,unfollow 和 post 这几个方法:
// static int timestamp = 0
class User {
private:
int id;
set<int> followed;
// 用户发表的推文链表头结点
Tweet* head;
public:
User(int userId) {
this->id = userId;
this->head = nullptr;
// 关注一下自己
follow(id);
}
void follow(int userId) {
followed.insert(userId);
}
void unfollow(int userId) {
// 不可以取关自己
if (userId != this->id)
followed.erase(userId);
}
void post(int tweetId) {
Tweet* twt = new Tweet(tweetId, timestamp);
timestamp++;
// 将新建的推文插入链表头
// 越靠前的推文 time 值越大
twt->next = head;
head = twt;
}
};
API方法实现
class Twitter {
private:
static int timestamp;
class Tweet {...};
class User {...};
// 我们需要一个映射将 userId 和 User 对象对应起来
unordered_map<int, User> userMap;
public:
// user 发表一条 tweet 动态
void postTweet(int userId, int tweetId) {
// 若 userId 不存在,则新建
if (userMap.find(userId) == userMap.end())
userMap[userId] = User(userId);
User& u = userMap[userId];
u.post(tweetId);
}
// follower 关注 followee
void follow(int followerId, int followeeId) {
// 若 follower 不存在,则新建
if(userMap.find(followerId) == userMap.end()){
User u = User(followerId);
userMap[followerId] = u;
}
// 若 followee 不存在,则新建
if(userMap.find(followeeId) == userMap.end()){
User u = User(followeeId);
userMap[followeeId] = u;
}
userMap[followerId].follow(followeeId);
}
// follower 取关 followee,如果 Id 不存在则什么都不做
void unfollow(int followerId, int followeeId) {
if (userMap.find(followerId) != userMap.end()) {
User& flwer = userMap[followerId];
flwer.unfollow(followeeId);
}
}
// 返回该 user 关注的人(包括他自己)最近的动态 id
// 最多 10 条,而且这些动态必须按从新到旧的时间线顺序排列
vector<int> getNewsFeed(int userId) {
// 需要理解算法,见下文
}
};
int Twitter::timestamp = 0;
算法设计
实现合并 k 个有序链表的算法需要用到优先级队列(Priority Queue),这种数据结构是二叉堆最重要的应用。你可以理解为它可以对插入的元素自动排序,乱序的元素插入其中就被放到了正确的位置,可以按照从小到大(或从大到小)有序地取出元素。
借助这种牛逼的数据结构支持,我们就很容易实现这个核心功能了。注意我们把优先级队列设为按 time 属性从大到小降序排列,因为 time 越大意味着时间越近,应该排在前面:
class Twitter {
public:
// 为了节约篇幅,省略上文给出的代码部分...
vector<int> getNewsFeed(int userId) {
vector<int> res;
// 不在 userMap 中就直接返回
if (userMap.count(userId) == 0) return res;
// 关注列表的用户 Id
set<int> users = userMap[userId].followed;
// 自动通过 time 属性从大到小排序,容量为 users 的大小
priority_queue<Tweet*> pq;
// 先将所有链表头节点插入优先级队列
for (int id : users) {
Tweet* twt = userMap[id].head;
// 排除掉 null 的情况
if (twt == NULL) continue;
pq.push(twt);
}
while (!pq.empty()) {
// 最多返回 10 条就够了
if (res.size() == 10) break;
// 弹出 time 值最大的(最近发表的)
Tweet* twt = pq.top(); pq.pop();
res.push_back(twt->id);
// 将下一篇 Tweet 插入进行排序
if (twt->next != NULL)
pq.push(twt->next);
}
return res;
}
};
这个过程是这样的,下面是我制作的一个 GIF 图描述合并链表的过程。假设有三个 Tweet 链表按 time 属性降序排列,我们把他们降序合并添加到 res 中。注意图中链表节点中的数字是 time 属性,不是 id 属性:
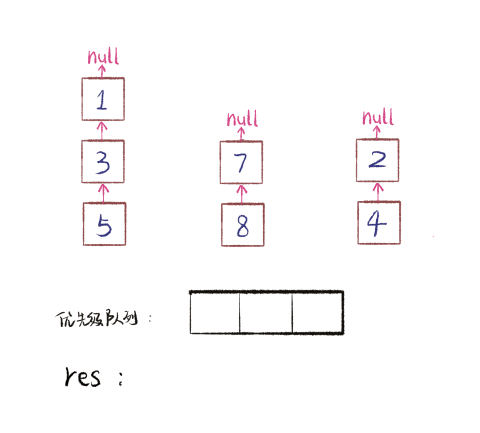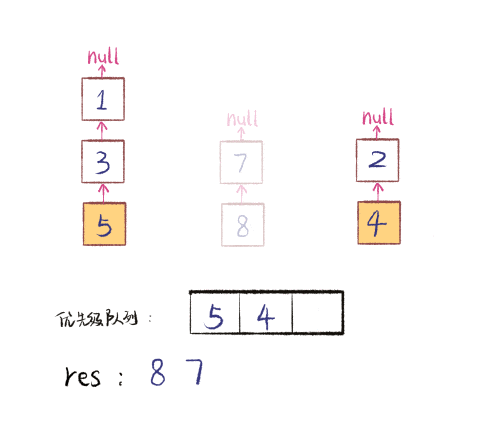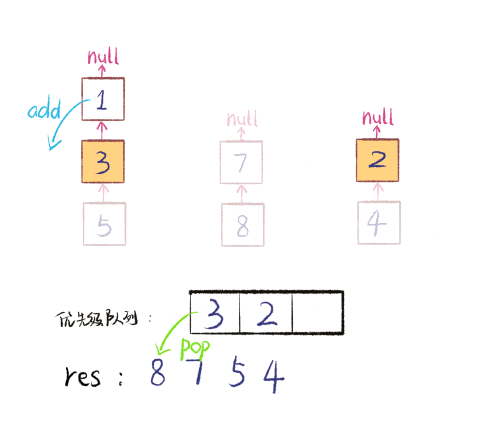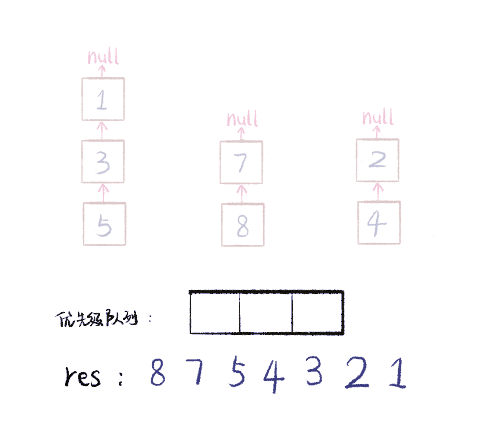
图算法
图遍历算法
各种数据结构被发明出来无非就是为了遍历和访问,所以「遍历」是所有数据结构的基础。
图怎么遍历?参考多叉树,多叉树的 DFS 遍历框架如下:
/* 多叉树遍历框架 */
void traverse(TreeNode* root) {
if (root == nullptr) return;
// 前序位置
for (TreeNode* child : root->children) {
traverse(child);
}
// 后序位置
}
图和多叉树最大的区别是,图是可能包含环的,你从图的某一个节点开始遍历,有可能走了一圈又回到这个节点,而树不会出现这种情况,从某个节点出发必然走到叶子节点,绝不可能回到它自身。
所以,如果图包含环,遍历框架就要一个 visited 数组进行辅助:
// 记录被遍历过的节点
vector<bool> visited;
// 记录从起点到当前节点的路径
vector<bool> onPath;
/* 图遍历框架 */
void traverse(Graph graph, int s) {
if (visited[s]) return;
// 经过节点 s,标记为已遍历
visited[s] = true;
// 做选择:标记节点 s 在路径上
onPath[s] = true;
for (int neighbor : graph.neighbors(s)) {
traverse(graph, neighbor);
}
// 撤销选择:节点 s 离开路径
onPath[s] = false;
}
注意 visited 数组和 onPath 数组的区别,因为二叉树算是特殊的图,所以用遍历二叉树的过程来理解下这两个数组的区别:
上述 GIF 描述了递归遍历二叉树的过程,在 visited 中被标记为 true 的节点用灰色表示,在 onPath 中被标记为 true 的节点用绿色表示,类比贪吃蛇游戏,visited 记录蛇经过过的格子,而 onPath 仅仅记录蛇身。在图的遍历过程中,onPath 用于判断是否成环,类比当贪吃蛇自己咬到自己(成环)的场景,这下你可以理解它们二者的区别了吧。
题目实践
题目输入一幅有向无环图,这个图包含 n 个节点,标号为 0, 1, 2,..., n - 1,请你计算所有从节点 0 到节点 n - 1 的路径。
输入的这个 graph 其实就是「邻接表」表示的一幅图,graph[i] 存储这节点 i 的所有邻居节点。
比如输入 graph = [[1,2],[3],[3],[]],就代表下面这幅图:
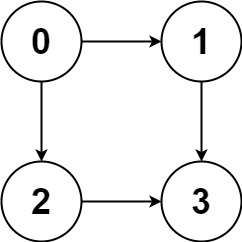
算法应该返回 [[0,1,3],[0,2,3]],即 0 到 3 的所有路径。
解法很简单,以 0 为起点遍历图,同时记录遍历过的路径,当遍历到终点时将路径记录下来即可。
既然输入的图是无环的,我们就不需要 visited 数组辅助了,直接套用图的遍历框架:
class Solution {
// 记录所有路径
vector<vector<int>> res;
public:
vector<vector<int>> allPathsSourceTarget(vector<vector<int>>& graph) {
// 维护递归过程中经过的路径
vector<int> path;
traverse(graph, 0, path);
return res;
}
/* 图的遍历框架 */
void traverse(vector<vector<int>>& graph, int s, vector<int>& path) {
// 添加节点 s 到路径
path.push_back(s);
int n = graph.size();
if (s == n - 1) {
// 到达终点
res.push_back(path);
// 可以在这直接 return,但要正确维护 path
// path.pop_back();
// return;
// 不 return 也可以,因为图中不包含环,不会出现无限递归
}
// 递归每个相邻节点
for (int v : graph[s]) {
traverse(graph, v, path);
}
// 从路径移出节点 s
path.pop_back();
}
};
环检测及拓扑排序算法
两个图论算法:有向图的环检测、拓扑排序算法。
这两个算法既可以用 DFS 思路解决,也可以用 BFS 思路解决,相对而言 BFS 解法从代码实现上看更简洁一些,但 DFS 解法有助于进一步理解递归遍历数据结构的奥义,所以本文中先讲 DFS 遍历的思路,再讲 BFS 遍历的思路。
环检测算法(DFS版本)
题目
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
- 例如,先修课程对
[0, 1]表示:想要学习课程0,你需要先完成课程1。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
示例 1:
输入:numCourses = 2, prerequisites = [[1,0]]
输出:true
解释:总共有 2 门课程。学习课程 1 之前,你需要完成课程 0 。这是可能的。
示例 2:
输入:numCourses = 2, prerequisites = [[1,0],[0,1]]
输出:false
解释:总共有 2 门课程。学习课程 1 之前,你需要先完成课程 0 ;并且学习课程 0 之前,你还应先完成课程 1 。这是不可能的。
提示:
1 <= numCourses <= 20000 <= prerequisites.length <= 5000prerequisites[i].length == 20 <= ai, bi < numCoursesprerequisites[i]中的所有课程对 互不相同
思路
什么时候无法修完所有课程?当存在循环依赖的时候。
其实这种场景在现实生活中也十分常见,比如我们写代码 import 包也是一个例子,必须合理设计代码目录结构,否则会出现循环依赖,编译器会报错,所以编译器实际上也使用了类似算法来判断你的代码是否能够成功编译。
看到依赖问题,首先想到的就是把问题转化成「有向图」这种数据结构,只要图中存在环,那就说明存在循环依赖。
具体来说,我们首先可以把课程看成「有向图」中的节点,节点编号分别是 0, 1, ..., numCourses-1,把课程之间的依赖关系看做节点之间的有向边。
比如说必须修完课程 1 才能去修课程 3,那么就有一条有向边从节点 1 指向 3。
所以我们可以根据题目输入的 prerequisites 数组生成一幅类似这样的图:
如果发现这幅有向图中存在环,那就说明课程之间存在循环依赖,肯定没办法全部上完;反之,如果没有环,那么肯定能上完全部课程。
好,那么想解决这个问题,首先我们要把题目的输入转化成一幅有向图,然后再判断图中是否存在环。
怎么判断图中有没有环呢?
先来思考如何遍历这幅图,只要会遍历,就可以判断图中是否存在环了。
注意图中并不是所有节点都相连,所以要用一个 for 循环将所有节点都作为起点调用一次 DFS 搜索算法。
vector<bool> onPath;
vector<bool> visited;
bool hasCycle = false;
void traverse(vector<int>* graph, int s) {
if (onPath[s]) {
// 发现环!!!
hasCycle = true;
}
if (visited[s] || hasCycle) {
return;
}
// 将节点 s 标记为已遍历
visited[s] = true;
// 开始遍历节点 s
onPath[s] = true;
for (int t : graph[s]) {
traverse(graph, t);
}
// 节点 s 遍历完成
onPath[s] = false;
}
这其实就是 DFS 算法,在进入节点 s 的时候将 onPath[s] 标记为 true,离开时标记回 false,如果发现 onPath[s] 已经被标记,说明出现了环。
这样,就可以在遍历图的过程中顺便判断是否存在环了,完整代码如下:
class Solution {
public:
// 记录一次递归堆栈中的节点
vector<bool> onPath;
// 记录遍历过的节点,防止走回头路
vector<bool> visited;
// 记录图中是否有环
bool hasCycle = false;
bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {
vector<vector<int>> graph = buildGraph(numCourses, prerequisites);
visited.resize(numCourses, false);
onPath.resize(numCourses, false);
for (int i = 0; i < numCourses; i++) {
// 遍历图中的所有节点
traverse(graph, i);
}
// 只要没有循环依赖可以完成所有课程
return !hasCycle;
}
void traverse(vector<vector<int>>& graph, int s) {
if (onPath[s]) {
// 出现环
hasCycle = true;
}
if (visited[s] || hasCycle) {
// 如果已经找到了环,也不用再遍历了
return;
}
// 前序代码位置
visited[s] = true;
onPath[s] = true;
for (int t : graph[s]) {
traverse(graph, t);
}
// 后序代码位置
onPath[s] = false;
}
vector<vector<int>> buildGraph(int numCourses, vector<vector<int>>& prerequisites) {
// 图中共有 numCourses 个节点
auto* graph = new vector<int>[numCourses];
for (int i = 0; i < numCourses; i++) {
graph[i] = vector<int>();
}
for (auto& edge : prerequisites) {
int from = edge[1], to = edge[0];
// 添加一条从 from 指向 to 的有向边
// 边的方向是「被依赖」关系,即修完课程 from 才能修课程 to
graph[from].push_back(to);
}
return graph;
}
};
这道题就解决了,核心就是判断一幅有向图中是否存在环。
不过如果出题人继续提问,让你不仅要判断是否存在环,还要返回这个环具体有哪些节点,怎么办?
你可能说,onPath 里面为 true 的索引,不就是组成环的节点编号吗?
不是的,假设从节点 0 开始遍历,下图中绿色的节点是递归的路径,它们在 onPath 中的值都是 true,但显然成环的节点只是其中的一部分:
最简单直接的解法是,在
boolean[] onPath数组的基础上,我们再使用一个Stack<Integer> path栈,把遍历过程中经过的节点顺序也保存下来。比如按照上图绿色的遍历顺序,
path从栈底到栈顶的元素就是[0,4,5,9,8,7,6]。此时又一次遇到了节点5,那么就可以知道[5,9,8,7,6]这部分是环了。
拓扑排序算法(DFS版本)
题目
现在你总共有 numCourses 门课需要选,记为 0 到 numCourses - 1。给你一个数组 prerequisites ,其中 prerequisites[i] = [ai, bi] ,表示在选修课程 ai 前 必须 先选修 bi 。
- 例如,想要学习课程
0,你需要先完成课程1,我们用一个匹配来表示:[0,1]。
返回你为了学完所有课程所安排的学习顺序。可能会有多个正确的顺序,你只要返回 任意一种 就可以了。如果不可能完成所有课程,返回 一个空数组 。
示例 1:
输入:numCourses = 2, prerequisites = [[1,0]]
输出:[0,1]
解释:总共有 2 门课程。要学习课程 1,你需要先完成课程 0。因此,正确的课程顺序为 [0,1] 。
示例 2:
输入:numCourses = 4, prerequisites = [[1,0],[2,0],[3,1],[3,2]]
输出:[0,2,1,3]
解释:总共有 4 门课程。要学习课程 3,你应该先完成课程 1 和课程 2。并且课程 1 和课程 2 都应该排在课程 0 之后。
因此,一个正确的课程顺序是 [0,1,2,3] 。另一个正确的排序是 [0,2,1,3] 。
示例 3:
输入:numCourses = 1, prerequisites = []
输出:[0]
提示:
1 <= numCourses <= 20000 <= prerequisites.length <= numCourses * (numCourses - 1)prerequisites[i].length == 20 <= ai, bi < numCoursesai != bi- 所有
[ai, bi]互不相同
思路
这道题就是上道题的进阶版,不是仅仅让你判断是否可以完成所有课程,而是进一步让你返回一个合理的上课顺序,保证开始修每个课程时,前置的课程都已经修完。
这里我先说一下拓扑排序(Topological Sorting)这个名词,网上搜出来的定义很数学,这里干脆用百度百科的一幅图来让你直观地感受下:
直观地说就是,让你把一幅图「拉平」,而且这个「拉平」的图里面,所有箭头方向都是一致的,比如上图所有箭头都是朝右的。
很显然,如果一幅有向图中存在环,是无法进行拓扑排序的,因为肯定做不到所有箭头方向一致;反过来,如果一幅图是「有向无环图」,那么一定可以进行拓扑排序。
但是我们这道题和拓扑排序有什么关系呢?
其实也不难看出来,如果把课程抽象成节点,课程之间的依赖关系抽象成有向边,那么这幅图的拓扑排序结果就是上课顺序。
首先,我们先判断一下题目输入的课程依赖是否成环,成环的话是无法进行拓扑排序的,所以我们可以复用上一道题的主函数:
vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites) {
if (!canFinish(numCourses, prerequisites)) {
// 不可能完成所有课程
return vector<int>();
}
// ...
}
那么关键问题来了,如何进行拓扑排序?其实特别简单,将后序遍历的结果进行反转,就是拓扑排序的结果。
class Solution {
public:
// 记录后序遍历结果
vector<int> postorder;
// 记录是否存在环
bool hasCycle = false;
vector<bool> visited, onPath;
// 主函数
vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites) {
vector<vector<int>> graph = buildGraph(numCourses, prerequisites);
visited = vector<bool>(numCourses, false);
onPath = vector<bool>(numCourses, false);
// 遍历图
for (int i = 0; i < numCourses; i++) {
traverse(graph, i);
}
// 有环图无法进行拓扑排序
if (hasCycle) {
return {};
}
// 逆后序遍历结果即为拓扑排序结果
reverse(postorder.begin(), postorder.end());
vector<int> res(numCourses);
for (int i = 0; i < numCourses; i++) {
res[i] = postorder[i];
}
return res;
}
// 图遍历函数
void traverse(vector<vector<int>>& graph, int s) {
if (onPath[s]) {
// 发现环
hasCycle = true;
}
if (visited[s] || hasCycle) {
return;
}
// 前序遍历位置
onPath[s] = true;
visited[s] = true;
for (int t : graph[s]) {
traverse(graph, t);
}
// 后序遍历位置
postorder.push_back(s);
onPath[s] = false;
}
// 建图函数
vector<vector<int>> buildGraph(int numCourses, vector<vector<int>>& prerequisites) {
// 代码见前文。
}
};
代码虽然看起来多,但是逻辑应该是很清楚的,只要图中无环,那么我们就调用 traverse 函数对图进行 DFS 遍历,记录后序遍历结果,最后把后序遍历结果反转,作为最终的答案。
那么为什么后序遍历的反转结果就是拓扑排序呢?
我这里也避免数学证明,用一个直观地例子来解释,我们就说二叉树,这是我们说过很多次的二叉树遍历框架.
二叉树的后序遍历是什么时候?遍历完左右子树之后才会执行后序遍历位置的代码。换句话说,当左右子树的节点都被装到结果列表里面了,根节点才会被装进去。
后序遍历的这一特点很重要,之所以拓扑排序的基础是后序遍历,是因为一个任务必须等到它依赖的所有任务都完成之后才能开始开始执行。
你把二叉树理解成一幅有向图,边的方向是由父节点指向子节点,那么就是下图这样:

对于标准的后序遍历结果,根节点出现在最后,只要把遍历结果反过来,就是拓扑排序结果:
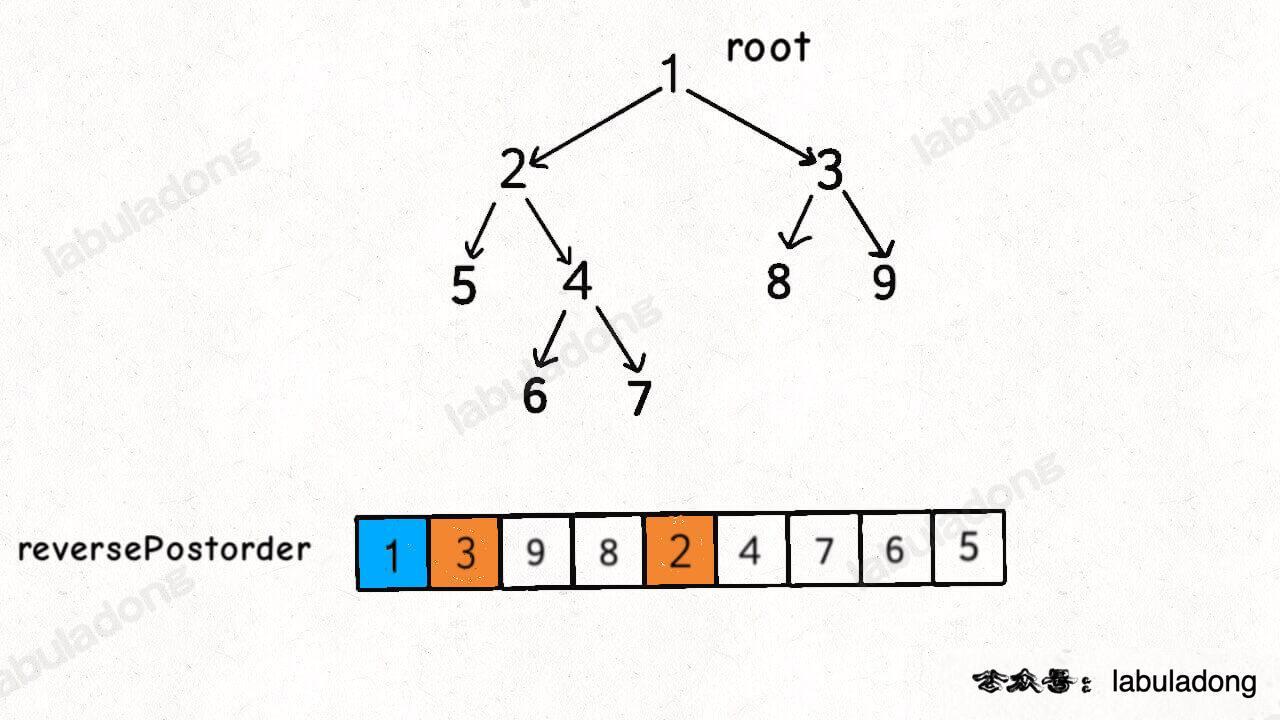
环检测算法(BFS版本)
class Solution {
public:
bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {
// 建图,有向边代表「被依赖」关系
vector<vector<int>> graph = buildGraph(numCourses, prerequisites);
// 构建入度数组
vector<int> indegree(numCourses, 0);
for (auto &edge : prerequisites) {
int from = edge[1], to = edge[0];
// 节点 to 的入度加一
indegree[to]++;
}
// 根据入度初始化队列中的节点
queue<int> q;
for (int i = 0; i < numCourses; i++) {
if (indegree[i] == 0) {
// 节点 i 没有入度,即没有依赖的节点
// 可以作为拓扑排序的起点,加入队列
q.push(i);
}
}
// 记录遍历的节点个数
int count = 0;
// 开始执行 BFS 循环
while (!q.empty()) {
// 弹出节点 cur,并将它指向的节点的入度减一
int cur = q.front();
q.pop();
count++;
for (int next : graph[cur]) {
indegree[next]--;
if (indegree[next] == 0) {
// 如果入度变为 0,说明 next 依赖的节点都已被遍历
q.push(next);
}
}
}
// 如果所有节点都被遍历过,说明不成环
return count == numCourses;
}
// 建图函数
vector<vector<int>> buildGraph(int n, vector<vector<int>>& edges) {
// 见前文
}
};
总结下这段 BFS 算法的思路:
- 构建邻接表,和之前一样,边的方向表示「被依赖」关系。
- 构建一个
indegree数组记录每个节点的入度,即indegree[i]记录节点i的入度。 - 对 BFS 队列进行初始化,将入度为 0 的节点首先装入队列。
- 开始执行 BFS 循环,不断弹出队列中的节点,减少相邻节点的入度,并将入度变为 0 的节点加入队列。
- 如果最终所有节点都被遍历过(
count等于节点数),则说明不存在环,反之则说明存在环。
拓扑排序算法(BFS版本)
class Solution
{
public:
vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites)
{
// 建图,和环检测算法相同
vector<vector<int>> graph = buildGraph(numCourses, prerequisites);
// 计算入度,和环检测算法相同
vector<int> indegree(numCourses);
for (vector<int> edge : prerequisites)
{
int from = edge[1], to = edge[0];
indegree[to]++;
}
// 根据入度初始化队列中的节点,和环检测算法相同
queue<int> q;
for (int i = 0; i < numCourses; i++)
{
if (indegree[i] == 0)
{
q.push(i);
}
}
// 记录拓扑排序结果
vector<int> res(numCourses);
// 记录遍历节点的顺序(索引)
int count = 0;
// 开始执行 BFS 算法
while (!q.empty())
{
int cur = q.front();
q.pop();
// 弹出节点的顺序即为拓扑排序结果
res[count] = cur;
count++;
for (int next : graph[cur])
{
indegree[next]--;
if (indegree[next] == 0)
{
q.push(next);
}
}
}
if (count != numCourses)
{
// 存在环,拓扑排序不存在
return {};
}
return res;
}
private:
vector<vector<int>> buildGraph(int n, vector<vector<int>>& edges)
{
// 见前文
}
};
名流问题
什么是名流问题
给你 n 个人的社交关系(你知道任意两个人之间是否认识),然后请你找出这些人中的「名人」。
所谓「名人」有两个条件:
- 所有其他人都认识「名人」。
- 「名人」不认识任何其他人。
这是一个图相关的算法问题,社交关系嘛,本质上就可以抽象成一幅图。
如果把每个人看做图中的节点,「认识」这种关系看做是节点之间的有向边,那么名人就是这幅图中一个特殊的节点:
这个节点没有一条指向其他节点的有向边;且其他所有节点都有一条指向这个节点的有向边。
或者说的专业一点,名人节点的出度为 0,入度为 n - 1。
对于名人问题,显然会经常需要判断两个人之间是否认识,也就是两个节点是否相邻,所以我们可以用邻接矩阵来表示人和人之间的社交关系。
那么,把名流问题描述成算法的形式就是这样的:
给你输入一个大小为 n x n 的二维数组(邻接矩阵) graph 表示一幅有 n 个节点的图,每个人都是图中的一个节点,编号为 0 到 n - 1。
如果 graph[i][j] == 1 代表第 i 个人认识第 j 个人,如果 graph[i][j] == 0 代表第 i 个人不认识第 j 个人。
有了这幅图表示人与人之间的关系,请你计算,这 n 个人中,是否存在「名人」?
如果存在,算法返回这个名人的编号,如果不存在,算法返回 -1。
暴力解法
int findCelebrity(int n) {
for (int cand = 0; cand < n; cand++) {
int other;
for (other = 0; other < n; other++) {
if (cand == other) continue;
// 保证其他人都认识 cand,且 cand 不认识任何其他人
// 否则 cand 就不可能是名人
if (knows(cand, other) || !knows(other, cand)) {
break;
}
}
if (other == n) {
// 找到名人
return cand;
}
}
// 没有一个人符合名人特性
return -1;
}
cand 是候选人(candidate)的缩写,我们的暴力算法就是从头开始穷举,把每个人都视为候选人,判断是否符合「名人」的条件。
刚才也说了,knows 函数底层就是在访问一个二维的邻接矩阵,一次调用的时间复杂度是 O(1),所以这个暴力解法整体的最坏时间复杂度是 O(N^2)。
那么,是否有其他高明的办法来优化时间复杂度呢?其实是有优化空间的,你想想,我们现在最耗时的地方在哪里?
对于每一个候选人 cand,我们都要用一个内层 for 循环去判断这个 cand 到底符不符合「名人」的条件。
这个内层 for 循环看起来就蠢,虽然判断一个人「是名人」必须用一个 for 循环,但判断一个人「不是名人」就不用这么麻烦了。
因为「名人」的定义保证了「名人」的唯一性,所以我们可以利用排除法,先排除那些显然不是「名人」的人,从而避免 for 循环的嵌套,降低时间复杂度。
优化解法
只要观察任意两个候选人的关系,我一定能确定其中的一个人不是名人,把他排除。
至于另一个候选人是不是名人,只看两个人的关系肯定是不能确定的,但这不重要,重要的是排除掉一个必然不是名人的候选人,缩小了包围圈。
这是优化的核心,也是比较难理解的,所以我们先来说说为什么观察任意两个候选人的关系,就能排除掉一个。
两个人之间的关系可能是什么样的?
无非就是四种:你认识我我不认识你,我认识你你不认识我,咱俩互相认识,咱两互相不认识。
如果把人比作节点,红色的有向边表示不认识,绿色的有向边表示认识,那么两个人的关系无非是如下四种情况:
不妨认为这两个人的编号分别是 cand 和 other,然后我们逐一分析每种情况,看看怎么排除掉一个人。
- 对于情况一,
cand认识other,所以cand肯定不是名人,排除。因为名人不可能认识别人。 - 对于情况二,
other认识cand,所以other肯定不是名人,排除。 - 对于情况三,他俩互相认识,肯定都不是名人,可以随便排除一个。
- 对于情况四,他俩互不认识,肯定都不是名人,可以随便排除一个。因为名人应该被所有其他人认识。
综上,只要观察任意两个之间的关系,就至少能确定一个人不是名人,上述情况判断可以用如下代码表示:
if (knows(cand, other) || !knows(other, cand)) {
// cand 不可能是名人
}
else {
// other 不可能是名人
}
如果能够理解这一个特点,那么写出优化解法就简单了。
我们可以不断从候选人中选两个出来,然后排除掉一个,直到最后只剩下一个候选人,这时候再使用一个 for 循环判断这个候选人是否是货真价实的「名人」。
这个思路的完整代码如下:
int findCelebrity(int n) {
if (n == 1) return 0;
// 将所有候选人装进队列
queue<int> q;
for (int i = 0; i < n; i++) {
q.push(i);
}
// 一直排除,直到只剩下一个候选人停止循环
while (q.size() >= 2) {
// 每次取出两个候选人,排除一个
int cand = q.front(); q.pop();
int other = q.front(); q.pop();
if (knows(cand, other) || !knows(other, cand)) {
// cand 不可能是名人,排除,让 other 归队
q.push(other);
} else {
// other 不可能是名人,排除,让 cand 归队
q.push(cand);
}
}
// 现在排除得只剩一个候选人,判断他是否真的是名人
int cand = q.front(); q.pop();
for (int other = 0; other < n; other++) {
if (other == cand) {
continue;
}
// 保证其他人都认识 cand,且 cand 不认识任何其他人
if (!knows(other, cand) || knows(cand, other)) {
return -1;
}
}
// cand 是名人
return cand;
}
这个算法避免了嵌套 for 循环,时间复杂度降为 O(N) 了,不过引入了一个队列来存储候选人集合,使用了 O(N) 的空间复杂度。
是否可以进一步优化,把空间复杂度也优化掉?
最终解法
int findCelebrity(int n) {
// 先假设 cand 是名人
int cand = 0;
for (int other = 1; other < n; other++) {
if (!knows(other, cand) || knows(cand, other)) {
// cand 不可能是名人,排除
// 假设 other 是名人
cand = other;
} else {
// other 不可能是名人,排除
// 什么都不用做,继续假设 cand 是名人
}
}
// 现在的 cand 是排除的最后结果,但不能保证一定是名人
for (int other = 0; other < n; other++) {
if (cand == other) continue;
// 需要保证其他人都认识 cand,且 cand 不认识任何其他人
if (!knows(other, cand) || knows(cand, other)) {
return -1;
}
}
return cand;
}
我们之前的解法用到了 LinkedList 充当一个队列,用于存储候选人集合,而这个优化解法利用 other 和 cand 的交替变化,模拟了我们之前操作队列的过程,避免了使用额外的存储空间。
现在,解决名人问题的解法时间复杂度为 O(N),空间复杂度为 O(1),已经是最优解法了。